
![]()
![]()
Developing large language models requires substantial investments in time and GPU resources, translating directly into high costs. The larger the model, the more pronounced these challenges become.
Recently, Yandex has introduced a new solution: YaFSDP, an open-source tool that promises to revolutionize LLM training by significantly reducing GPU resource consumption and training time. In a pre-training scenario involving a model with 70 billion parameters, using YaFSDP can save the resources of approximately 150 GPUs. This translates to potential monthly savings of roughly $0.5 to $1.5 million, depending on the virtual GPU provider or platform.
Yandex has made YaFSDP publicly available on GitHub. ML engineers can leverage this tool to enhance the efficiency of their LLM training processes. By open-sourcing YaFSDP, Yandex aims to foster innovation and collaboration in the AI community, enabling developers to train models faster and cost-effectively.
The Challenge of Distributed LLM Training
Training LLMs across multiple GPUs involves complex operations that lead to inefficiencies and high memory consumption. One of the main issues is the need to send and receive massive amounts of data between GPUs. For instance, in a typical all_reduce operation, twice the amount of gradient data as there are network parameters must be communicated. In the case of a Llama 70B model, this means transferring 280 GB of data per iteration.
Furthermore, weights, gradients, and optimizer states are duplicated across GPUs, leading to an enormous memory load. The Llama 70B model and the Adam optimizer require over 1 TB of memory, far exceeding the typical 80 GB memory capacity of most GPUs. This redundancy severely slows down the training process and often makes it impractical to fit even moderately sized models into GPU memory.
Introducing YaFSDP
Yandex’s YaFSDP offers a highly effective solution to these challenges. By focusing on optimizing memory consumption and eliminating communication bottlenecks, YaFSDP enhances the efficiency of LLM training. It works by sharding layers instead of individual parameters, maintaining efficient communications and avoiding redundant operations. Additionally, YaFSDP pre-allocates buffers for all required data, ensuring that the Torch allocator does not introduce inefficiencies.
YaFSDP operates by utilizing two buffers for intermediate weights and gradients, with odd layers using one buffer and even layers using the other.

The weights from different layers are stored in the same memory. If the layers have the same structure, they will always be identical. It is crucial to ensure that when you need layer X, the buffer contains the weights for layer X. All parameters will be stored in the corresponding memory chunk within the buffer.

Memory Consumption
During training, the primary memory consumers are weights, gradients, optimizer states, buffers, and activations. YaFSDP significantly reduces memory consumption by optimizing how these elements are stored and accessed.
- Weights, Gradients, and Optimizer States: These depend on the number of processes, and their memory consumption tends to approach zero as the number of processes increases. By sharding these components across GPUs, YaFSDP minimizes duplication and thus reduces memory usage.
- Buffers consume a constant amount of memory and store intermediate values during computations.
- Activations depend on the model size and the number of tokens processed per GPU. YaFSDP leverages activation checkpointing to manage memory usage efficiently.
Activation Checkpointing
Activation checkpointing is a technique that stores only necessary activations during the forward pass and recomputes them during the backward pass. This reduces the memory footprint significantly, as only essential data is stored. For example, in training a Llama 2 70B model with a batch size of 8192 tokens, activation storage can be reduced from over 110 GB to just 5 GB. However, this approach introduces additional computational overhead, which YaFSDP mitigates by optimizing other parts of the training process.
Communication Optimization
YaFSDP improves GPU communication efficiency by ensuring that data is transferred only when necessary and by overlapping communication with computation. It utilizes CUDA streams to manage concurrent computations and communications effectively.
The tool uses two streams: a computation stream and a communication stream. Events synchronize these streams, ensuring that operations are executed in the correct order without introducing deadlocks.
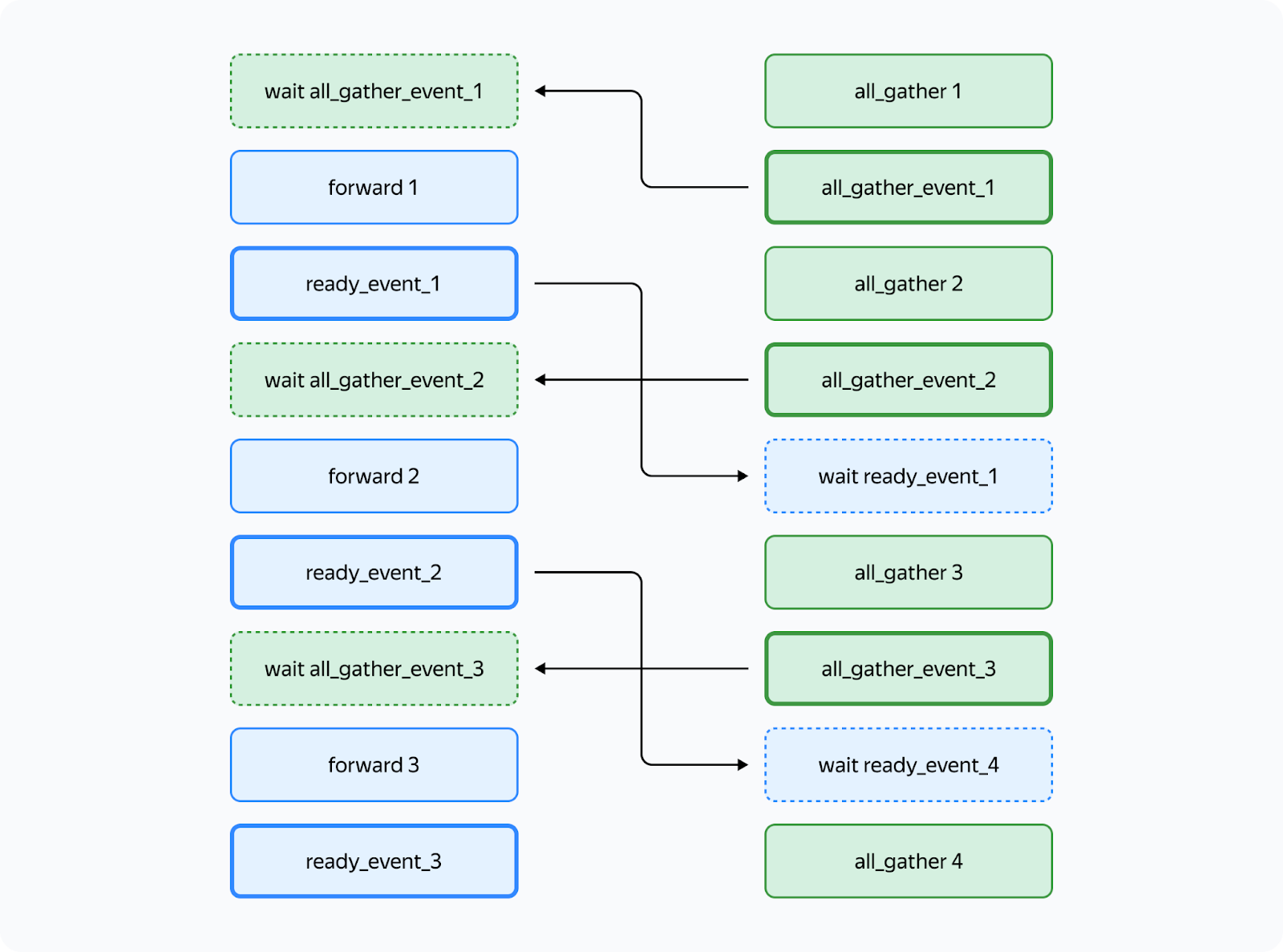
The forward pass on the third layer doesn’t start until the all_gather operation is completed (condition 1). Likewise, the all_gather operation on the third layer won’t begin until the forward pass on the first layer that uses the same buffer is completed (condition 2). Since there are no cycles in this scheme, deadlock is impossible.
Experimental Results and Performance Gains
The implementation of YaFSDP has shown remarkable improvements in training efficiency. In a pre-training scenario with a model having 70 billion parameters, YaFSDP was able to save the resources of approximately 150 GPUs. This translates into significant monthly cost savings, ranging from $0.5 to $1.5 million, depending on the virtual GPU provider or platform.
YaFSDP reduces training time by up to 26% compared to existing methods like FSDP and optimizes memory usage, making it possible to train larger models more efficiently.
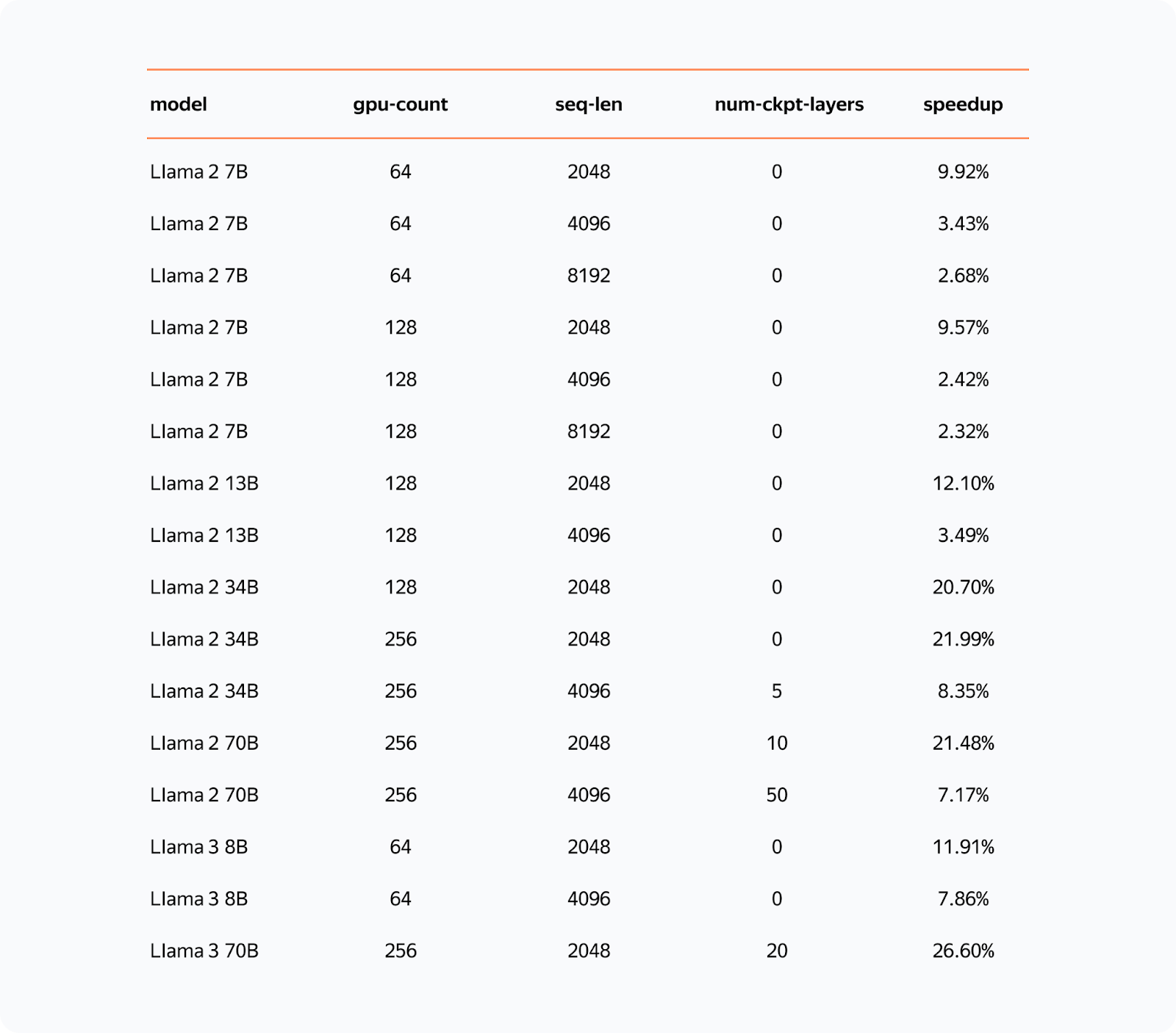
YaFSDP represents a significant advancement in LLM training. Addressing the critical challenges of memory consumption and communication inefficiencies enables faster and more efficient training of large language models.
Check out the GitHub Page. All credit for this research goes to the researchers of this project. Also, don’t forget to follow us on Twitter.
Join our Telegram Channel and LinkedIn Group.
If you like our work, you will love our newsletter..
Don’t Forget to join our 44k+ ML SubReddit
The post Yandex Introduces YaFSDP: An Open-Source AI Tool that Promises to Revolutionize LLM Training by Cutting GPU Usage by 20% appeared first on MarkTechPost.
#AIShorts #Applications #ArtificialIntelligence #EditorsPick #LanguageModel #MachineLearning #NewReleases #Staff #TechNews #Technology #Uncategorized [Source: AI Techpark]