


In the dynamic realm of computer vision and artificial intelligence, a new approach challenges the traditional trend of building larger models for advanced visual understanding. The approach in the current research, underpinned by the belief that larger models yield more powerful representations, has led to the development of gigantic vision models.
Central to this exploration lies a critical examination of the prevailing practice of model upscaling. This scrutiny brings to light the significant resource expenditure and the diminishing returns on performance enhancements associated with continuously enlarging model architectures. It raises a pertinent question about the sustainability and efficiency of this approach, especially in a domain where computational resources are invaluable.
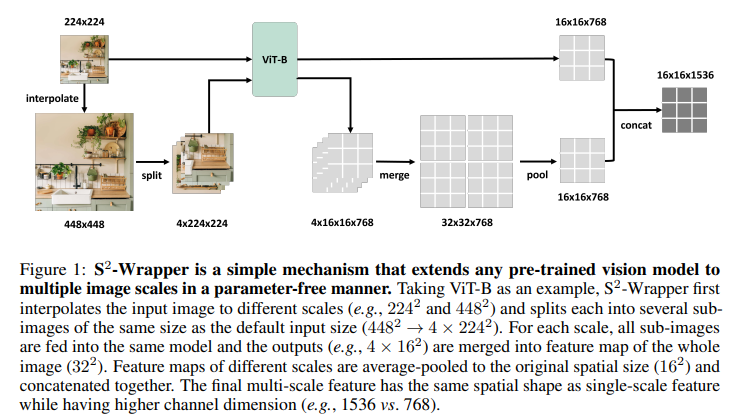
UC Berkeley and Microsoft Research introduced an innovative technique called Scaling on Scales (S2). This method represents a paradigm shift, proposing a strategy that diverges from the traditional model scaling. By applying a pre-trained, smaller vision model across various image scales, S2 aims to extract multi-scale representations, offering a new lens through which visual understanding can be enhanced without necessarily increasing the model’s size.
Leveraging multiple image scales produces a composite representation that rivals or surpasses the output of much larger models. The research showcases the S2 technique’s prowess across several benchmarks, where it consistently outperforms its larger counterparts in tasks including but not limited to classification, semantic segmentation, and depth estimation. It sets a new state-of-the-art in multimodal LLM (MLLM) visual detail understanding on the V* benchmark, outstripping even commercial models like Gemini Pro and GPT-4V, with significantly fewer parameters and comparable or reduced computational demands.
For instance, in robotic manipulation tasks, the S2 scaling method on a base-size model improved the success rate by about 20%, demonstrating its superiority over mere model-size scaling. The detailed understanding capability of LLaVA-1.5, with S2 scaling, achieved remarkable accuracies, with V* Attention and V* Spatial scoring 76.3% and 63.2%, respectively. These figures underscore the effectiveness of S2 and highlight its efficiency and the potential for reducing computational resource expenditure.
This research sheds light on the increasingly pertinent question of whether the relentless scaling of model sizes is truly necessary for advancing visual understanding. Through the lens of the S2 technique, it becomes evident that alternative scaling methods, particularly those focusing on exploiting the multi-scale nature of visual data, can provide equally compelling, if not superior, performance outcomes. This approach challenges the existing paradigm and opens up new avenues for resource-efficient and scalable model development in computer vision.

In conclusion, introducing and validating the Scaling on Scales (S2) method represents a significant breakthrough in computer vision and artificial intelligence. This research compellingly argues for a departure from the prevalent model size expansion towards a more nuanced and efficient scaling strategy that leverages multi-scale image representations. Doing so demonstrates the potential for achieving state-of-the-art performance across visual tasks. It underscores the importance of innovative scaling techniques in promoting computational efficiency and resource sustainability in AI development. The S2 method, with its ability to rival or even surpass the output of much larger models, offers a promising alternative to traditional model scaling, highlighting its potential to revolutionize the field.
Check out the Paper and Github. All credit for this research goes to the researchers of this project. Also, don’t forget to follow us on Twitter. Join our Telegram Channel, Discord Channel, and LinkedIn Group.
If you like our work, you will love our newsletter..
Don’t Forget to join our 39k+ ML SubReddit
The post UC Berkeley and Microsoft Research Redefine Visual Understanding: How Scaling on Scales Outperforms Larger Models with Efficiency and Elegance appeared first on MarkTechPost.
#AIPaperSummary #AIShorts #Applications #ArtificialIntelligence #ComputerVision #EditorsPick #Staff #TechNews #Technology [Source: AI Techpark]