


With diffusion models, the field of text-to-image generation has made significant advances. However, current models frequently use CLIP as their text encoder, which restricts their capacity to comprehend complicated prompts with many items, minute details, complex relationships, and broad text alignment. To overcome these challenges, the Efficient Large Language Model Adapter (ELLA), a novel method, is presented in this study. By integrating powerful Large Language Models (LLMs) into text-to-image diffusion models, ELLA enhances them without requiring U-Net or LLM training. A significant innovation is the Timestep-Aware Semantic Connector (TSC), a module that dynamically extracts conditions that vary with timestep from the LLM that has already been trained. ELLA helps interpret long and complex prompts by modifying semantic features at several denoising phases.
In recent years, diffusion models have been the primary motivation behind text-to-image generation, producing aesthetically pleasing and text-relevant images. However, common models, including variations based on CLIP, have difficulties with dense prompts, which limits their ability to handle intricate connections and thorough descriptions of many items. As a lightweight alternative, ELLA improves on current models by smoothly incorporating potent LLMs, which eventually boosts prompt-following capabilities and makes it possible to comprehend long, dense texts without the need for LLM or U-Net training.
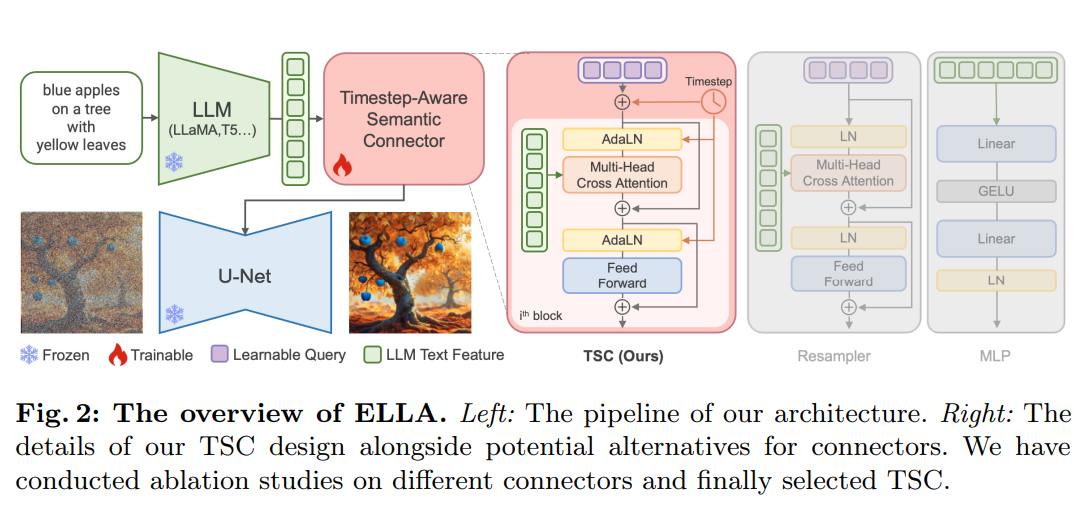
Pre-trained LLMs such as T5, TinyLlama, or LLaMA-2 are integrated with a TSC in ELLA’s architecture to provide semantic alignment throughout the denoising process. TSC automatically adjusts semantic characteristics at various denoising stages depending on the resampler architecture. Timestep information is added to TSC, which improves its dynamic text feature extraction capability and enables better conditioning of the frozen U-Net at different semantic levels.
The paper introduces the Dense Prompt Graph Benchmark (DPG-Bench), which consists of 1,065 long, dense prompts, to evaluate text-to-image models’ performance on dense prompts. The dataset provides a more thorough evaluation than current benchmarks by evaluating semantic alignment capabilities in addressing difficult and information-rich cues. Furthermore, ELLA’s suitability for use with current community models and downstream tools is showcased, offering a promising avenue for further improvement.
The paper offers a perceptive summary of relevant research in the fields of compositional text-to-image diffusion models, text-to-image diffusion models, and their shortcomings when it comes to following intricate instructions. It sets the foundation for ELLA’s creative contributions by highlighting the shortcomings of CLIP-based models and the significance of adding powerful LLMs like T5 and LLaMA-2 to existing models.
Using LLMs as text encoders, ELLA’s design introduces the TSC for dynamic semantic alignment. In-depth tests are carried out in the research, whereby ELLA is compared with the most sophisticated models on dense prompts using DPG-Bench and short compositional questions on a subset of T2I-CompBench. The results show that ELLA is superior, especially in complex prompt following, compositions with many objects, and various attributes and relationships.
The influence of various LLM options and alternative architecture designs on ELLA’s performance is investigated using ablation research. The robustness of the suggested method is demonstrated by the strong impact of the TSC module’s design and the selection of LLM on the model’s comprehension of both simple and complex prompts.

ELLA effectively improves text-to-image creation, allowing models to understand intricate prompts without involving retraining of LLM or U-Net. The paper admits its shortcomings, such as frozen U-Net constraints and MLLM sensitivity. It recommends directions to pursue future studies, including resolving issues and investigating additional MLLM integration with diffusion models.
In conclusion, ELLA represents an important advancement in the industry, opening the door to enhanced text-to-image generating capabilities without requiring much retraining, eventually leading to more efficient and versatile models in this domain.
Check out the Paper and Github. All credit for this research goes to the researchers of this project. Also, don’t forget to follow us on Twitter. Join our Telegram Channel, Discord Channel, and LinkedIn Group.
If you like our work, you will love our newsletter..
Don’t Forget to join our 38k+ ML SubReddit
The post This AI Paper from Tencent Introduces ELLA: A Machine Learning Method that Equips Current Text-to-Image Diffusion Models with State-of-the-Art Large Language Models without the Training of LLM and U-Net appeared first on MarkTechPost.
#AIPaperSummary #AIShorts #Applications #ArtificialIntelligence #EditorsPick #LanguageModel #LargeLanguageModel #Staff #TechNews #Technology #Uncategorized [Source: AI Techpark]