


Embedding models are fundamental tools in natural language processing (NLP), providing the backbone for applications like information retrieval and retrieval-augmented generation. These models transform the text into a numerical format that machines can process, which is crucial for understanding and manipulating language. Traditionally, these models are restricted by a narrow context window, typically handling no more than 512 tokens. This limitation restricts their use in scenarios demanding the analysis of extended documents, such as legal contracts or detailed academic reviews.
Existing research in NLP embedding models has progressively focused on extending context capabilities. Early models like BERT utilized absolute position embedding (APE), while more recent innovations like RoFormer and LLaMA incorporate rotary position embedding (RoPE) for handling longer texts. Notable models such as Longformer and BigBird leverage sparse attention mechanisms to process extended documents efficiently. These advancements underscore the evolution from traditional embeddings to sophisticated models capable of managing significantly larger sequences, enhancing the applicability of NLP across various complex and lengthy text processing scenarios.
Researchers from Peking University and Microsoft have proposed LongEmbed, a method to extend the context window of embedding models up to 32,000 tokens without additional training. This method uniquely employs position interpolation and RoPE, differentiating it by its capacity to efficiently manage significantly larger text sequences while maintaining the model’s baseline performance on shorter inputs.
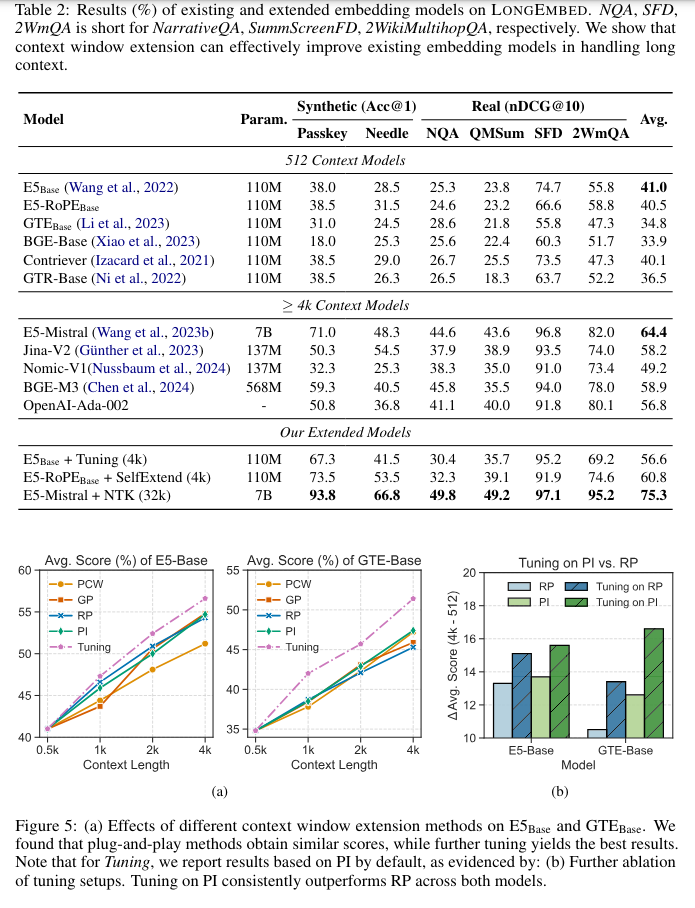
Specifically, the methodology detailed in the study centers around two primary strategies: position interpolation and rotary position embedding (RoPE). These techniques are applied to existing models, notably E5Base and GTEBase, to extend their context-handling capabilities. The position interpolation method extends the models’ original context window by linearly interpolating existing position embeddings. Meanwhile, RoPE is implemented to enhance the scalability of handling longer sequences. The effectiveness of these methods is evaluated on the LongEmbed benchmark, specifically designed for this research, and includes both synthetic and real-world tasks aimed at testing extended context capabilities across diverse document lengths.
The benchmarking results from the LongEmbed framework indicate significant improvements in model performance. Models utilizing the extended context window demonstrated a 20% increase in retrieval accuracy on documents exceeding 4,000 tokens compared to their standard configurations. Moreover, models enhanced with RoPE saw an average accuracy gain of 15% across all tested document lengths. These quantitative findings confirm that the applied methodologies preserve the original model efficiencies for shorter texts and substantially improve their applicability and precision for extended text sequences.
To conclude, the research introduced LongEmbed, a method that significantly extends the context window of NLP embedding models without requiring retraining. By integrating position interpolation and rotary position embedding, the research successfully expands model capacities to process texts up to 32,000 tokens, enhancing retrieval accuracy and applicability in real-world scenarios. The effectiveness of these methods is validated through comprehensive benchmark testing, confirming that these innovations enable existing models to handle extended texts efficiently, making them more versatile and applicable to a broader range of tasks.
Check out the Paper and Github. All credit for this research goes to the researchers of this project. Also, don’t forget to follow us on Twitter. Join our Telegram Channel, Discord Channel, and LinkedIn Group.
If you like our work, you will love our newsletter..
Don’t Forget to join our 40k+ ML SubReddit
The post This AI Paper from Peking University and Microsoft Proposes LongEmbed to Extend NLP Context Windows appeared first on MarkTechPost.
#AIPaperSummary #AIShorts #Applications #ArtificialIntelligence #EditorsPick #LanguageModel #LargeLanguageModel #Staff #TechNews #Technology [Source: AI Techpark]