


Optical flow estimation, a cornerstone of computer vision, enables predicting per-pixel motion between consecutive images. This technology fuels advancements in numerous applications, from enhancing action recognition and video interpolation to improving autonomous navigation and object tracking systems. Traditionally, progress in this domain has been propelled by developing more complex models that promise higher accuracy. However, this approach presents a significant challenge: as models grow in complexity, they demand more computational resources and diverse training data to generalize across different environments.

Addressing this issue, a groundbreaking methodology introduces a compact yet powerful model for efficient optical flow estimation. The method pivots on a spatial recurrent encoder network that utilizes a novel Partial Kernel Convolution (PKConv) mechanism. This innovative strategy allows processing features across varying channel counts within a single shared network, thus significantly reducing model size and computational demands. PKConv layers are adept at producing multi-scale features by selectively processing parts of the convolution kernel, enabling the model to efficiently capture essential details from images.
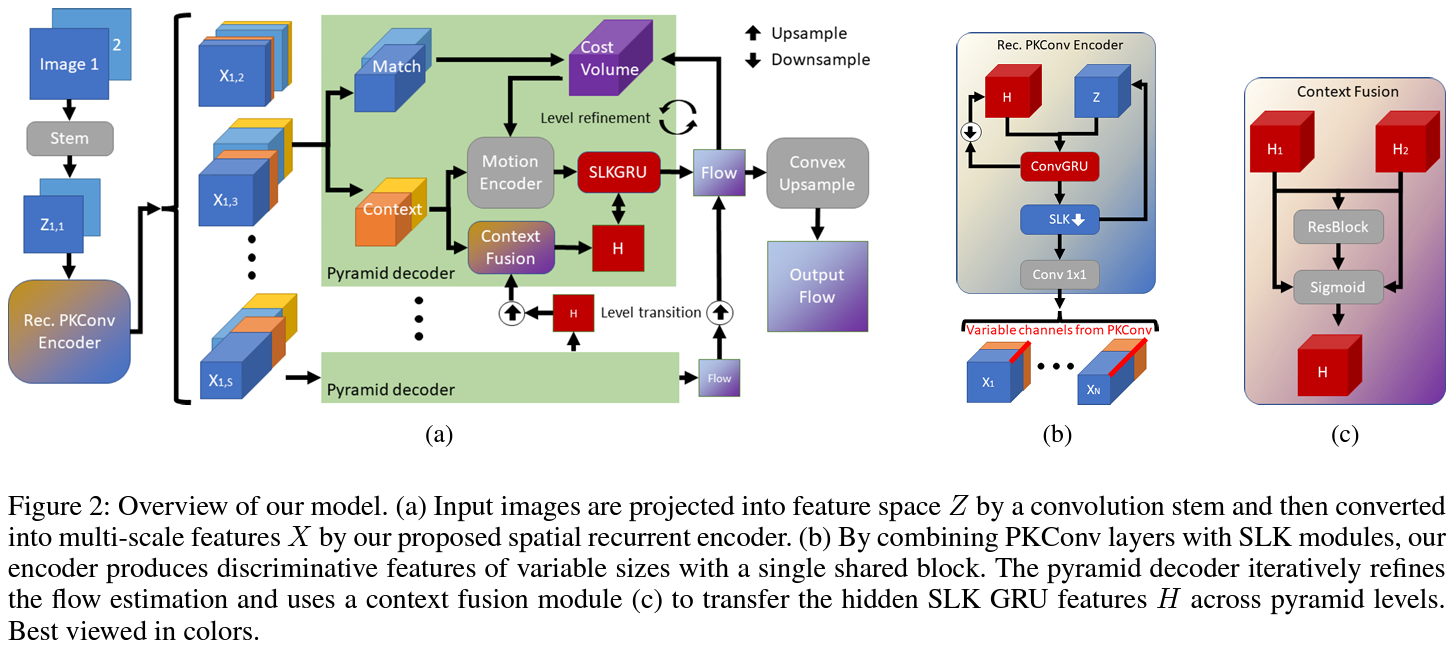
The brilliance of this approach lies in its unique combination of PKConv with Separable Large Kernel (SLK) modules. These modules are engineered to efficiently grasp broad contextual information through large 1D convolutions, facilitating the model’s ability to understand and predict motion accurately while maintaining a lean computational profile. This architectural design effectively balances the need for detailed feature extraction and computational efficiency, setting a new standard in the field.
Empirical evaluations of this method have demonstrated its exceptional capability to generalize across various datasets, a testament to its robustness and adaptability. Notably, the model achieved unparalleled performance on the Spring benchmark, outperforming existing methods without dataset-specific tuning. This achievement highlights the model’s capacity to deliver accurate optical flow predictions in diverse and challenging scenarios, marking a significant advancement in the quest for efficient and reliable motion estimation techniques.
Furthermore, the model’s efficiency does not come at the expense of performance. Despite its compact size, it ranks first in generalization performance on public benchmarks, showing a substantial improvement over traditional methods. This efficiency is particularly evident in its low computational cost and minimal memory requirements, making it an ideal solution for applications where resources are limited.
This research marks a pivotal shift in optical flow estimation, offering a scalable and effective solution that bridges the gap between model complexity and generalization capability. Introducing a spatial recurrent encoder with PKConv and SLK modules represents a significant leap forward, paving the way for developing more advanced computer vision applications. By demonstrating that high efficiency and exceptional performance coexist, this work challenges the conventional wisdom in model design, encouraging future exploration to pursue optimal balance in optical flow technology.
Check out the Paper, Project, and Github. All credit for this research goes to the researchers of this project. Also, don’t forget to follow us on Twitter and Google News. Join our 36k+ ML SubReddit, 41k+ Facebook Community, Discord Channel, and LinkedIn Group.
If you like our work, you will love our newsletter..
Don’t Forget to join our Telegram Channel
The post This AI Paper from China Proposes a Small and Efficient Model for Optical Flow Estimation appeared first on MarkTechPost.
#AIShorts #Applications #ArtificialIntelligence #EditorsPick #LanguageModel #LargeLanguageModel #Staff #TechNews #Technology #Uncategorized [Source: AI Techpark]