


Natural Language Processing (NLP) focuses on the interaction between computers and humans through natural language. It encompasses tasks such as translation, sentiment analysis, and question answering, utilizing large language models (LLMs) to achieve high accuracy and performance. LLMs are employed in numerous applications, from automated customer support to content generation, showcasing remarkable proficiency in diverse tasks.
Evaluating large language models (LLMs) is resource-intensive, requiring significant computational power, time, and financial investment. The challenge lies in efficiently identifying the top-performing models or methods from a plethora of options without exhausting resources on full-scale evaluations. Practitioners often must select the optimal model, prompt, or hyperparameters from hundreds of available choices for their specific needs. Traditional methods involve evaluating multiple candidates on entire test sets, which can be costly and time-consuming.
Existing approaches involve exhaustive evaluation of models on entire datasets, which could be more cost-effective. Techniques like prompt engineering and hyperparameter tuning necessitate extensive testing of multiple configurations to identify the best-performing setup, leading to high resource consumption. For example, the AlpacaEval project benchmarks over 200 models against a diverse set of 805 questions, requiring significant investments in time and computing resources. Similarly, evaluating 153 models in the Chatbot Arena requires extensive computational power, highlighting the inefficiency of current methods.
Researchers from Cornell University and the University of California, San Diego, introduced two algorithms, UCB-E and UCB-E-LRF, leveraging multi-armed bandit frameworks combined with low-rank factorization. These methods dynamically allocate evaluation resources, focusing on promising method-example pairs to significantly reduce the required evaluations and associated costs. The multi-armed bandit approach sequentially selects the next method-example pair to evaluate based on previous evaluations, optimizing the selection process.
The UCB-E algorithm extends classical multi-armed bandit principles to select the most promising method-example pairs for evaluation based on upper confidence bounds. At each step, it estimates the upper confidence bound of each method and picks the one with the highest bound for the next evaluation. This approach ensures efficient resource allocation, focusing on methods more likely to perform well. UCB-E-LRF incorporates low-rank factorization to estimate unobserved scores, further optimizing the selection process and improving efficiency in identifying the best method. By leveraging the intrinsic low-rankness of scoring matrices, UCB-E-LRF predicts the remaining unobserved method-example pairs and prioritizes evaluations of pairs with large uncertainties.

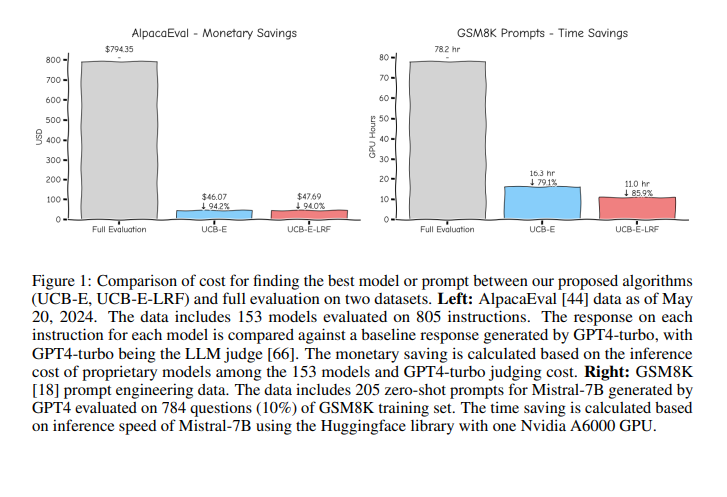
The proposed algorithms substantially reduced evaluation costs, identifying top-performing methods using only 5-15% of the required resources. Experiments showed an 85-95% reduction in cost compared to traditional exhaustive evaluations, proving the effectiveness and efficiency of these new approaches. For instance, evaluating 205 zero-shot prompts on 784 GSM8K questions using Mistral-7B required only 78.2 Nvidia A6000 GPU hours, showcasing significant resource savings. Furthermore, UCB-E and UCB-E-LRF achieved high precision in identifying the best methods. UCB-E-LRF particularly exceling in more challenging settings where the method set is large or performance gaps are small.
Overall, the research addresses the critical problem of resource-intensive LLM evaluations by introducing efficient algorithms that reduce evaluation costs while maintaining high accuracy in identifying top-performing methods. This advancement holds significant potential for streamlining NLP model development and deployment processes. By focusing on promising methods and leveraging low-rank factorization, the researchers have provided a robust solution to the challenge of efficient LLM evaluation. This breakthrough can significantly impact the field of NLP, enabling more effective and cost-efficient model evaluations.
Check out the Paper. All credit for this research goes to the researchers of this project. Also, don’t forget to follow us on Twitter.
Join our Telegram Channel and LinkedIn Group.
If you like our work, you will love our newsletter..
Don’t Forget to join our 46k+ ML SubReddit
The post This AI Paper from Cornell Introduces UCB-E and UCB-E-LRF: Multi-Armed Bandit Algorithms for Efficient and Cost-Effective LLM Evaluation appeared first on MarkTechPost.
#AIPaperSummary #AIShorts #Applications #ArtificialIntelligence #EditorsPick #Staff #TechNews #Technology [Source: AI Techpark]