


Researchers have drawn parallels between protein sequences and natural language due to their sequential structures, leading to advancements in deep learning models for both fields. LLMs have excelled in NLP tasks, and this success has inspired attempts to adapt them to understanding proteins. However, this adaptation faces a challenge: existing datasets need more direct correlations between protein sequences and text descriptions, hindering effective training and evaluation of LLMs for protein comprehension. Despite advances in MMLMs, the absence of comprehensive datasets integrating protein sequences with textual content limits the full utilization of these models in protein science.
Researchers from several institutions, including Johns Hopkins and UNSW Sydney, have created ProteinLMDataset to enhance LLMs’ understanding of protein sequences. This dataset contains 17.46 billion tokens for self-supervised pretraining and 893K instructions for supervised fine-tuning. They also developed ProteinLMBench, the first benchmark with 944 manually verified multiple-choice questions for evaluating protein comprehension in LLMs. The dataset and benchmark aim to bridge the gap in protein-text data integration, enabling LLMs to understand protein sequences without extra encoders and to generate accurate protein knowledge using the novel Enzyme Chain of Thought (ECoT) approach.
The literature review highlights key limitations in existing datasets and NLP and protein sequence benchmarks. There need to be more comprehensive, multi-task, and multi-domain evaluations for Chinese-English datasets, with existing benchmarks often restricted geographically and needing more interpretability. In protein sequence datasets, major resources like UniProtKB and RefSeq face challenges in fully representing protein diversity and accurately annotating data, with biases and errors from community contributions and automated systems. While comprehensive, protein design databases like KEGG and STRING are limited by biases, resource-intensive curation, and difficulties in integrating diverse data sources.
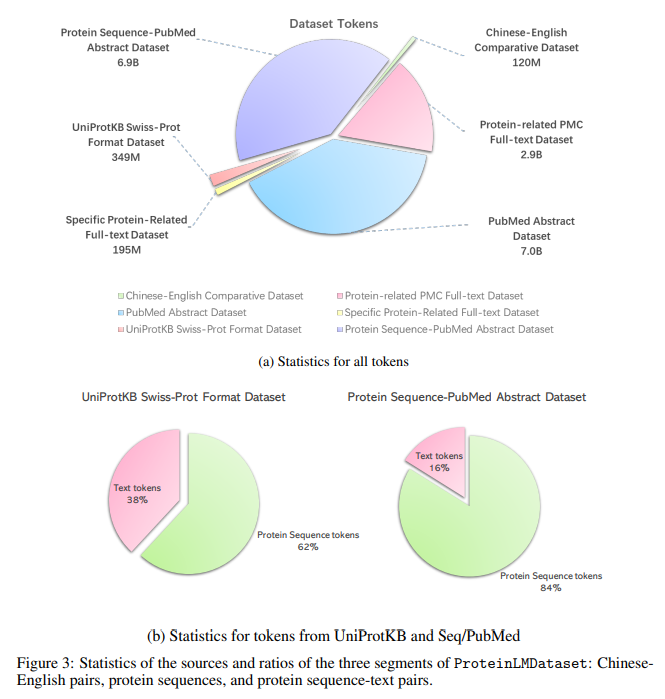
The ProteinLMDataset is divided into self-supervised and supervised components. The self-supervised dataset includes Chinese-English scientific texts, protein sequence-English text pairs from PubMed and UniProtKB, and extensive entries from the PMC database, providing over 10 billion tokens. The supervised fine-tuning component consists of 893,000 instructions across seven segments, such as enzyme functionality and disease involvement, mainly sourced from UniProtKB. ProteinLMBench, the evaluation benchmark, contains 944 meticulously curated multiple-choice questions on protein properties and sequences. This dataset collection method ensures comprehensive representation, filtering, and tokenization for effective training and evaluation of LLMs in protein science.
The ProteinLMDataset and ProteinLMBench are designed for comprehensive protein sequence understanding. The dataset is diverse, with tokens ranging from 21 to over 2 million characters, collected from multiple sources, including Chinese-English text pairs, PubMed abstracts, and UniProtKB. The self-supervised data primarily consists of protein sequences and scientific texts. At the same time, the supervised fine-tuning dataset covers seven segments like enzyme functionality and disease involvement, with token lengths from 65 to 70,500. The ProteinLMBench includes 944 balanced multiple-choice questions to evaluate model performance. Rigorous safety checks and filtering ensure data quality and integrity. Experiment results show that combining self-supervised learning with fine-tuning enhances model accuracy, underscoring the dataset’s efficacy.
In conclusion, The ProteinLMDataset and ProteinLMBench provide a robust framework for training and evaluating language models on protein sequences and bilingual texts. By encompassing diverse sources and including Chinese-English text pairs, the dataset enhances multilingual and cross-lingual understanding of protein characteristics. Experiments demonstrate significant improvements in model accuracy with fine-tuning, especially when using both self-supervised and supervised datasets. This work bridges the gap in adapting LLMs for protein science, showcasing the potential to transform biological research and applications. The InternLM2-7B model, when trained on this dataset, surpasses GPT-4 in protein comprehension tasks.
issues.
Check out the Paper and Dataset. All credit for this research goes to the researchers of this project. Also, don’t forget to follow us on Twitter.
Join our Telegram Channel and LinkedIn Group.
If you like our work, you will love our newsletter..
Don’t Forget to join our 44k+ ML SubReddit
The post Unlocking the Language of Proteins: How Large Language Models Are Revolutionizing Protein Sequence Understanding appeared first on MarkTechPost.
#AIShorts #Applications #ArtificialIntelligence #EditorsPick #Staff #TechNews #Technology [Source: AI Techpark]