


Singing voice conversion (SVC) is a fascinating domain within audio processing, aiming to transform one singer’s voice into another’s while keeping the song’s content and melody intact. This technology has broad applications, from enhancing musical entertainment to artistic creation. A significant challenge in this field has been the slow processing speeds, especially in diffusion-based SVC methods. While producing high-quality and natural audio, these methods are hindered by their lengthy, iterative sampling processes, making them less suitable for real-time applications.
Various generative models have attempted to address SVC’s challenges, including autoregressive models, generative adversarial networks, normalizing flow, and diffusion models. Each method attempts to disentangle and encode singer-independent and singer-dependent features from audio data, with varying degrees of success in audio quality and processing efficiency.
The introduction of CoMoSVC, a new method developed by the Hong Kong University of Science and Technology and Microsoft Research Asia leveraging the consistency model, marks a notable advancement in SVC. This approach aims to achieve high-quality audio generation and rapid sampling simultaneously. At its core, CoMoSVC employs a diffusion-based teacher model specifically designed for SVC and further refines its process through a student model distilled under self-consistency properties. This innovation enables one-step sampling, a significant leap forward in addressing the slow inference speed of traditional methods.
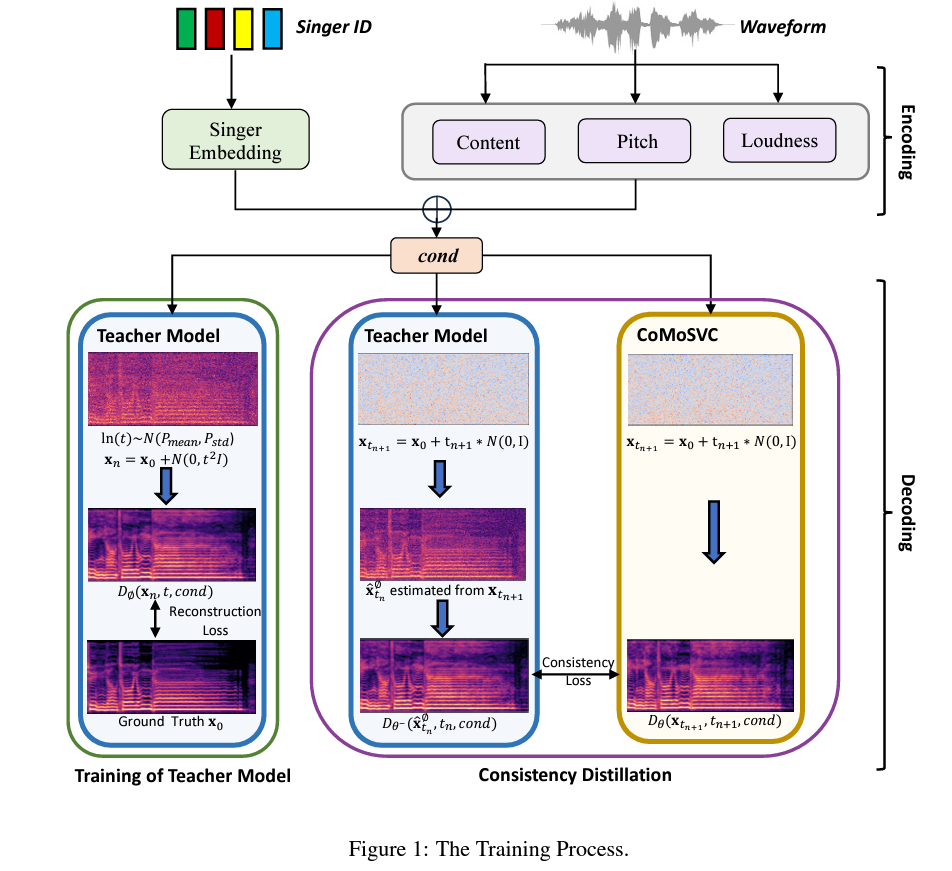
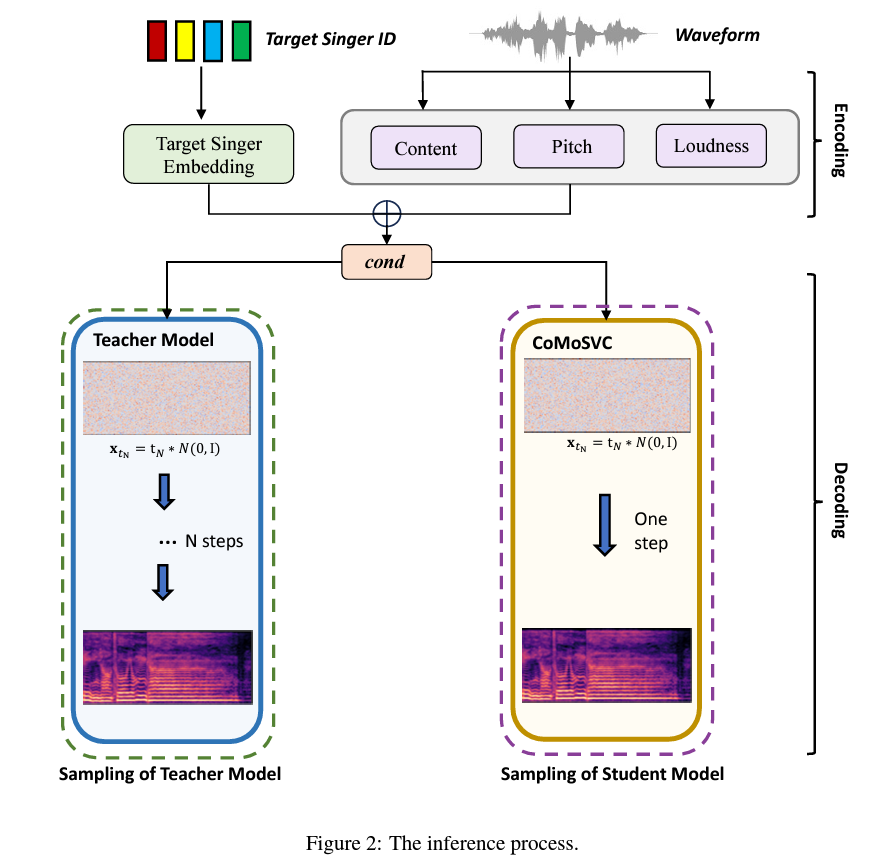
Delving deeper into the methodology, CoMoSVC operates through a two-stage process: encoding and decoding. In the encoding stage, features are extracted from the waveform, and the singer’s identity is encoded into embeddings. The decoding stage is where CoMoSVC truly innovates. It uses these embeddings to generate mel-spectrograms, subsequently rendered into audio. The standout feature of CoMoSVC is its student model, distilled from a pre-trained teacher model. This model enables rapid, one-step audio sampling while preserving high quality, a feat not achieved by previous methods.
In terms of performance, CoMoSVC demonstrates remarkable results. It significantly outpaces state-of-the-art diffusion-based SVC systems in inference speed, up to 500 times faster. Yet, it maintains or surpasses their audio quality and similar performance. Objective and subjective evaluations of CoMoSVC reveal its ability to achieve comparable or superior conversion performance. This balance between speed and quality makes CoMoSVC a groundbreaking development in SVC technology.
In conclusion, CoMoSVC is a significant milestone in singing voice conversion technology. It tackles the critical issue of slow inference speed without compromising audio quality. By innovatively combining a teacher-student model framework with the consistency model, CoMoSVC sets a new standard in the field, offering rapid and high-quality voice conversion that could revolutionize applications in music entertainment and beyond. This advancement solves a long-standing challenge in SVC and opens up new possibilities for real-time and efficient voice conversion applications.
Check out the Paper and Project. All credit for this research goes to the researchers of this project. Also, don’t forget to follow us on Twitter. Join our 35k+ ML SubReddit, 41k+ Facebook Community, Discord Channel, and LinkedIn Group.
If you like our work, you will love our newsletter..
The post This AI Paper Proposes CoMoSVC: A Consistency Model-based SVC Method that Aims to Achieve both High-Quality Generation and High-Speed Sampling appeared first on MarkTechPost.
#AIShorts #Applications #ArtificialIntelligence #EditorsPick #Staff #TechNews #Technology #Uncategorized [Source: AI Techpark]