


Reinforcement Learning (RL) finetuning is an important step in training language models (LMs) to behave in specific ways and follow human etiquette. In today’s applications, RL finetuning involves multiple goals due to various human preferences and uses. The multi-objective finetuning (MOFT) is needed to train a multi-objective LM to overcome the limitations of single-objective finetuning (SOFT). For LMs, MOFT has been explored through prompt-based and parameter-based methods. Prompt-based methods finetune an LM by including the reward weightings in the prompt. However, this approach can be less effective in guiding the model and sensitive to how the weightings are presented. Further, zero-shot MOFT might perform badly on intermediate weightings, which are not encountered during training.
The two main techniques to approach multi-reward alignment (or MOFT) are prompt-based, and parameter-based conditioning. Prompt-based conditioning contains approaches like Personalized Soups (PS), which use custom prompts to personalize language models (LMs) based on binary weights for different rewards. Rewarded Soups (RS) offers a zero-shot method by averaging the parameters of LMs trained independently at inference time. A recent paper introduces embedding reward weightings as singular values within the AdaLoRA framework. For KL realignment, decoding time realignment linearly mixes logits between 𝜋ref and another LM learned through SOFT with the minimum KL weight.
A team from Google has proposed a general MOFT framework called Conditional Language Policy (CLP), that uses parameter-space conditioning and multi-task training. This method is more steerable than purely prompt-based techniques because it uses parameter-conditioning from RS. Moreover, CLP produces higher-quality responses than zero-shot methods like RS by finetuning on different reward weightings, while having the same or better steerability. The team conducted a series of experiments and found that CLP outperforms Pareto-dominates RS and is more controllable than prompt-based MOFT. It consistently maintains these advantages in various conditions, including different reward choices and model sizes.
The proposed method CLP, learns a set of parameters that can be processed into a conditioned language model (LM) for any given weighting across rewards and KL, using a parameter-averaging method. The learning algorithm samples a range of weightings to improve its Pareto-front for all weightings at once. This approach includes multi-task learning across different weightings, maximizing the MOFT objective. An automated evaluation with Gemini 1.0 Ultra shows that CLP is more adaptable and generates better responses than existing baselines. The team proposed a new theory showing that zero-shot methods can be nearly Pareto-optimal when optimal policies are aligned for individual reward.
The benchmarking results were obtained for the following setups: Single Reward, Multi KL Regularizer, Two Rewards, Fixed KL Regularizer, and Three Rewards, Fixed KL Regularizer. In the Single Reward, CLP is 2 times more computationally efficient than DeRa during inference because DeRa makes two LM calls per token. The multi-task training helps this method enhance over the zero-shot RS baseline regarding performance. Also, the full-CLP and attn-CLP maintain a more spread-out and steerable Pareto-front compared to logit-CLP and the prompting baseline. In sum, attn-CLP offers a good balance between Pareto-front and steerability while using fewer parameters than current baselines.
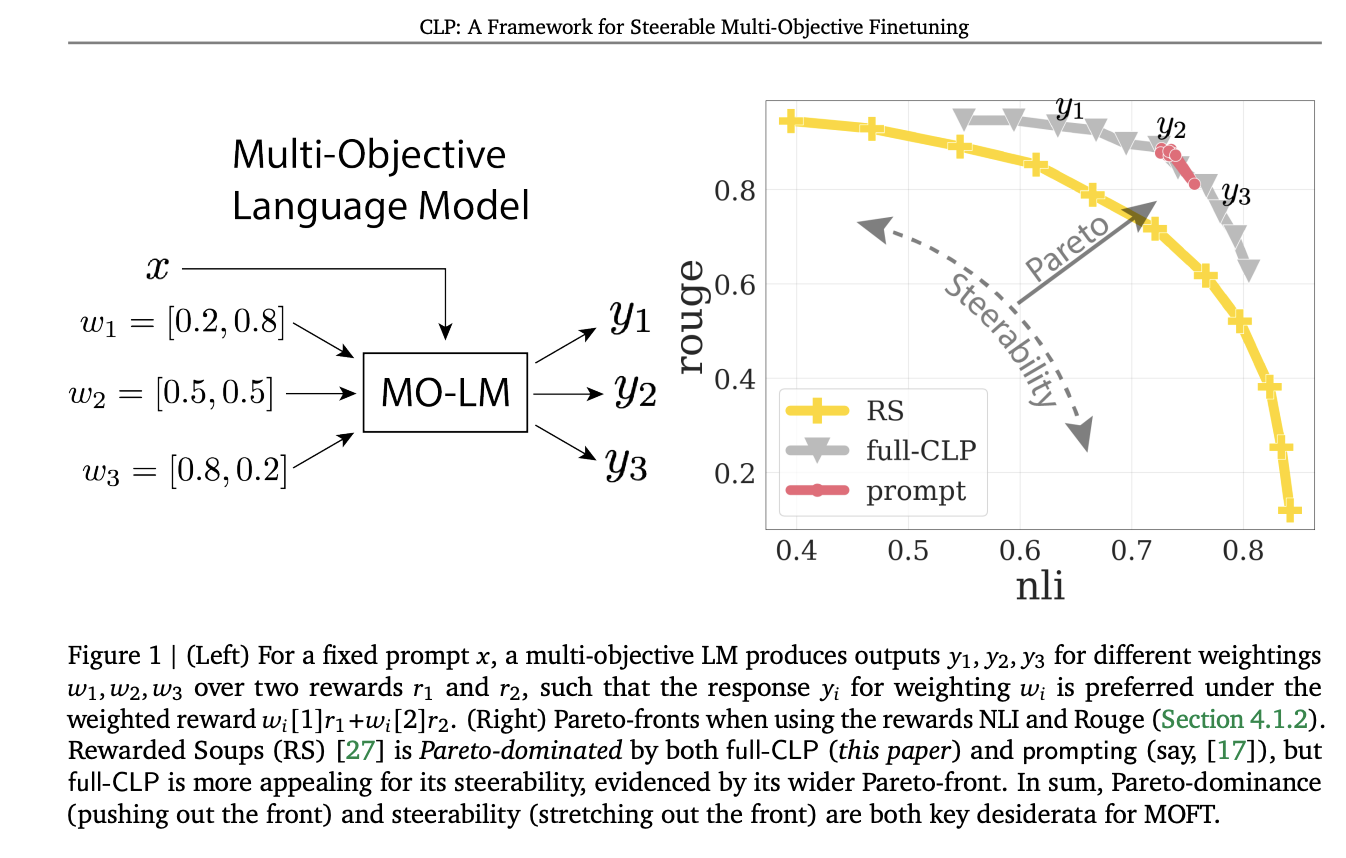
In this paper, a team from Google introduced Conditional Language Policy (CLP), a flexible framework for MOFT that uses multi-task training and efficient parameter finetuning to create adaptable language models (LMs) that can balance different individual rewards efficiently. The paper includes extensive benchmarking and ablation studies to understand the factors that help develop steerable LMs within the CLP framework. The team also proposed theoretical results to show the working of zero-shot approaches and the need for multi-task training for near-optimal behavior. Future research includes other conditioning mechanisms like soft tokens, automating the tuning of weight sampling distributions, and addressing non-linear reward scalarization.
Check out the Paper. All credit for this research goes to the researchers of this project. Also, don’t forget to follow us on Twitter and join our Telegram Channel and LinkedIn Group. If you like our work, you will love our newsletter..
Don’t Forget to join our 47k+ ML SubReddit
Find Upcoming AI Webinars here
The post This Paper from Google DeepMind Presents Conditioned Language Policies (CLP): A Machine Learning Framework for Finetuning Language Models on Multiple Objectives appeared first on MarkTechPost.
#AIPaperSummary #AIShorts #Applications #ArtificialIntelligence #EditorsPick #MachineLearning #Staff #TechNews #Technology [Source: AI Techpark]