


Integrating attention mechanisms into neural network architectures in machine learning has marked a significant leap forward, especially in processing textual data. At the heart of these advancements are self-attention layers, which have revolutionized our ability to extract nuanced information from sequences of words. These layers excel in identifying the relevance of different parts of the input data, essentially focusing on the ‘important’ parts to make more informed decisions.
A groundbreaking study conducted by researchers from the Statistical Physics of Computation Laboratory and the Information Learning & Physics Laboratory at EPFL, Switzerland, sheds new light on the dynamics of dot-product attention layers. The team meticulously examines how these layers learn to prioritize input tokens based on their positional relationships or semantic connections. This exploration is particularly significant as it taps into the foundational aspects of learning mechanisms within transformers, offering insights into their adaptability and efficiency in handling diverse tasks.
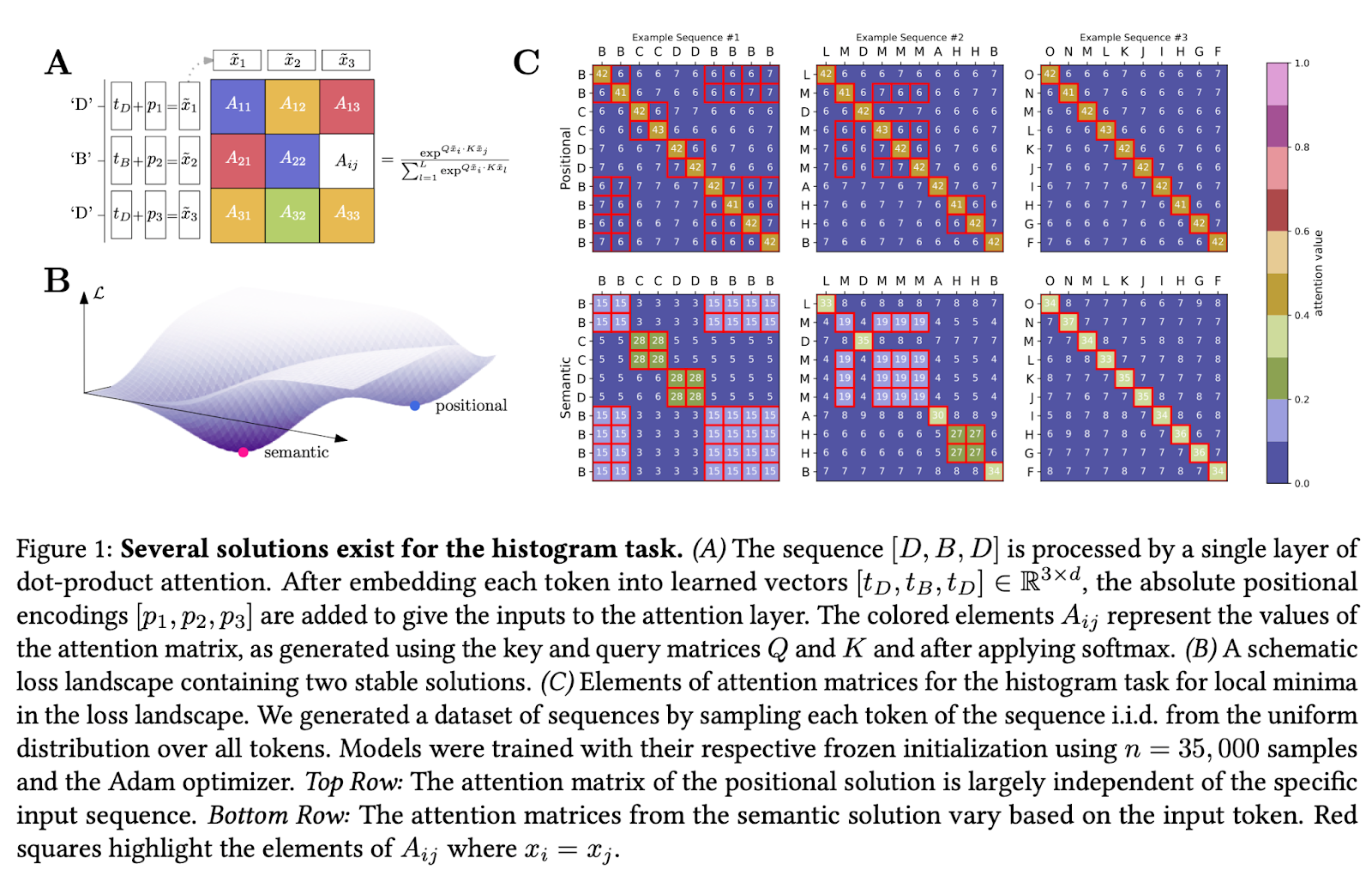
The researchers introduce a novel, solvable model of dot-product attention that stands out for its ability to navigate the learning process toward either a positional or semantic attention matrix. They ingeniously demonstrate the model’s versatility by employing a single self-attention layer with uniquely tied, low-rank query and key matrices. The empirical and theoretical analyses reveal a fascinating phenomenon: a phase transition in learning focus from positional to semantic mechanisms as the complexity of the sample data increases.
Experimental evidence underscores the model’s adeptness at distinguishing between these learning mechanisms. For instance, the model achieves near-perfect test accuracy in a histogram task, illustrating its capability to adapt its learning strategy based on the nature of the task and the available data. This is further corroborated by a rigorous theoretical framework that maps the learning dynamics in high-dimensional settings. The analysis highlights a critical threshold in sample complexity that dictates the shift from positional to semantic learning. This revelation has profound implications for designing and implementing future attention-based models.
The EPFL team’s contributions go beyond mere academic curiosity. By dissecting the conditions under which dot-product attention layers excel, they pave the way for more efficient and adaptable neural networks. This research enriches our theoretical understanding of attention mechanisms and offers practical guidelines for optimizing transformer models for various applications.
In conclusion, EPFL’s study represents a significant milestone in our pursuit to understand the intricacies of attention mechanisms in neural networks. By elegantly demonstrating the existence of a phase transition between positional and semantic learning, the research opens up new horizons for enhancing the capabilities of machine learning models. This work not only enriches the academic discourse but also has the potential to influence the development of more sophisticated and effective AI systems in the future.
Check out the Paper. All credit for this research goes to the researchers of this project. Also, don’t forget to follow us on Twitter and Google News. Join our 37k+ ML SubReddit, 41k+ Facebook Community, Discord Channel, and LinkedIn Group.
If you like our work, you will love our newsletter..
Don’t Forget to join our Telegram Channel
The post Transform Your Understanding of Attention: EPFL’s Cutting-Edge Research Unlocks the Secrets of Transformer Efficiency! appeared first on MarkTechPost.
#AIShorts #Applications #ArtificialIntelligence #EditorsPick #MachineLearning #Staff #TechNews #Technology #Uncategorized [Source: AI Techpark]