


Large-scale generative models like GPT-4, DALL-E, and Stable Diffusion have transformed artificial intelligence, demonstrating remarkable capabilities in generating text, images, and other media. However, as these models become more prevalent, a critical challenge emerges the consequences of training generative models on datasets containing their outputs. This issue, known as model collapse, poses a significant threat to the future development of AI. As generative models are trained on web-scale datasets that increasingly include AI-generated content, researchers are struggling with the potential degradation of model performance over successive iterations, potentially rendering newer models ineffective and compromising the quality of training data for future AI systems.
Existing researchers have investigated model collapse through various methods, including replacing real data with generated data, augmenting fixed datasets, and mixing real and synthetic data. Most studies maintained constant dataset sizes and mixing proportions. Theoretical work has focused on understanding model behavior with synthetic data integration, analyzing high-dimensional regression, self-distillation effects, and language model output tails. Some researchers identified phase transitions in error scaling laws and proposed mitigation strategies. However, these studies primarily considered fixed training data amounts per iteration. Few explored the effects of accumulating data over time, closely resembling evolving internet-based datasets. This research gap highlights the need for further investigation into the long-term consequences of training models on continuously expanding datasets that include both real and synthetic data, reflecting the dynamic nature of web-scale information.
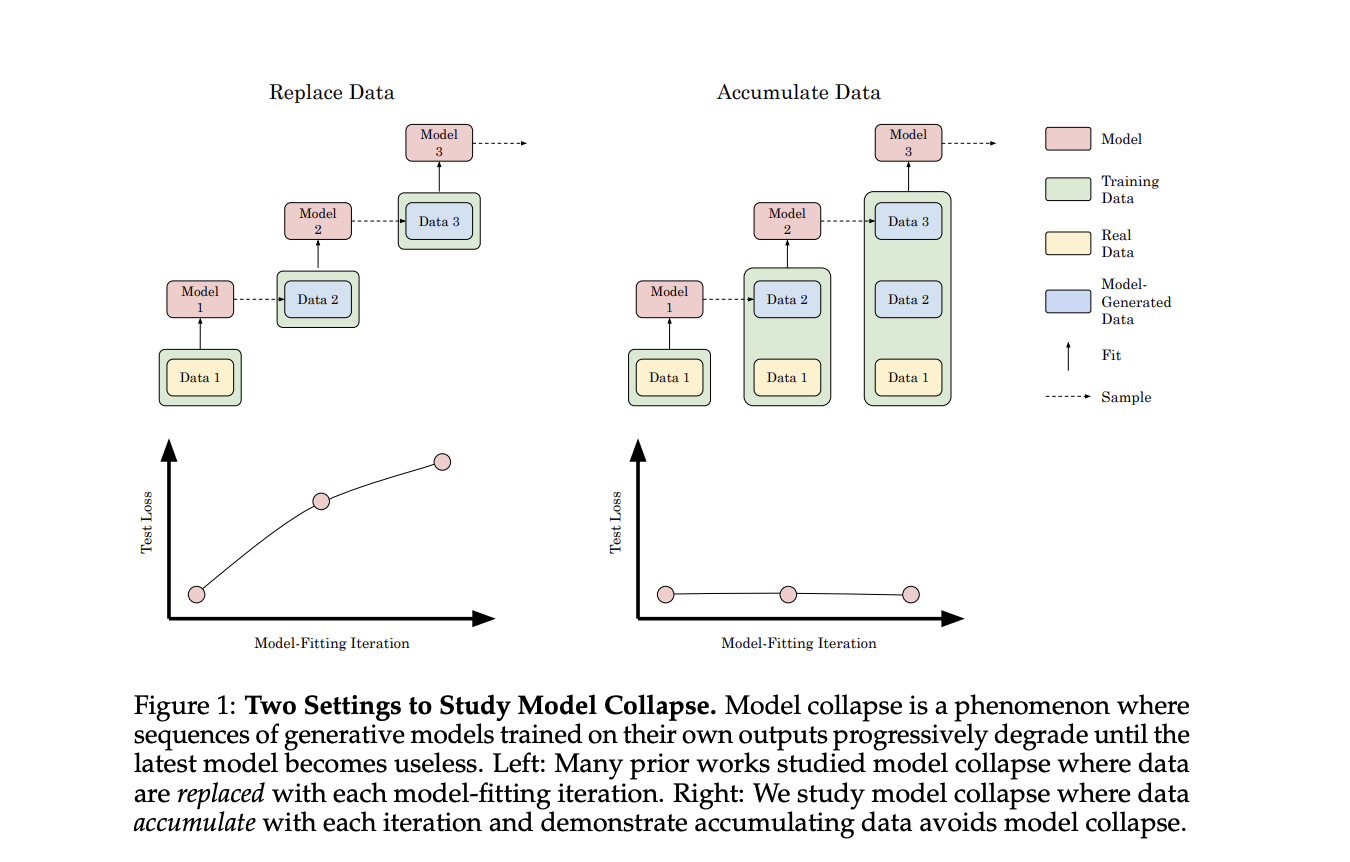
Researchers from Stanford University propose a study that explores the impact of accumulating data on model collapse in generative AI models. Unlike previous research focusing on data replacement, this approach simulates the continuous accumulation of synthetic data in internet-based datasets. Experiments with transformers, diffusion models, and variational autoencoders across various data types reveal that accumulating synthetic data with real data prevents model collapse, in contrast to the performance degradation observed when replacing data. The researchers extend existing analysis of sequential linear models to prove that data accumulation results in a finite, well-controlled upper bound on test error, independent of model-fitting iterations. This finding contrasts with the linear error increase seen in data replacement scenarios.
Researchers experimentally investigated model collapse in generative AI using causal transformers, diffusion models, and variational autoencoders across text, molecular, and image datasets.
- Transformer-Based Causal Language Modeling:
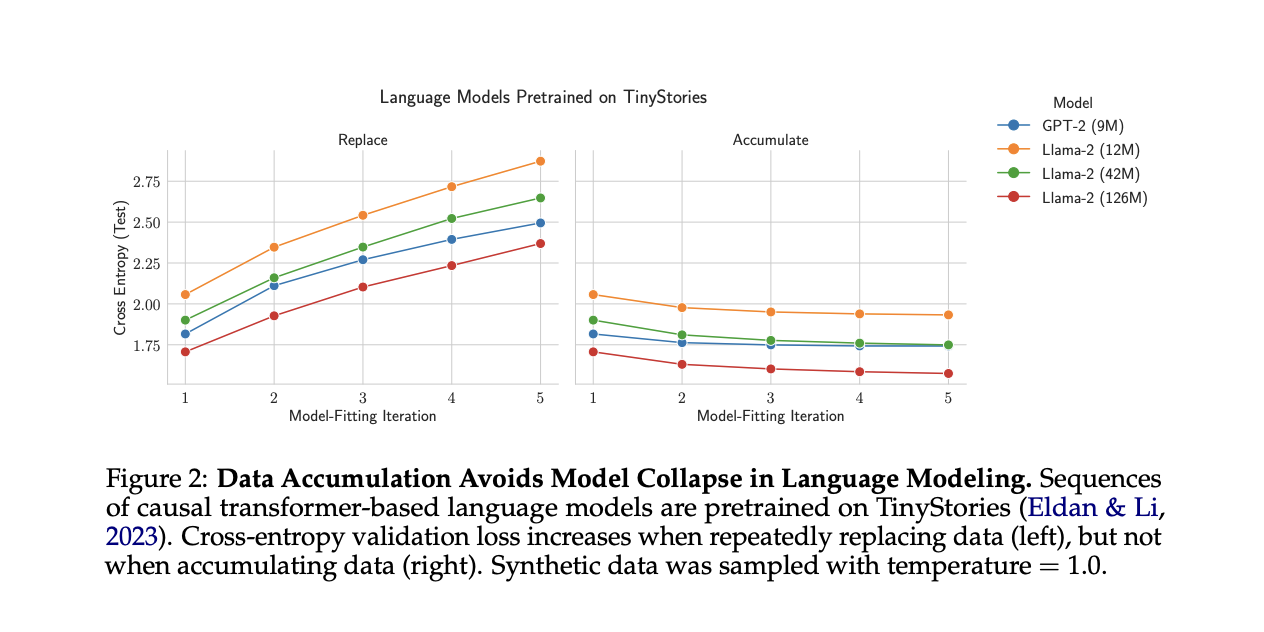
To test the model collapse in transformer-based language models researchers used GPT-2 and Llama2 architectures of various sizes, pre-trained on TinyStories. They compared data replacement and accumulation strategies over multiple iterations. Results consistently showed that replacing data increased test cross-entropy (worse performance) across all model configurations and sampling temperatures. In contrast, accumulating data maintained or improved performance over iterations. Lower sampling temperatures accelerated error increases when replacing data, but the overall trend remained consistent. These findings strongly support the hypothesis that data accumulation prevents model collapse in language modeling tasks, while data replacement leads to progressive performance degradation.
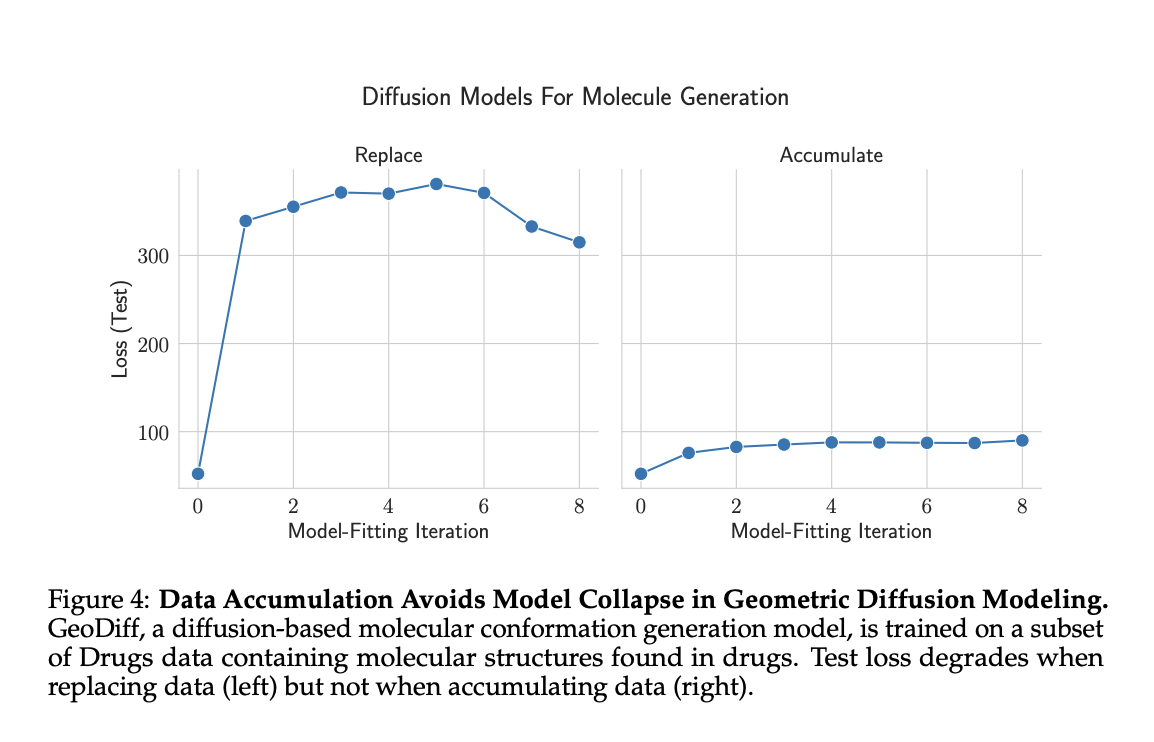
- Diffusion Models on Molecular Conformation Data:
Researchers tested GeoDiff diffusion models on GEOM-Drugs molecular conformation data, comparing data replacement and accumulation strategies. Results showed increasing test loss when replacing data, but stable performance when accumulating data. Unlike language models, significant degradation occurred mainly in the first iteration with synthetic data. These findings further support data accumulation as a method to prevent model collapse across different AI domains.
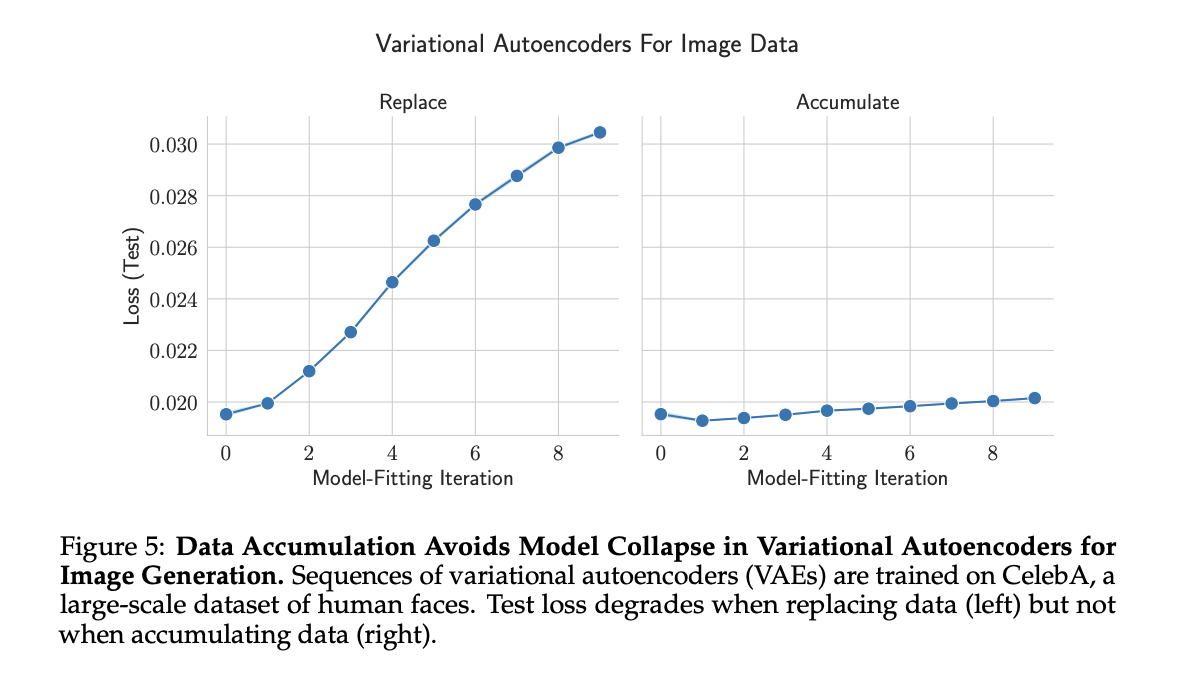
- Variational Autoencoders on Image Data (VAE)
Researchers used VAEs on CelebA face images, comparing data replacement and accumulation strategies. Replacing data led to rapid model collapse, with increasing test error and decreasing image quality and diversity. Accumulating data significantly slowed collapse, preserving major variations but losing minor details over iterations. Unlike language models, accumulation showed slight performance degradation. These findings support data accumulation’s benefits in mitigating model collapse across AI domains while highlighting variations in effectiveness depending on model type and dataset.

This research investigates model collapse in AI, a concern as AI-generated content increasingly appears in training datasets. While previous studies showed that training on model outputs can degrade performance, this work demonstrates that model collapse can be prevented by training on a mixture of real and synthetic data. The findings, supported by experiments across various AI domains and theoretical analysis for linear regression, suggest that the “curse of recursion” may be less severe than previously thought, as long as synthetic data is accumulated alongside real data rather than replacing it entirely.
Check out the Paper. All credit for this research goes to the researchers of this project. Also, don’t forget to follow us on Twitter and join our Telegram Channel and LinkedIn Group.
If you like our work, you will love our newsletter..
Don’t Forget to join our 47k+ ML SubReddit
Find Upcoming AI Webinars here
The post This AI Paper from Stanford Provides New Insights on AI Model Collapse and Data Accumulation appeared first on MarkTechPost.
#AIPaperSummary #AIShorts #Applications #ArtificialIntelligence #EditorsPick #MachineLearning #Staff #TechNews #Technology [Source: AI Techpark]