


The seamless integration of vision and language has been a focal point of recent advancements in AI. The field has seen significant progress with the advent of LLMs. Yet, developing vision and vision-language foundation models essential for multimodal AGI systems still need to catch up. This gap has led to the creation of a groundbreaking model proposed by researchers from Nanjing University, OpenGVLab, Shanghai AI Laboratory, The University of HongKong, The Chinese University of Hong Kong, Tsinghua University, University of Science and Technology of China, SenseTime Research known as InternVL, which scales up vision foundation models and aligns them for generic visual-linguistic tasks.
InternVL addresses a critical issue in the realm of artificial intelligence: the disparity in the development pace between vision foundation models and LLMs. Existing models often use basic glue layers to align vision and language features, resulting in a mismatch in parameter scales and representation consistency. This inadequacy can hinder the full potential of LLMs.
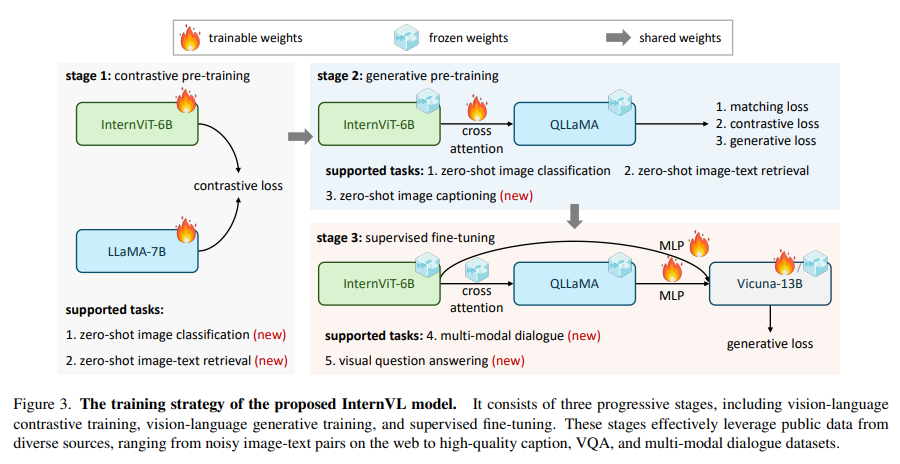
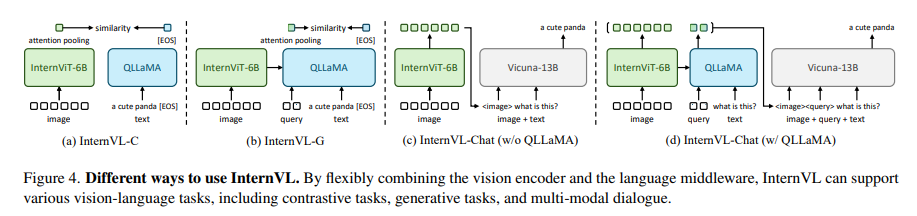
The methodology behind InternVL is both unique and robust. The model employs a large-scale vision encoder, InternViT-6B, and a language middleware, QLLaMA, with 8 billion parameters. This structure serves a dual purpose: it functions as an independent vision encoder for perception tasks. It collaborates with the language middleware for complex vision-language tasks and multimodal dialogue systems. The model’s training involves a progressive alignment strategy, starting with contrastive learning on extensive noisy image-text data and then moving to generative learning with more refined data. This progressive approach consistently improves the model’s performance across various tasks.
InternVL demonstrates its prowess by outperforming existing methods in 32 generic visual-linguistic benchmarks, a testament to its robust visual capabilities. The model excels in diverse tasks such as image and video classification, image and video-text retrieval, image captioning, visible question answering, and multimodal dialogue. This diverse range of capabilities is attributed to the aligned feature space with LLMs, enabling the model to handle complex tasks with remarkable efficiency and accuracy.
Key aspects of InternVL’s performance include:
- The model is versatile as a standalone vision encoder or combined with the language middleware for various tasks.
- InternVL innovatively overcomes this by scaling the vision foundation model to a remarkable 6 billion parameters, facilitating a more comprehensive and effective integration with LLMs.
- Its ability to achieve state-of-the-art performance across 32 generic visual-linguistic benchmarks highlights its advanced visual capabilities.
- Effective performance in image and video classification, image and video-text retrieval, image captioning, visual question answering, and multimodal dialogue.
- The aligned feature space with LLMs enhances its capacity to seamlessly integrate with existing language models, further broadening its application scope.
In conclusion, the research conducted can be presented in a nutshell in the following points:
- InternVL represents a major leap in multimodal AGI systems, bridging a crucial gap in developing vision and vision-language foundation models.
- Its innovative scaling and alignment strategy endow it with versatility and power, enabling superior performance across various visual-linguistic tasks.
- This research contributes to advancing multimodal large models, potentially reshaping the future landscape of AI and machine learning.
Check out the Paper and Github. All credit for this research goes to the researchers of this project. Also, don’t forget to join our 35k+ ML SubReddit, 41k+ Facebook Community, Discord Channel, and Email Newsletter, where we share the latest AI research news, cool AI projects, and more.
If you like our work, you will love our newsletter..
The post This AI Paper Unveils InternVL: Bridging the Gap in Multi-Modal AGI with a 6 Billion Parameter Vision-Language Foundation Mode appeared first on MarkTechPost.
#AIShorts #Applications #ArtificialIntelligence #ComputerVision #EditorsPick #LanguageModel #MachineLearning #MultimodalAI #Staff #TechNews #Technology #Uncategorized [Source: AI Techpark]