


AI development is shifting from static, task-centric models to dynamic, adaptable agent-based systems suitable for various applications. AI systems aim to gather sensory data and effectively engage with environments, a longstanding research goal. Developing generalist AI offers advantages, including training a single neural model across multiple tasks and data types. This approach is highly scalable through data, computational resources, and model parameters.
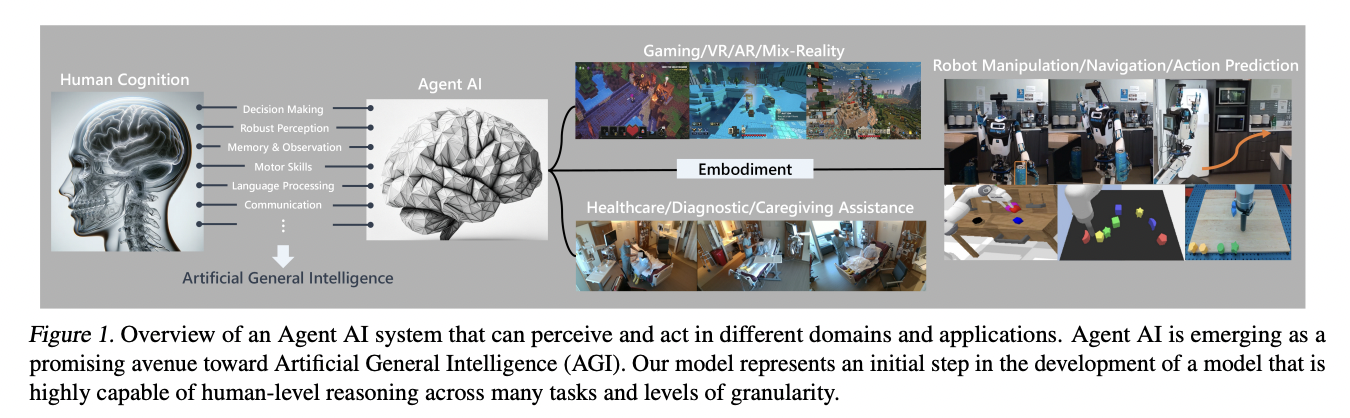
Recent works highlight the advantages of developing generalist AI systems by training a single neural model across various tasks and data types, offering scalability through data, compute, and model parameters. However, challenges persist, as large foundation models often produce hallucinations and infer incorrect information due to insufficient grounding in training environments. Current multimodal system approaches, relying on frozen pre-trained models for each modality, may perpetuate errors without cross-modal pre-training.
Researchers from Stanford University, Microsoft Research, Redmond, and the University of California, Los Angeles, have proposed the Interactive Agent Foundation Model, which introduces a unified pre-training framework for processing text, visual data, and actions, treating each as separate tokens. It utilizes pre-trained language and visual-language models to predict masked tokens across all modalities. It enables interaction with humans and environments, incorporating visual-language understanding. With 277M parameters jointly pre-trained across diverse domains, it engages effectively in multi-modal settings across various virtual environments.
The Interactive Agent Foundation Model initializes its architecture with pre-trained CLIP ViT-B16 for visual encoding and OPT-125M for action and language modeling. It incorporates cross-modal information sharing through a linear layer transformation. Due to memory constraints, previous actions and visual frames are included as input, with a sliding window approach. Sinusoidal positional embeddings are utilized for predicting masked visible tokens. Unlike prior models relying on frozen submodules, the entire model is jointly trained during pre-training.
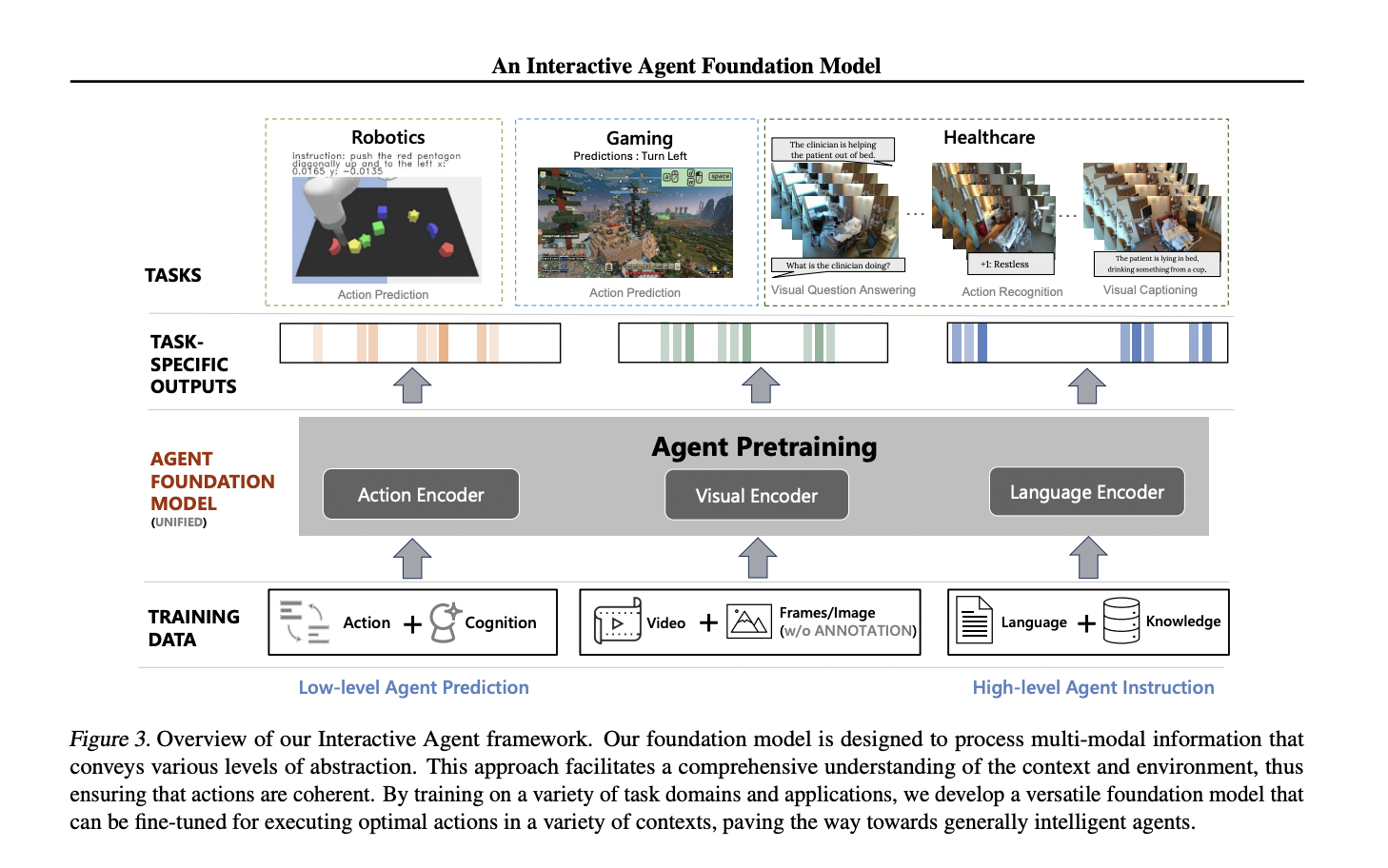
Evaluation across robotics, gaming, and healthcare tasks demonstrates promising results. Despite being outperformed in certain tasks by other models due to less data for pre-training, the method showcases competitive performance, especially in robotics, where it significantly surpasses a comparative model. Fne-tuning the pre-trained model proves notably effective in gaming tasks compared to training from scratch. In healthcare applications, the method outperforms several baselines leveraging CLIP and OPT for initialization, demonstrating the efficacy of its diverse pre-training approach.
In conclusion, Researchers proposed the Interactive Agent Foundation Model, which is adept at processing text, action, and visual inputs and demonstrates effectiveness across diverse domains. Pre-training on a mixture of robotics and gaming data enables the model to proficiently model actions, even exhibiting positive transfer to healthcare tasks during fine-tuning. Its broad applicability across decision-making contexts suggests potential for generalist agents in multimodal systems, unlocking new opportunities for AI advancement.
Check out the Paper. All credit for this research goes to the researchers of this project. Also, don’t forget to follow us on Twitter and Google News. Join our 37k+ ML SubReddit, 41k+ Facebook Community, Discord Channel, and LinkedIn Group.
If you like our work, you will love our newsletter..
Don’t Forget to join our Telegram Channel
The post This AI Paper Proposes an Interactive Agent Foundation Model that Uses a Novel Multi-Task Agent Training Paradigm for Training AI Agents Across a Wide Range of Domains, Datasets, and Tasks appeared first on MarkTechPost.
#AIShorts #Applications #ArtificialIntelligence #EditorsPick #MachineLearning #Staff #TechNews #Technology #Uncategorized [Source: AI Techpark]