


The challenge of tailoring general-purpose LLMs to specific tasks without extensive retraining or additional data persists even after significant advancements in the field. Adapting LMs for specialized tasks often requires substantial computational resources and domain-specific data. Traditional methods involve finetuning the entire model on task-specific datasets, which can be computationally expensive and data-intensive, creating a barrier for applications with limited resources or those requiring rapid deployment across various tasks.
Current approaches to model adaptation involve rejection sampling, one of the methods used for reward maximization, but it involves high training and inference costs. Another approach is to use rejection sampling with finetuning or distillation to reduce inference costs. Iterative finetuning is an interesting direction for future work. Prompting is a training-free adaptation method, but finetuning still outperforms prompting methods.
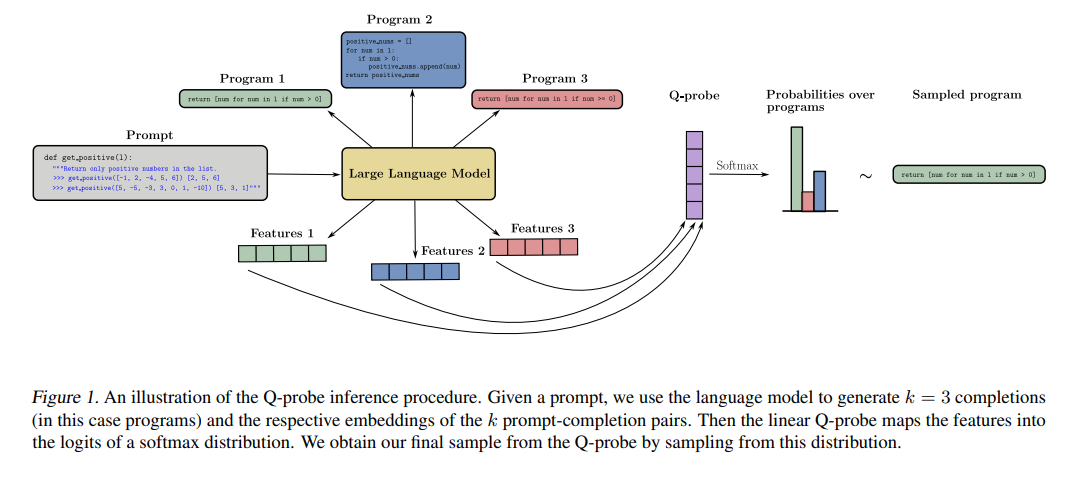
Researchers from Harvard University introduced Q-Probe, which presents a novel method for adapting pre-trained LMs to maximize task-specific rewards efficiently. It employs a simple linear function within the model’s embedding space to reweight candidate completions, aiming for a balance between the depth of finetuning and the simplicity of prompting. This method significantly reduces computational overhead while retaining the model’s adaptability to various tasks.
Q-Probe operates by applying a form of rejection sampling to the LM’s outputs, utilizing a linear probe to assess and prioritize completions based on their projected utility. Reward modeling or direct policy learning objectives based on importance-weighted policy gradients can be used to train the Q-Probes. Q-Probe can be trained on top of an API, as it only requires access to sampling and embeddings. At inference, it is used to generate samples through rejection sampling. It predicts a value for each embedding, determining the logits for a softmax distribution used to sample the chosen completion. The sampling procedure is equivalent to a KL-constrained maximization of the Q-Probe as the number of samples increases. This method has shown gains in domains with ground-truth rewards and implicit rewards defined by preference data, even outperforming finetuning in data-limited regimes.
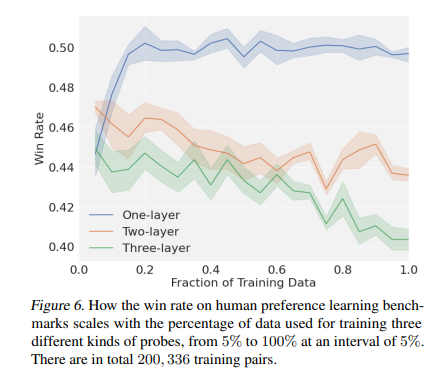
The application of Q-Probe has demonstrated promising results, especially in domains such as code generation, where it has shown potential to surpass traditional finetuning methods in accuracy and efficiency. It outperforms methods like PPO (offline) and DPO while performing on par with KTO when evaluated on human preference data. The process achieves a high “win rate” compared to the winning completion in the data for each prompt, as judged by GPT-4. The win rate increases with the number of samples generated during inference. When the base model is swapped with the KTO-finetuned model, Q-Probe on the KTO-finetuned model outperforms either KTO alone or Q-Probing on the base model. These results show the applicability of the proposed inference-time algorithm with existing finetuning methods.
In summary, Q-Probe represents a significant advancement in the field of LM adaptation, providing an efficient and effective means of tailoring general-purpose models to specific tasks. Bridging the gap between extensive finetuning and simple prompting opens new avenues for applying LMs across a wider range of domains, enhancing their utility and accessibility.
Check out the Paper and Github. All credit for this research goes to the researchers of this project. Also, don’t forget to follow us on Twitter and Google News. Join our 38k+ ML SubReddit, 41k+ Facebook Community, Discord Channel, and LinkedIn Group.
If you like our work, you will love our newsletter..
Don’t Forget to join our Telegram Channel
You may also like our FREE AI Courses….
The post This AI Paper from Harvard Introduces Q-Probing: A New Frontier in Machine Learning for Adapting Pre-Trained Language Models appeared first on MarkTechPost.
#AIShorts #Applications #ArtificialIntelligence #EditorsPick #LanguageModel #LargeLanguageModel #MachineLearning #Staff #TechNews #Technology #Uncategorized [Source: AI Techpark]