


Creating general-purpose assistants that can efficiently carry out various real-world activities by following users’ (multimodal) instructions has long been a goal in artificial intelligence. The area has recently seen increased interest in creating foundation models with emerging multimodal understanding and generating skills in open-world challenges. How to create multimodal, general-purpose assistants for computer vision and vision-language activities still needs to be discovered, despite the effectiveness of employing large language models (LLMs) like ChatGPT to produce general-purpose assistants for natural language tasks.
The current endeavors aimed at creating multimodal agents may be generally divided into two groups:
(i) End-to-end training using LLMs, in which a succession of Large Multimodal Models (LMMs) are created by continuously training LLMs to learn how to interpret visual information using image-text data and multimodal instruction-following data. Both open-sourced models like LLaVA and MiniGPT-4 and private models like Flamingo and multimodal GPT-4 have shown impressive visual understanding and reasoning skills. While these end-to-end training approaches work well for assisting LMMs in acquiring emergent skills (like in-context learning), creating a cohesive architecture that can smoothly integrate a broad range of abilities—like image segmentation and generation—that are essential for multimodal applications in the real world is still a difficult task.
(ii) Tool chaining with LLMs, in which the prompts are carefully designed to allow LLMs to call upon various tools (such as vision models that have already been trained) to do desired (sub-)tasks, all without requiring further model training. VisProg, ViperGPT, Visual ChatGPT, X-GPT, and MM-REACT are well-known works. The strength of these approaches is their ability to handle a wide range of visual tasks using (new) tools that can be developed cheaply and integrated into an AI agent. Prompting, however, needs to be more flexible and reliable to enable multimodal agents to reliably choose and activate the right tools (from a broad and varied toolset) and compose their outcomes to provide final solutions for multimodal tasks in the actual world on the go.
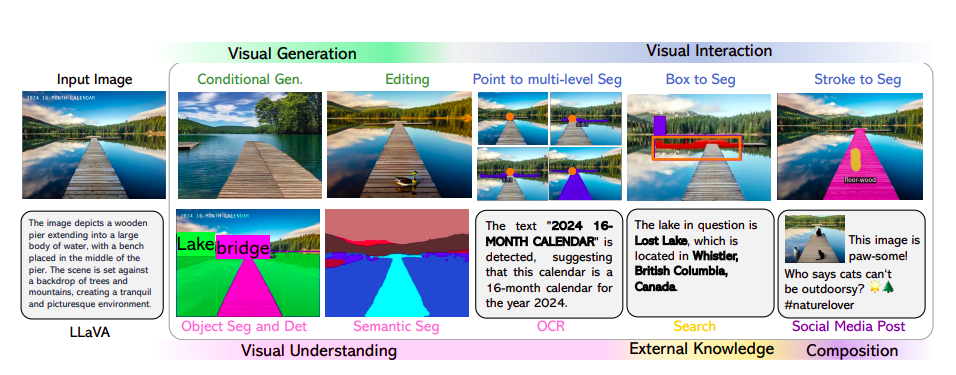
Figure 1: A graphic representation of the possibilities of LLaVA-Plus made possible via skill acquisition.
Researchers from Tsinghua University, Microsoft Research, University of Wisconsin-Madison, HKUST, and IDEA Research in this paper introduce LLaVA-Plus (Large Language and Vision Assistants that Plug and Learn to Use Skills), a multimodal assistant with a broad range of applications that acquires tool usage skills through an end-to-end training methodology that methodically enhances LMMs’ capabilities through visual instruction tweaking. To their knowledge, this is the first documented attempt to combine the advantages of the previously described tool chaining and end-to-end training techniques. The skill repository that comes with LLaVA-Plus has a large selection of vision and vision-language tools. The design is an example of the “Society of Mind” theory, in which individual tools are created for certain tasks and have limited use on their own; nevertheless, when these tools are combined, they provide emergent skills that demonstrate greater intelligence.
For instance, given users’ multimodal inputs, LLaVA-Plus may create a new workflow instantly, choose and activate pertinent tools from the skill library, and assemble the outcomes of their execution to complete various real-world tasks that are not visible during model training. Through instruction tweaking, LLaVA-Plus may be enhanced over time by adding additional capabilities or instruments. Consider a brand-new multimodal tool created for a certain use case or ability. To build instruction-following data for tuning, they gather relevant user instructions that require this tool along with their execution outcomes or the results that follow. Following instruction tweaking, LLaVA-Plus gains more capabilities as it learns to use this new tool to accomplish jobs previously impossible.
Additionally, LLaVA-Plus deviates from previous studies on tool usage training for LLMs by utilizing visual cues exclusively in conjunction with multimodal tools. On the other hand, LLaVA-Plus enhances LMM’s capacity for planning and reasoning by using unprocessed visual signals for all the human-AI contact sessions. To summarize, the contributions of their paper are as follows:
• Use data for a new multimodal instruction-following tool. Using ChatGPT and GPT-4 as labeling tools, they describe a new pipeline for selecting vision-language instruction-following data that is intended for use as a tool in human-AI interaction sessions.
• A new, large multimodal helper. They have created LLaVA-Plus, a multimodal assistant with a broad range of uses that expands on LLaVA by integrating an extensive and varied collection of external tools that can be quickly chosen, assembled, and engaged to complete tasks. Figure 1 illustrates how LLaVA-Plus greatly expands the possibilities of LMM. Their empirical investigation verifies the efficacy of LLaVA-Plus by showing consistently better results on several benchmarks, especially the new SoTA on VisiT-Bench with a wide range of real-world activities.
• Source-free. The materials they will make publicly available are the produced multimodal instruction data, the codebase, the LLaVA-Plus checkpoints, and a visual chat demo.
Check out the Paper and Project. All credit for this research goes to the researchers of this project. Also, don’t forget to join our 33k+ ML SubReddit, 41k+ Facebook Community, Discord Channel, and Email Newsletter, where we share the latest AI research news, cool AI projects, and more.
If you like our work, you will love our newsletter..
The post This AI Paper Introduces LLaVA-Plus: A General-Purpose Multimodal Assistant that Expands the Capabilities of Large Multimodal Models appeared first on MarkTechPost.
#AIShorts #Applications #ArtificialIntelligence #ComputerVision #EditorsPick #LanguageModel #LargeLanguageModel #MachineLearning #MultimodalAI #Staff #TechNews #Technology #Uncategorized [Source: AI Techpark]