


A fascinating field of study in artificial intelligence and computer vision is the creation of videos based on written descriptions. This innovative technology combines creativity and computation and has numerous potential applications, including film production, virtual reality, and automated content generation.
The primary obstacle in this field is the need for large, annotated video-text datasets necessary for training advanced models. The challenge lies in the labor-intensive and resource-heavy process of creating these datasets. This scarcity restricts the development of more sophisticated text-to-video generation models, which could otherwise advance the field significantly.
Conventionally, methods in text-to-video generation heavily rely on video-text datasets. These methods typically incorporate temporal blocks into models such as latent 2D-UNet, trained on these datasets, to produce videos. However, the limitations of these datasets lead to difficulties in achieving seamless temporal transitions and high-quality video output.
Addressing these challenges, researchers from Huazhong University of Science and Technology, Alibaba Group, Zhejiang University, and Ant Group have introduced TF-T2V, a pioneering framework for text-to-video generation. This approach is distinct in its use of text-free videos, circumventing the need for extensive video-text pair datasets. The framework is structured into two primary branches: focusing on spatial appearance generation and motion dynamics synthesis.
The content branch of TF-T2V specializes in generating the spatial appearance of videos. It optimizes the visual quality of the generated content, ensuring that the videos are realistic and visually appealing. In parallel, the motion branch is engineered to learn complex motion patterns from text-free videos, thus enhancing the temporal coherence of the generated videos. A notable feature of TF-T2V is the introduction of a material coherence loss. This innovative component is crucial in ensuring a smooth transition between frames, significantly improving the overall fluidity and continuity of the videos.
In terms of performance, TF-T2V has shown remarkable results. The framework significantly improved key performance metrics like the Frechet Inception Distance (FID) and the Frechet Video Distance (FVD). These improvements indicate a higher fidelity in video generation and more accurate motion dynamics. The framework not only surpassed its predecessors in synthetic continuity but also set new standards in visual quality. This advancement was evidenced through a series of comprehensive evaluations, both quantitative and qualitative, demonstrating TF-T2V’s superiority over existing methods in the field.
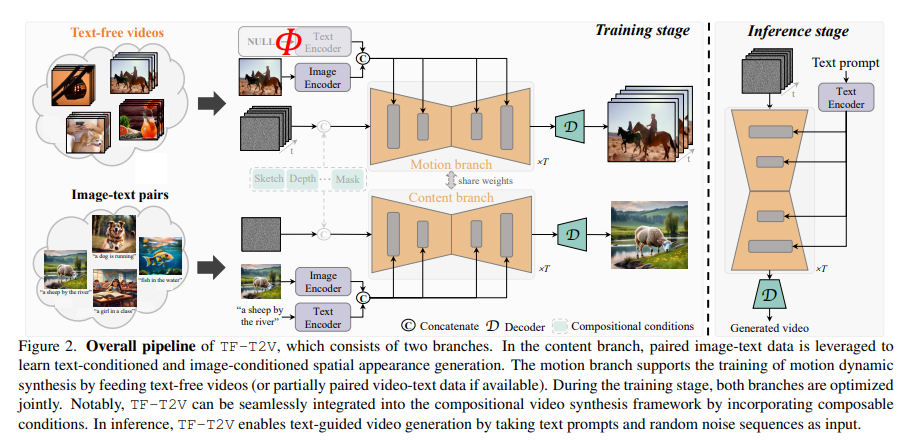
To conclude, the TF-T2V framework offers several key advantages:
- It innovatively utilizes text-free videos, addressing the data scarcity issue prevalent in the field.
- The dual-branch structure, focusing on spatial appearance and motion dynamics, generates high-quality, coherent video.
- The introduction of temporal coherence loss significantly enhances the fluidity of video transitions.
- Extensive evaluations have established TF-T2V’s superiority in generating more lifelike and continuous videos compared to existing methods.
This research marks a significant stride in text-to-video generation, paving the way for more scalable and efficient approaches in video synthesis. The implications of this technology extend far beyond current applications, offering exciting possibilities for future media and content creation.
Check out the Paper. All credit for this research goes to the researchers of this project. Also, don’t forget to join our 35k+ ML SubReddit, 41k+ Facebook Community, Discord Channel, LinkedIn Group, and Email Newsletter, where we share the latest AI research news, cool AI projects, and more.
If you like our work, you will love our newsletter..
The post This Paper Introduces TF-T2V: A Novel Text-to-Video Generation Framework with Impressive Scalability and Performance Improvements appeared first on MarkTechPost.
#AIShorts #Applications #ArtificialIntelligence #ComputerVision #EditorsPick #Staff #TechNews #Technology #Uncategorized [Source: AI Techpark]