
AI’s black box problem has been building ever since deep learning models started gaining traction about 10 years ago. But now that we’re in the post-ChatGPT era, the black box fears of 2022 seem quaint to Shayan Mohanty, co-founder and CEO at Watchful, a San Francisco startup hoping to deliver more transparency into how large language models work.
“It’s almost hilarious in hindsight,” Mohanty says. “Because when people were talking about black box AI before, they were just talking about big, complicated models, but they were still writing that code. They were still running it within their four walls. They owned all the data they were training it on.
“But now we’re in this world where it’s like OpenAI is the only one who can touch and feel that model. Anthropic is the only one who can touch and feel their model,” he continues. “As the user of those models, I only have access to an API, and that API allows me to send a prompt, get a response, or send some text and get an embedding. And that’s all I have access to. I can’t actually interpret what the model itself is doing, why it’s doing it.”
That lack of transparency is a problem, from a regulatory perspective but also just from a practical viewpoint. If users don’t have a way to measure whether their prompts to GPT-4 are eliciting worthy responses, then they don’t have a way to improve them.
There is a method to elicit feedback from the LLMs called integrated gradients, which allows users to determine how the input to an LLM impacts the output. “It’s almost like you have a bunch of little knobs,” Mohanty says. “These knobs might represent words in your prompt, for instance…As I tune things up, I see how that changes the response.”

Integrated gradients gives users knobs to tune LLMs (iain hall/Shutterstock)
The problem with integrated gradients is that it’s prohibitively expensive to run. While it might be feasible for large companies to use it on their own LLM, such as Llama-2 from Meta AI, it’s not a practical solution for the many users of vendor solutions, such as OpenAI.
“The problem is that there aren’t just well-defined methods to infer” how an LLM is running, he says. “There aren’t well-defined metrics that you can just look at. There’s no canned solution to any of this. So all of this is going to have to be basically greenfield.”
Greenfielding Blackbox Metrics
Mohanty and his colleagues at Watchful have taken a stab at creating performance metrics for LLMs. After a period of research, they hit upon a new technique that delivers results that are similar to the integrated gradients technique, but without the huge expense and without needing direct access to the model.
“You can apply this approach to GPT-3, GPT-4, GPT-5, Claude–it doesn’t really matter,” he says. “You can plug in any model to this process, and it’s computationally efficient and it predicts really well.”
The company today unveiled two LLM metrics based on that research, including Token Importance Estimation and Model Uncertainty Scoring. Both of the metrics are free and open source.
Token Importance Estimation gives AI developers an estimate of token importance within prompts using advanced text embeddings. You can read more about it here. Model Uncertainty Scoring, meanwhile, evaluates the uncertainty of LLM responses, along the lines of conceptual and structural uncertainty. You can read more about it at this link.
Both of the new metrics are based on Watchful’s research into how LLMs interact with the embedding space, or the multi-dimensional area where text inputs are translated into numerical scores, or embeddings, and where the relatively proximity of those scores can be calculated, which is central to how LLMs work.
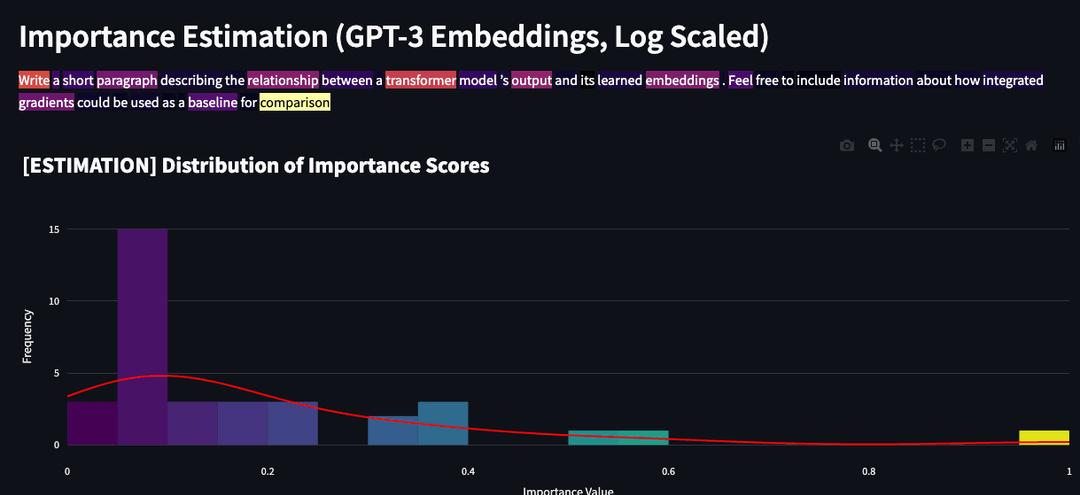
Watchful’s new Token Importance Estimator tells you which words in your prompt have the biggest impact (Image source: Watchful)
LLMs like GPT-4 are estimated to have 1,500 dimensions in their embedding space, which is simply beyond human comprehension. But Watchful has come up with a way to programmatically poke and prod at its mammoth embedding space through prompts sent via API, in effect gradually exploring how it works.
“What’s happening is that we take the prompt and we just keep changing it in known ways,” Mohanty says. “So for instance, you could drop each token one by one, and you could see, okay, if I drop this word, here’s how it changes the model’s interpretation of the prompt.”
While the embedding space is very large, it’s finite. “You’re just given a prompt, and you can change it in various ways that again, are finite,” Mohanty says. “You just keep re-embedding that, and you see how those numbers change. Then we can calculate statistically, what the model is likely doing based on seeing how changing the prompt affects the model’s interpretation in the embedding space.”
The result of this work is a tool that might show that the very large prompts a customer is sending GPT-4 are not having the desired impact. Perhaps the model is simply ignoring two of the three examples that are included in the prompt, Mohanty says. That could allow the user to immediately reduce the size of the prompt, saving money and providing a timelier response.
Better Feedback for Better AI
It’s all about providing a feedback mechanism that has been missing up to this point, Mohanty says.
“Once someone wrote a prompt, they didn’t really know what they needed to do differently to get a better result,” Mohany says. “Our goal with all this research is just to peel back the layers of the model, allow people to understand what it’s doing, and do it in a model-agnostic way.”

Shayan Mohanty is the CEO and co-Founder of Watchful
The company is releasing the tools as open source as a way to kickstart the movement toward better understanding of LLMs and toward fewer black box question marks. Mohanty would expect other members of the community to take the tools and build on them, such as integrating them with LangChain and other components of the GenAI stack.
“We think it’s the right thing to do,” he says about open sourcing the tools. “We’re not going to arrive at a point very quickly where everyone converges, where these are the metrics that everyone cares about. The only way we get there is by everyone sharing how you’re thinking about this. So we took the first couple of steps, we did this research, we discovered these things. Instead of gating that and only allowing it to be seen by our customers, we think it’s really important that we just put it out there so that other people can build on top of it.”
Eventually, these metrics could form the basis for an enterprise dashboard that would inform customers how their GenAI applications are functioning, sort of like TensorBoard does for TensorFlow. That product would be sold by Watchful. In the meantime, the company is content to share its knowledge and help the community move toward a place where more light can shine on black box AI models.
Editor s note: This article first appeared in Datanami.
#Slider:FrontPage #blackbox #integratedgradients #LLM #ShayanMohanty #TokenImportanceEstimation #transparency [Source: EnterpriseAI]