


Language modeling is important for natural language processing tasks like machine translation and text summarization. The core of this development revolves around constructing LLMs that can process and generate human-like text which transforms how we interact with technology.
A significant challenge in language modeling is the ‘feature collapse’ problem. This issue arises in the model’s architecture, where the expressive power of the model becomes limited which leads to a reduction in the generation quality and diversity of language models. This problem needs to be tackled as it is crucial for enhancing the performance and efficiency of LLMs.
Language models that already exist often focus on scaling up the size of models and datasets to improve performance. However, this approach generates massive computational costs which makes practical applications challenging. Recent studies in enhancing model architecture have explored modifications and particularly in the multi-head self-attention and feed-forward network components of the Transformer model.
The Huawei Noah’s Ark Lab research team addresses current LLMs’ limitations by introducing a model architecture named PanGu-π. This model aims to mitigate the feature collapse problem by enhancing the nonlinearity in the model’s architecture. The innovation lies in introducing series-based activation functions and augmented shortcuts within the Transformer framework. The PanGu-π architecture demonstrates improved nonlinearity.
PanGu-π enhances the nonlinearity of language models through two main innovations. The first is the implementation of series-based activation functions in the Feed-Forward Network that adds more complexity and expressiveness to the model. The second is the introduction of augmented shortcuts in the Multi-Head Self-Attention modules which diversifies the model’s feature representation and improves its learning capability.
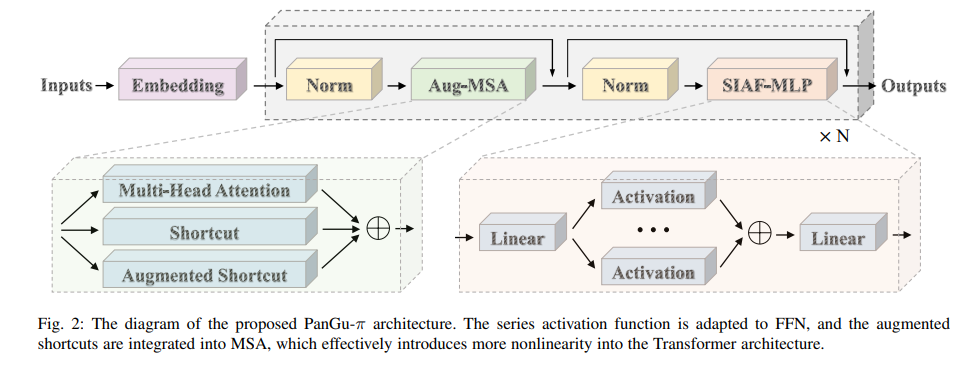
The PanGu-π architecture, including its PanGu-π-1B variant, offers a nonlinear and efficient design with a 10% speed improvement. The YunShan model which is based on PanGu-π-7B excels in the financial sector and outperforms others in specialized areas like Economics and Banking. The FinEval benchmark shines in Certificate and Accounting tasks and shows remarkable adaptability and suitability for finance-related applications.
In Conclusion, PanGu-π is a new large language model architecture that enhances nonlinearity in its design and addresses feature collapse issues. This is achieved without significantly increasing complexity, as evident in the Feed-Forward Network and Multi-Head Self-Attention modules. The model matches the current top LLMs’ performance with a 10% faster inference. PanGu-π-1B excels in accuracy and efficiency which is the variant of PanGu-π. YunShan outshines in finance and law, particularly in financial sub-domains and benchmarks and it is built on PanGu-π-1B.
Check out the Paper. All credit for this research goes to the researchers of this project. Also, don’t forget to follow us on Twitter. Join our 35k+ ML SubReddit, 41k+ Facebook Community, Discord Channel, and LinkedIn Group.
If you like our work, you will love our newsletter..
The post This Paper Explores Efficient Large Language Model Architectures – Introducing PanGu-π with Superior Performance and Speed appeared first on MarkTechPost.
#AIShorts #Applications #ArtificialIntelligence #EditorsPick #LanguageModel #LargeLanguageModel #MachineLearning #Staff #TechNews #Technology #Uncategorized [Source: AI Techpark]