


In artificial intelligence, the synergy between visual and textual data plays a pivotal role in evolving models capable of understanding and generating content that bridges the gap between these two modalities. Vision-Language Models (VLMs), which leverage vast datasets of paired images and text, are at the forefront of this innovative frontier. These models harness the power of image-text datasets to achieve breakthroughs in various tasks, from enhancing image recognition to pioneering new forms of text-to-image synthesis.
The cornerstone of effective VLMs lies in the quality of the image-text datasets on which they are trained. However, the task of curating these datasets is fraught with challenges. While a rich source of image-text pairs, the internet also introduces much noise. Images often come with irrelevant or misleading descriptions, complicating the training process for models that rely on accurate, well-aligned data. Earlier methods like CLIPScore have attempted to tackle this issue by measuring the alignment between images and texts. Despite their efforts, such methods fail to address the nuanced discrepancies within these pairs, particularly with complex images or lengthy descriptions that go beyond simple object recognition.
A collaborative team from the University of California Santa Barbara and Bytedance has uniquely harnessed the capabilities of Multimodal Language Models (MLMs). Their solution focuses on filtering image-text data, a novel approach that introduces a nuanced scoring system for data quality evaluation, offering a more refined assessment than its predecessors.
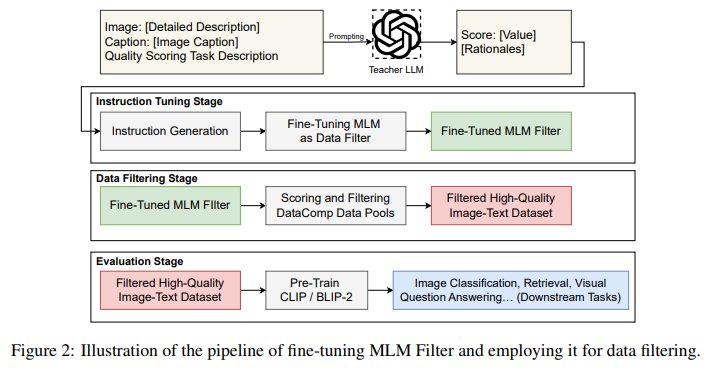
The methodology behind this groundbreaking work involves a sophisticated pipeline designed to generate high-quality instruction data for fine-tuning MLMs. The team identified four critical metrics to evaluate the quality of image-text pairs: Image-Text Matching, Object Detail Fulfillment, Caption Text Quality, and Semantic Understanding. Each metric targets a specific aspect of data quality, from the relevance and detail of textual descriptions to the semantic richness they bring to the accompanying images. This multi-faceted approach ensures a comprehensive assessment, addressing the diverse data quality challenges in a way that single-metric systems like CLIPScore cannot.
The research demonstrates significant improvements in the quality of datasets prepared for VLM training through rigorous testing and comparison with existing filtering methods. The MLM filter surpasses traditional methods in aligning images with their textual counterparts and enhances the overall efficacy of the foundation models trained on these filtered datasets. This leap in performance is evident across various tasks, showcasing the filter’s versatility and potential to serve as a universal tool in data curation.
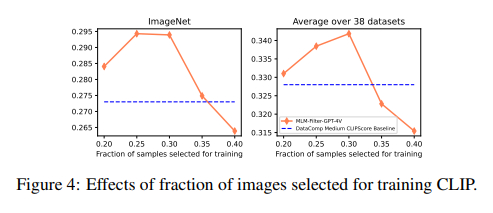
In conclusion, the contributions of this research are manifold, presenting a leap forward in the development of VLMs and the quality of multimodal datasets:
- A groundbreaking framework for fine-tuning MLMs to filter image-text data, significantly outperforming existing methods in data quality assessment.
- The research introduces a comprehensive scoring system that evaluates the quality of image-text pairs across four distinct metrics. This approach addresses the multifaceted nature of data quality in a way that single-metric systems cannot, providing a comprehensive assessment.
- The proposed MLM filter has demonstrated remarkable improvements in the performance of VLMs trained on datasets. Through rigorous testing and comparison with existing filtering methods, the research showcases the filter’s potential to enhance the overall efficacy of the foundation models, marking a significant leap in performance.
Check out the Paper and Project. All credit for this research goes to the researchers of this project. Also, don’t forget to follow us on Twitter and Google News. Join our 38k+ ML SubReddit, 41k+ Facebook Community, Discord Channel, and LinkedIn Group.
If you like our work, you will love our newsletter..
Don’t Forget to join our Telegram Channel
You may also like our FREE AI Courses….
The post This AI Paper from UCSD and ByteDance Proposes a Novel Machine Learning Framework for Filtering Image-Text Data by Leveraging Fine-Tuned Multimodal Language Models (MLMs) appeared first on MarkTechPost.
#AIPaperSummary #AIShorts #Applications #ArtificialIntelligence #ComputerVision #EditorsPick #LanguageModel #LargeLanguageModel #Staff #TechNews #Technology #Uncategorized [Source: AI Techpark]