


Diffusion models have shown to be very successful in producing high-quality photographs when given text suggestions. This paradigm for Text-to-picture (T2I) production has been successfully used for several downstream applications, including depth-driven picture generation and subject/segmentation identification. Two popular text-conditioned diffusion models, CLIP models and Latent Diffusion Models (LDM), often called Stable Diffusion, are essential to these developments. The LDM is well-known in research for being freely available as open-source software. UnCLIP models, on the other hand, have received little attention. The basic goal of both model types is to train diffusion models in response to text cues.
Unlike unCLIP models, which include a text-to-image prior and a diffusion image decoder, the LDM has a single text-to-image diffusion model. Both model families operate within the image’s vector quantized latent space. Because unCLIP models often beat other SOTA models in several composition benchmarks, such as T2I-CompBench and HRS-Benchmark, the research team concentrates on them in this article. These T2I models, which usually have many parameters, need excellent image-text pairings for training. Compared to LDMs, unCLIP models such as DALL-E-2, Karlo, and Kandinsky have a substantially larger total model size (≥ 2B) due to their previous module, which has about 1 billion parameters.
In that order, the training data for these unCLIP models is 250M, 115M, and 177M image-text pairings. Thus, two important questions remain: 1) Does SOTA performance on text compositions improve using a text-to-image prior? 2) Or is increasing the model’s size the crucial element? By increasing parameter and data efficiency, the research team aims to improve their knowledge of T2I priors and offer significant improvements over current formulations. T2I priors, intended to directly estimate the noiseless image embedding at every timestep of the diffusion process, are also diffusion models, as suggested by prior research. To examine this earlier dissemination process, the research team conducted an empirical investigation.
The research team discovered that the diffusion process marginally degrades the performance and has no effect on producing correct pictures. Furthermore, because diffusion models converge more slowly, training them takes significant GPU hours or days. As a result, the non-diffusion model serves as a substitute in this study. Due to the lack of classifier-free guidance, this method may limit compositional possibilities, but it greatly improves parameter efficiency and lessens data dependencies.
In this study, the research team from Arizona State University presents a unique contrastive learning technique, called ECLIPSE, to enhance the T2I non-diffusion prior and surpass the drawbacks above. The research team enhanced the conventional approach of producing the picture embedding from the provided text embedding by optimizing the Evidence Lower Bound (ELBO). The research team suggests using the pre-trained vision-language models’ semantic alignment (between the text and picture) feature to oversee the earlier training. The research team use a relatively tiny fraction of the image-text pairings (0.34% – 8.69%) to train compact (97% smaller) non-diffusion prior models (with 33 million parameters) using ECLIPSE. The research team introduced ECLIPSE priors for the unCLIP diffusion image decoder variations (Karlo and Kandinsky). The ECLIPSE-trained priors outperform their 1 billion parameter counterparts and outperform baseline prior learning algorithms. Their findings suggest a possible path for T2I generative models that improve compositionality without requiring many parameters or data.
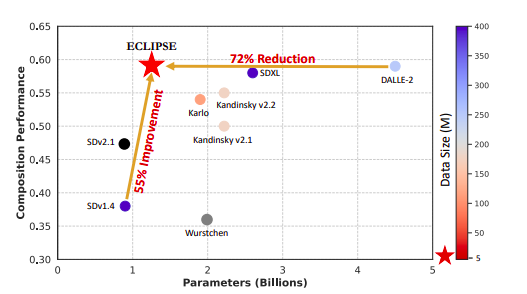
As shown in Fig. 1, their total parameter and data needs significantly decrease, and they attain the SOTA performance versus similar parameter models by increasing the T2I before unCLIP families. Contributions. 1) In the unCLIP framework, the research team provides ECLIPSE, the first effort to use contrastive learning for text-to-image priors. 2) The research team proved the superiority of ECLIPSE over baseline priors in resource-constrained contexts through comprehensive experimentation. 3) It is noteworthy that ECLIPSE priors require just 2.8% of the training data and 3.3% of the model parameters to get performance equivalent to bigger models. 4) The research team also examines the drawbacks of current T2I diffusion priors and provides empirical observations.
Check out the Paper and Project. All credit for this research goes to the researchers of this project. Also, don’t forget to join our 33k+ ML SubReddit, 41k+ Facebook Community, Discord Channel, and Email Newsletter, where we share the latest AI research news, cool AI projects, and more.
If you like our work, you will love our newsletter..
The post This AI Research from Arizona State University Unveil ECLIPSE: A Novel Contrastive Learning Strategy to Improve the Text-to-Image Non-Diffusion Prior appeared first on MarkTechPost.
#AIShorts #Applications #ArtificialIntelligence #ComputerVision #EditorsPick #MachineLearning #Staff #TechNews #Technology #Uncategorized [Source: AI Techpark]