


Vision-Language Models are a pivotal advancement in artificial intelligence, integrating the domains of computer vision and natural language processing. These models facilitate a range of applications, including image captioning, visual question answering, and generating images from text prompts, significantly enhancing human-computer interaction capabilities.
A key challenge in vision-language modeling is aligning the high-dimensional visual data with discrete textual data. This discrepancy often leads to difficulties in accurately understanding and generating coherent text-vision interactions, necessitating innovative approaches to bridge the gap effectively.
Current approaches to vision-language modeling include contrastive training, masking strategies, and generative models. Contrastive methods, such as CLIP, train models to predict similar representations for related image-text pairs. Masking involves reconstructing masked parts of an image or text, while generative models focus on creating new images or captions based on input prompts
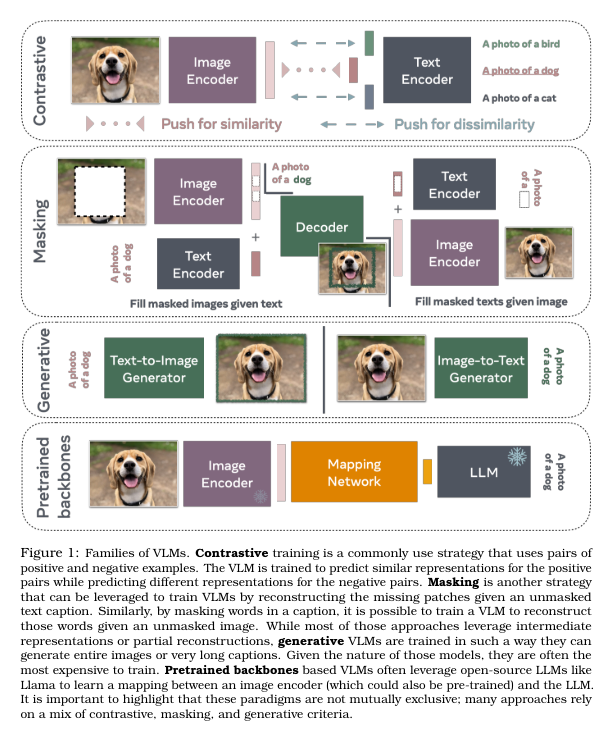
Researchers from Meta, MIT, NYU and various other institutes, in a collaborative effort, have introduced various Vision-Language Models, leveraging pre-trained backbones to reduce computational costs. These models employ techniques like contrastive loss, masking, and generative components to improve vision-language understanding. The models typically use a transformer architecture, incorporating image encoders and text decoders. For instance, CLIP uses contrastive loss to align image and text embeddings in a shared space. Generative models like CoCa employ a multimodal text decoder for tasks such as image captioning, enhancing the model’s ability to understand and generate multimodal content. Furthermore, methods like VILA and LAION-aesthetics assess the aesthetic quality of images to select high-quality subsets of data, improving image generation models.
In-depth Methodology:
The methodologies employed in Vision-Language Models involve a complex integration of transformer architectures, image encoders, and text decoders. One of the primary methods, CLIP, developed by researchers at OpenAI, uses contrastive loss to align image and text embeddings within a shared space. This method enables the model to learn representations that capture both visual and textual information effectively. The training process involves pairing images with corresponding textual descriptions, allowing the model to develop a nuanced understanding of the relationships between visual and textual data.
Generative models like CoCa, introduced by researchers at Google, take a different approach by employing a multimodal text decoder. This allows the model to perform tasks such as image captioning with a high degree of accuracy. The multimodal text decoder is trained to generate descriptive captions for given images, enhancing the model’s ability to produce coherent and contextually relevant text based on visual input.
Another significant methodology is the use of masking strategies. This involves randomly masking parts of the input data—whether image or text—and training the model to predict the masked content. This technique helps in improving the model’s robustness and its ability to handle incomplete or partially visible data, thereby enhancing its performance in real-world applications where data may be noisy or incomplete.
Performance and Results:
The performance of Vision-Language Models is rigorously evaluated using a variety of benchmarks. One of the most notable results comes from the CLIP model, which achieved a remarkable zero-shot classification accuracy. This means that the model was able to classify images correctly without having been explicitly trained on the specific categories in the test set. Such performance demonstrates the model’s ability to generalize from its training data to new, unseen categories.
Another significant result comes from the FLAVA model, which has set new state-of-the-art performance across a range of tasks involving vision, language, and multimodal integration. For instance, FLAVA has shown exceptional accuracy in image captioning tasks, generating high-quality captions that accurately describe the content of images. The model’s performance on visual question answering tasks is also noteworthy, with significant improvements over previous models.

The LLaVA-RLHF model, developed by a collaboration between MIT and NYU, has achieved a performance level of 94% compared to GPT-4. Moreover, on the MMHAL-BENCH benchmark, which focuses on minimizing hallucinations and improving factual accuracy, LLaVA-RLHF has outperformed baseline models by 60%. These results highlight the effectiveness of reinforcement learning from human feedback (RLHF) in improving the alignment of model outputs with human expectations and factual accuracy.
Conclusion:
In summary, Vision-Language Models represent a significant advancement in the field of artificial intelligence, offering powerful tools for integrating visual and textual data. The methodologies employed, including contrastive training, generative modeling, and masking strategies, have proven effective in addressing the challenges of aligning high-dimensional visual data with discrete textual data. The impressive performance results achieved by models like CLIP, FLAVA, and LLaVA-RLHF underscore the potential of these technologies to transform a wide range of applications, from image captioning to visual question answering. Continued research and development in this area promise to further enhance the capabilities of Vision-Language Models and expand their applications.
Check out the Paper. All credit for this research goes to the researchers of this project. Also, don’t forget to follow us on Twitter. Join our Telegram Channel, Discord Channel, and LinkedIn Group.
If you like our work, you will love our newsletter..
Don’t Forget to join our 43k+ ML SubReddit | Also, check out our AI Events Platform
The post Unlocking the Potential of Multimodal Data: A Look at Vision-Language Models and their Applications appeared first on MarkTechPost.
#AIPaperSummary #AIShorts #Applications #ArtificialIntelligence #EditorsPick #MachineLearning #Staff #TechNews #Technology [Source: AI Techpark]