


Across the globe, individuals create myriad videos daily, including user-generated live streams, video-game live streams, short clips, movies, sports broadcasts, and advertising. As a versatile medium, videos convey information and content through various modalities, such as text, visuals, and audio. Developing methods capable of learning from these diverse modalities is crucial for designing cognitive machines with enhanced capabilities to analyze uncurated real-world videos, transcending the limitations of hand-curated datasets.
However, the richness of this representation introduces numerous challenges for exploring video understanding, particularly when confronting extended-duration videos. Grasping the nuances of long videos, especially those exceeding an hour, necessitates sophisticated methods of analyzing images and audio sequences across multiple episodes. This complexity increases with the need to extract information from diverse sources, distinguish speakers, identify characters, and maintain narrative coherence. Furthermore, answering questions based on video evidence demands a deep comprehension of the content, context, and subtitles.
In live streaming and gaming video, additional challenges emerge in processing dynamic environments in real-time, requiring semantic understanding and the ability to engage in long-term strategic planning.
In recent times, considerable progress has been achieved in large pre-trained and video-language models, showcasing their proficient reasoning capabilities for video content. However, these models are typically trained on concise clips (e.g., 10-second videos) or predefined action classes. Consequently, these models may encounter limitations in providing a nuanced understanding of intricate real-world videos.
The complexity of understanding real-world videos involves identifying individuals in the scene and discerning their actions. Furthermore, pinpointing these actions is necessary, specifying when and how these actions occur. Additionally, it necessitates recognizing subtle nuances and visual cues across different scenes. The primary objective of this work is to confront these challenges and explore methodologies directly applicable to real-world video understanding. The approach involves deconstructing extended video content into coherent narratives, subsequently employing these generated stories for video analysis.
Recent strides in Large Multimodal Models (LMMs), such as GPT-4V(ision), have marked significant breakthroughs in processing both input images and text for multimodal understanding. This has spurred interest in extending the application of LMMs to the video domain. The study reported in this article introduces MM-VID, a system that integrates specialized tools with GPT-4V for video understanding. The overview of the system is illustrated in the figure below.
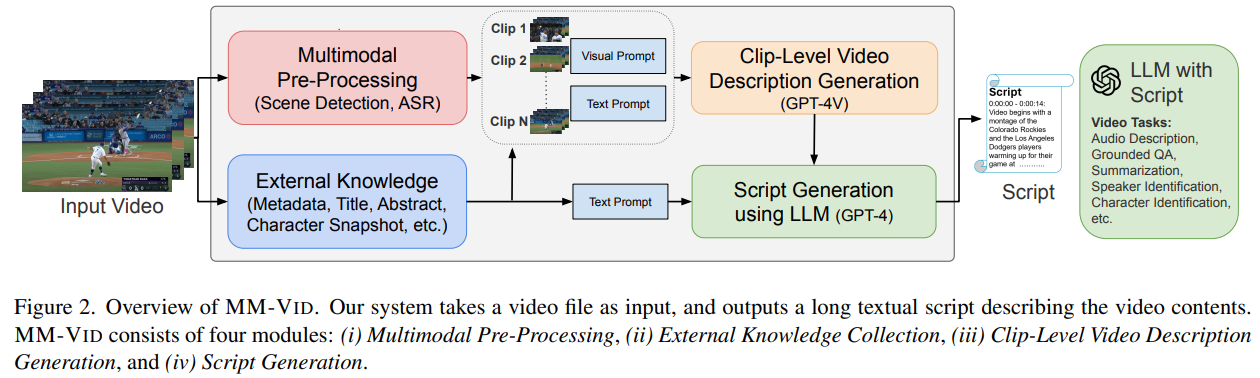
Upon receiving an input video, MM-VID initiates multimodal pre-processing, encompassing scene detection and automatic speech recognition (ASR), to gather crucial information from the video. Subsequently, the input video is segmented into multiple clips based on the scene detection algorithm. GPT-4V is then employed, utilizing clip-level video frames as input to generate detailed descriptions for each video clip. Finally, GPT-4 produces a coherent script for the entire video, conditioned on clip-level video descriptions, ASR, and available video metadata. The generated script empowers MM-VID to execute a diverse array of video tasks.
Some examples taken from the study are reported below.
This was the summary of MM-VID, a novel AI system integrating specialized tools with GPT-4V for video understanding. If you are interested and want to learn more about it, please feel free to refer to the links cited below.
Check out the Paper and Project Page. All credit for this research goes to the researchers of this project. Also, don’t forget to join our 33k+ ML SubReddit, 41k+ Facebook Community, Discord Channel, and Email Newsletter, where we share the latest AI research news, cool AI projects, and more.
If you like our work, you will love our newsletter..
We are also on Telegram and WhatsApp.
The post Unlock Advancing AI Video Understanding with MM-VID for GPT-4V(ision) appeared first on MarkTechPost.
#AIShorts #Applications #ArtificialIntelligence #ComputerVision #EditorsPick #MachineLearning #Staff #TechNews #Technology [Source: AI Techpark]