


The exploration into refining the reasoning of large language models (LLMs) marks a significant stride in artificial intelligence research, spearheaded by a team from FAIR at Meta alongside collaborators from Georgia Institute of Technology and StabilityAI. These researchers have embarked on an ambitious journey to enhance LLMs’ ability to self-improve their reasoning processes on challenging tasks such as mathematics, science, and coding without relying on external inputs.
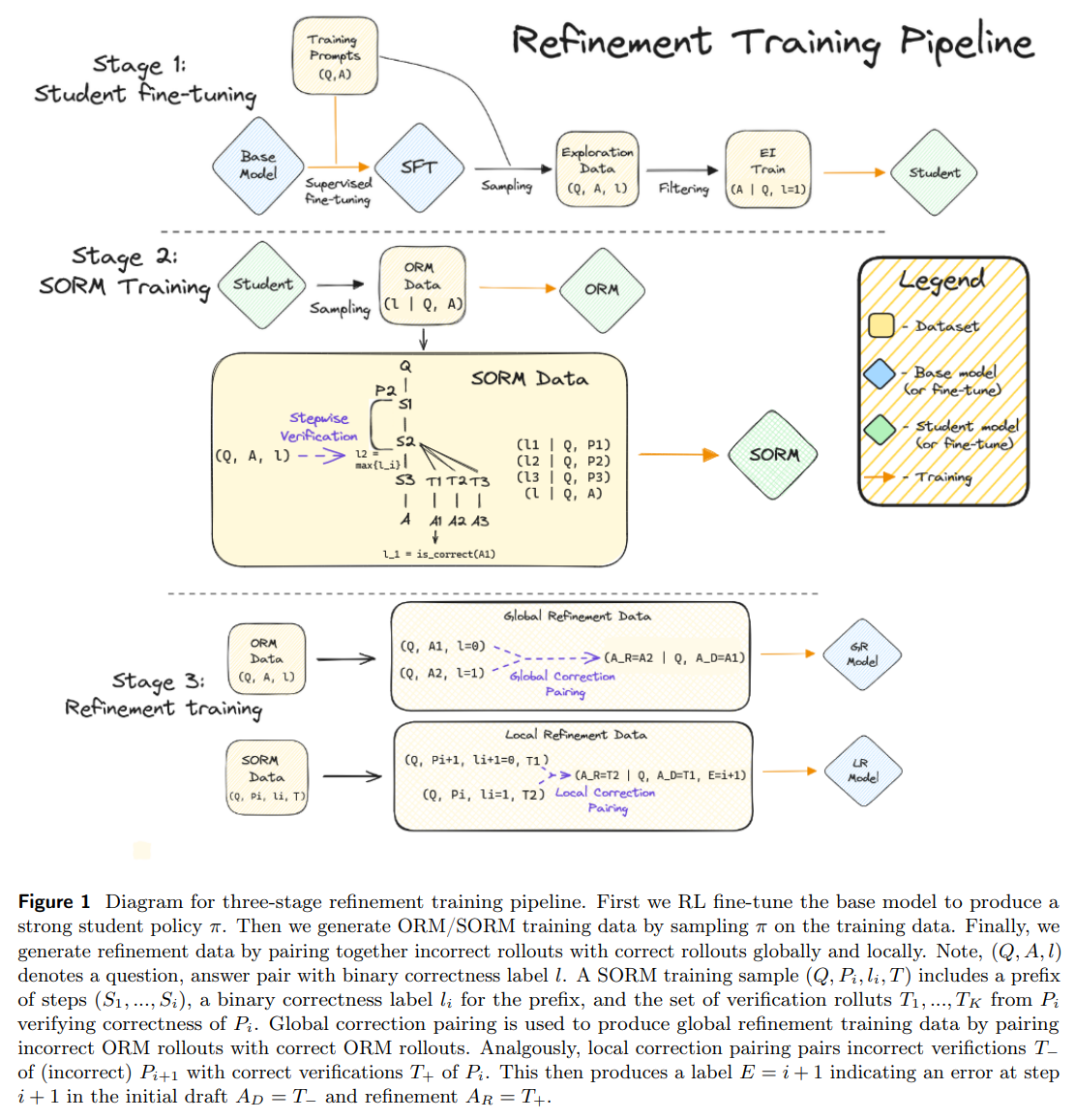
Traditionally, LLMs, despite their sophistication, often need to improve in identifying precisely when and how their reasoning needs refinement. This gap led to the development of Outcome-based Reward Models (ORMs), tools designed to predict the accuracy of a model’s final answer, hinting at when an adjustment is necessary. Yet, a critical observation made by the team was ORMs’ limitations: they were found to be overly cautious, prompting unnecessary refinements even when the model’s reasoning steps were on the right track. This inefficiency prompted a deeper inquiry into more targeted refinement strategies.
Meet Stepwise ORMs (SORMs), the novel proposition by the research team. Unlike their predecessors, SORMs are adept at scrutinizing the correctness of each reasoning step, leveraging synthetic data for training. This precision allows for a more nuanced approach to refinement, distinguishing accurately between valid and erroneous reasoning steps, thereby streamlining the refinement process.
The methodology employed by the team involves a dual refinement model: global and local. The global model assesses the question and a preliminary solution to propose a refined answer, while the local model zeroes in on specific errors highlighted by a critique. This bifurcation allows for a more granular approach to correction, addressing both broad and pinpoint inaccuracies in reasoning. Training data for both models is synthetically generated, ensuring a robust foundation for the system’s learning process.
The culmination of this research is a striking improvement in LLM reasoning accuracy. The team documented a remarkable uplift in performance metrics through rigorous testing, particularly evident in applying their method to the LLaMA-2 13B model. On a challenging math problem known as GSM8K, the accuracy leaped from 53% to an impressive 65% when the models were applied in a combined global-local refinement strategy, underscored by the ORM’s role as a decision-maker in selecting the most promising solution.
This breakthrough signifies an advancement in LLM refinement techniques and the broader context of AI’s problem-solving capabilities. The research illuminates a path toward more autonomous, efficient, and intelligent systems by delineating when and where refinements are needed and implementing a strategic correction methodology. The success of this approach, evidenced by the substantial improvement in problem-solving accuracy, is a testament to the potential of synthetic training and the innovative use of reward models.
Furthermore, the research offers a blueprint for future explorations into LLM refinement, suggesting avenues for refining the models’ error identification processes and enhancing the sophistication of correction strategies. With this foundation, the possibility of LLMs achieving near-human or even superior reasoning abilities on complex tasks is brought closer to reality.
The work done by the team from FAIR at Meta, along with their academic collaborators, stands as a beacon of innovation in AI research. It propels the capabilities of LLMs forward and opens up new horizons for the application of AI in solving some of the most perplexing problems facing various scientific and technological fields today. This research, therefore, is not just a milestone in AI development but a stepping stone towards the future of intelligent computing.
Check out the Paper. All credit for this research goes to the researchers of this project. Also, don’t forget to follow us on Twitter and Google News. Join our 38k+ ML SubReddit, 41k+ Facebook Community, Discord Channel, and LinkedIn Group.
If you like our work, you will love our newsletter..
Don’t Forget to join our Telegram Channel
You may also like our FREE AI Courses….
The post This AI Paper from Meta AI Explores Advanced Refinement Strategies: Unveiling the Power of Stepwise Outcome-based and Process-based Reward Models appeared first on MarkTechPost.
#AIShorts #Applications #ArtificialIntelligence #EditorsPick #Staff #TechNews #Technology #Uncategorized [Source: AI Techpark]