


Using extensive labeled data, supervised machine learning algorithms have surpassed human experts in various tasks, leading to concerns about job displacement, particularly in diagnostic radiology. However, some argue that short-term job displacement is unlikely since many jobs involve a range of tasks beyond just prediction. Humans may remain essential in prediction tasks as they can learn from fewer examples. In radiology, human expertise is crucial for recognizing rare diseases. Similarly, autonomous cars face challenges with rare scenarios, which humans can handle using broader knowledge beyond driving-specific data.
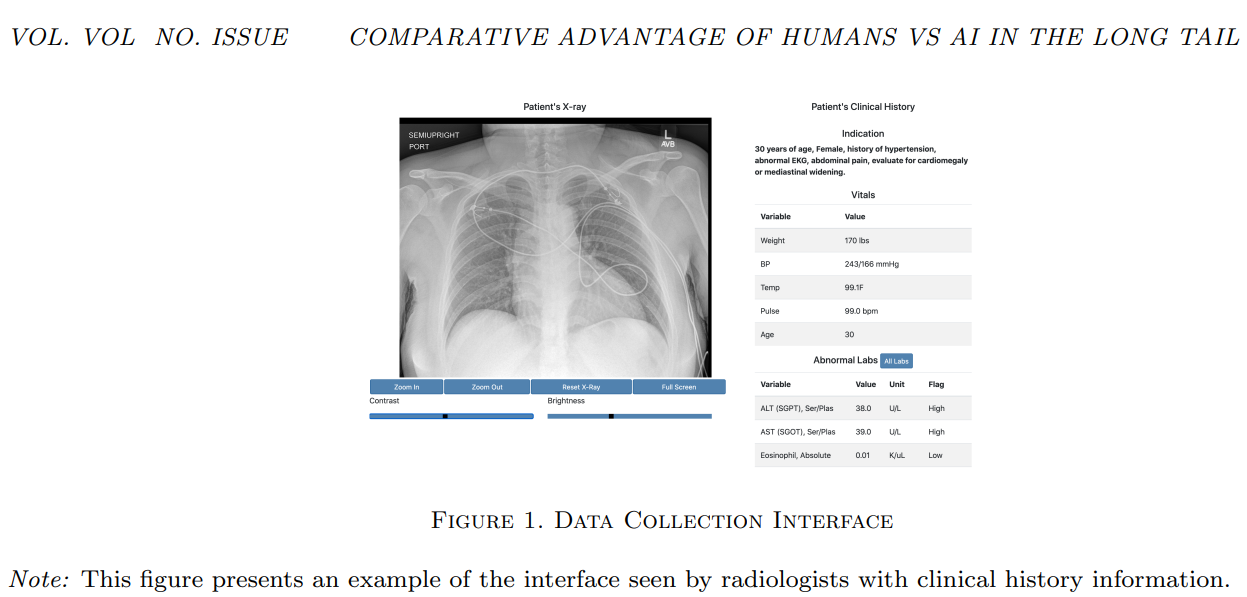
Researchers from MIT and Harvard Medical School investigated whether zero-shot learning algorithms reduce the diagnostic advantage of human radiologists for rare diseases. They compared the performance of CheXzero, a zero-shot algorithm for chest X-rays, to human radiologists and CheXpert, a traditional supervised algorithm. CheXzero, trained on the MIMIC-CXR dataset, predicts multiple pathologies using contrastive learning, while CheXpert, trained on Stanford radiographs, diagnoses twelve pathologies with explicit labels. Data was collected from 227 radiologists evaluating 324 cases from Stanford, excluding training data cases, to assess performance variation with disease prevalence.
AI and radiologist performance is compared using the concordance statistic (C), an extension of AUROC for continuous settings. Concordance, Crt, measures the proportion of concordant pairs, calculated separately for each radiologist and pathology, then averaged to obtain Ct. AI’s concordance is denoted as CAt. Concordance is chosen for its invariance to prevalence and lack of preference dependency, making it suitable even when no cases have a high consensus probability. Despite being an ordinal measure, it remains informative. Another performance metric, the deviation from consensus probability, is less effective for low-prevalence pathologies, thus influencing some conclusions.
The classification performance of human radiologists is compared to the CheXzero and CheXpert algorithms. The average prevalence of pathologies is low, around 2.42%, with some exceeding 15%. Radiologists have an average concordance of 0.58, lower than both AI algorithms, with CheXpert slightly outperforming CheXzero. However, CheXpert’s predictions cover only 12 pathologies, while CheXzero covers 79. Human and CheXzero performances are weakly correlated, indicating different focal points in X-ray analysis. CheXzero’s performance varies widely, with concordance ranging from 0.45 to 0.94, compared to the narrower 0.52 to 0.72 range for human radiologists.
The study illustrates the significance of the long tail in pathology prevalence, revealing that most relevant pathologies are not covered by the supervised learning algorithm studied. While both human and AI performance improves with pathology prevalence, CheXpert shows substantial enhancement in higher prevalence cases. CheXzero’s performance is less affected by prevalence, consistently outperforming humans across all prevalence bins. Notably, CheXzero outperforms humans even in low prevalence pathologies, challenging the notion of human superiority in such cases. However, assessing overall algorithmic performance requires cautious interpretation due to the complexity of converting ordinal outputs to diagnostic decisions, especially for rare pathologies.
Supervised machine learning algorithms have shown superiority in specific tasks compared to humans. However, humans still hold value due to their adeptness in handling rare cases, known as the long tail. Zero-shot learning algorithms aim to tackle this challenge by circumventing the need for extensive labeled data. The study compared radiologists’ assessments to two leading algorithms for diagnosing chest pathologies, indicating that self-supervised algorithms rapidly close the gap or surpass humans in predicting rare diseases. However, challenges still need to be solved in deploying algorithms, as their outputs don’t directly translate into actionable decisions, suggesting they are more likely to complement rather than replace humans.
more modalities.
Check out the Paper. All credit for this research goes to the researchers of this project. Also, don’t forget to follow us on Twitter. Join our Telegram Channel, Discord Channel, and LinkedIn Group.
If you like our work, you will love our newsletter..
Don’t Forget to join our 43k+ ML SubReddit | Also, check out our AI Events Platform
The post Unveiling the Diagnostic Landscape: Assessing AI and Human Performance in the Long Tail of Rare Diseases appeared first on MarkTechPost.
#AIPaperSummary #AIShorts #Applications #ArtificialIntelligence #EditorsPick #MachineLearning #Staff #TechNews #Technology [Source: AI Techpark]