


In the ever-evolving landscape of artificial intelligence, the quest for more advanced and capable language models has been a driving force. Researchers at Shanghai AI Laboratory, SenseTime Group, The Chinese University of Hong Kong, and Fudan University have unveiled InternLM2, a remarkable open–source achievement in Large Language Models (LLMs).
Let’s start by addressing the problem at hand. As the demand for intelligent systems that can understand and generate human-like language grows, the development of LLMs has become a crucial endeavor. These models aim to process and interpret vast amounts of data, enabling them to engage in natural conversations, provide insightful analysis, and even tackle complex tasks.
The researchers behind InternLM2 have taken a multifaceted approach to address this challenge. At the core of their work lies an innovative method for building encoder-decoder models with reusable decoder modules. These modules can be seamlessly applied across diverse sequence generation tasks, ranging from machine translation and automatic speech recognition to optical character recognition.
InternLM2 employs a sophisticated training framework called InternEvo, which enables efficient and scalable model training across thousands of GPUs. This framework leverages a combination of data, tensor, sequence, and pipeline parallelism, coupled with various optimization strategies like Zero Redundancy Optimizer (ZeRO) and mixed-precision training. The result? A significant reduction in the memory footprint required for training, leading to remarkable performance gains.
One of the key innovations in InternLM2 is its ability to handle extended context lengths. By employing Group Query Attention (GQA), the model can infer long sequences with a smaller memory footprint. Additionally, the training process starts with a 4K context corpus and gradually transitions to a 32K context corpus, further enhancing the model’s long-context processing capabilities.
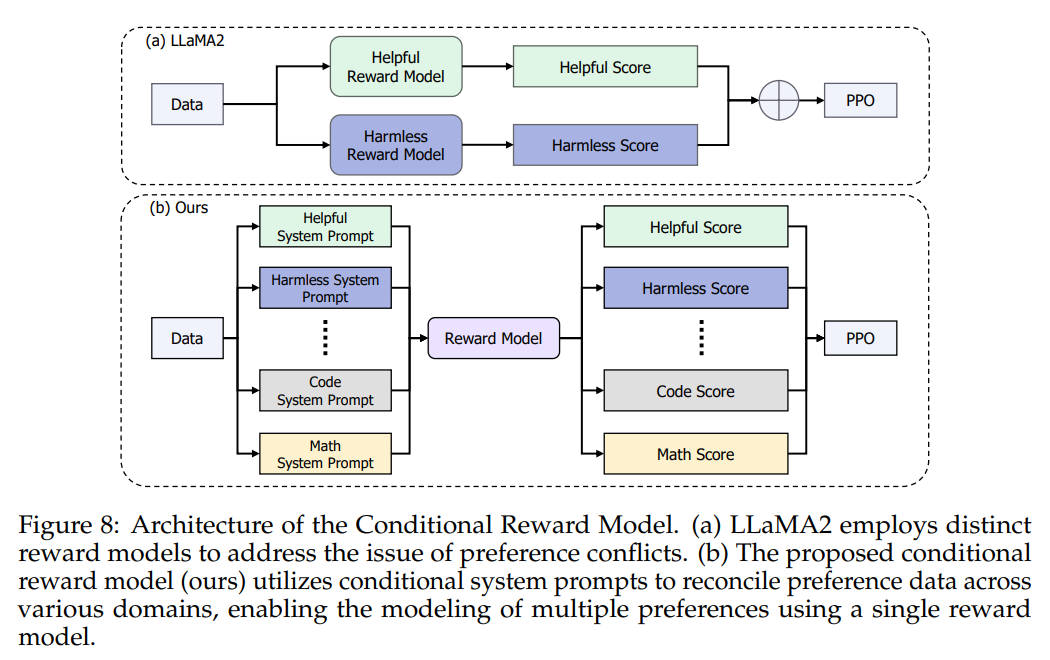
The researchers didn’t stop there. They introduced COnditional OnLine RLHF (COOL RLHF) (shown in Figure 8), a novel approach that addresses the challenges of preference conflicts and reward hacking encountered during the Reinforcement Learning from Human Feedback (RLHF) stage. COOL RLHF employs a conditional reward model to reconcile diverse preferences and executes Proximal Policy Optimization (PPO) over multiple rounds, mitigating emerging reward hacking in each phase.
To evaluate the performance of InternLM2, the researchers conducted comprehensive assessments across various domains and tasks. From comprehensive examinations and reasoning challenges to coding tasks and long-context modeling, InternLM2 demonstrated remarkable prowess. Notably, it excelled in tasks involving language understanding, knowledge application, and commonsense reasoning, making it a promising choice for real-world applications that demand robust language comprehension and extensive knowledge.
Furthermore, InternLM2 showcased its proficiency in tool utilization, a crucial aspect for tackling complex, real-world problems. By leveraging external tools and APIs, the model exhibited impressive performance across benchmark datasets such as GSM8K, Math, MathBench, T-Eval, and CIBench.
Subjective evaluations, including AlpacaEval, MTBench, CompassArena, and AlignBench, further highlighted InternLM2’s exceptional alignment with human preferences. The model achieved state-of-the-art scores, outperforming its counterparts and demonstrating its strong capabilities in areas such as reasoning, roleplay, math, coding, and creativity.
In conclusion, InternLM2 represents a significant stride forward in the development of Large Language Models. With its innovative techniques, scalable training framework, and remarkable performance across a wide range of tasks, this model stands as a testament to the relentless pursuit of pushing the boundaries of artificial intelligence. As researchers continue to refine and advance LLMs, we can anticipate even more groundbreaking achievements that will shape the future of human-machine interaction and problem-solving capabilities.
Check out the Paper. All credit for this research goes to the researchers of this project. Also, don’t forget to follow us on Twitter. Join our Telegram Channel, Discord Channel, and LinkedIn Group.
If you like our work, you will love our newsletter..
Don’t Forget to join our 39k+ ML SubReddit
The post This AI Paper Introduces InternLM2: An Open-Source Large Language Model LLM that Demonstrates Exceptional Performance in both Subjective and Objective Evaluations appeared first on MarkTechPost.
#AIPaperSummary #AIShorts #Applications #ArtificialIntelligence #EditorsPick #LanguageModel #LargeLanguageModel #Staff #TechNews #Technology [Source: AI Techpark]