


Recent advancements in healthcare leverage LLMs like GPT-4, MedPalm-2 and open-source alternatives such as Llama 2. While these models, including PMC-LLaMA, MedAlpaca, and ChatDoctors, excel in English-language applications and even surpass closed-source counterparts sometimes, their effectiveness in non-English medical queries still needs to be improved. Despite being trained on diverse datasets, multilingual LLMs like BLOOM and InternLM 2 need help with medical inquiries in non-English languages due to their training data’s scarcity of medical content. This discrepancy hampers their potential impact on linguistically diverse communities.
Researchers from the Shanghai Jiao Tong University and Shanghai AI Laboratory have developed an open-source, multilingual language model for medicine that benefits a wider, linguistically diverse audience from different regions. It presents contributions in three aspects: constructing a new multilingual medical corpus for training, proposing a multilingual medical multi-choice question-answering benchmark, and assessing various open-source language models on the benchmark. The final model, MMedLM 2, with 7B parameters, performs better than other open-source models, rivaling GPT-4 on the benchmark.
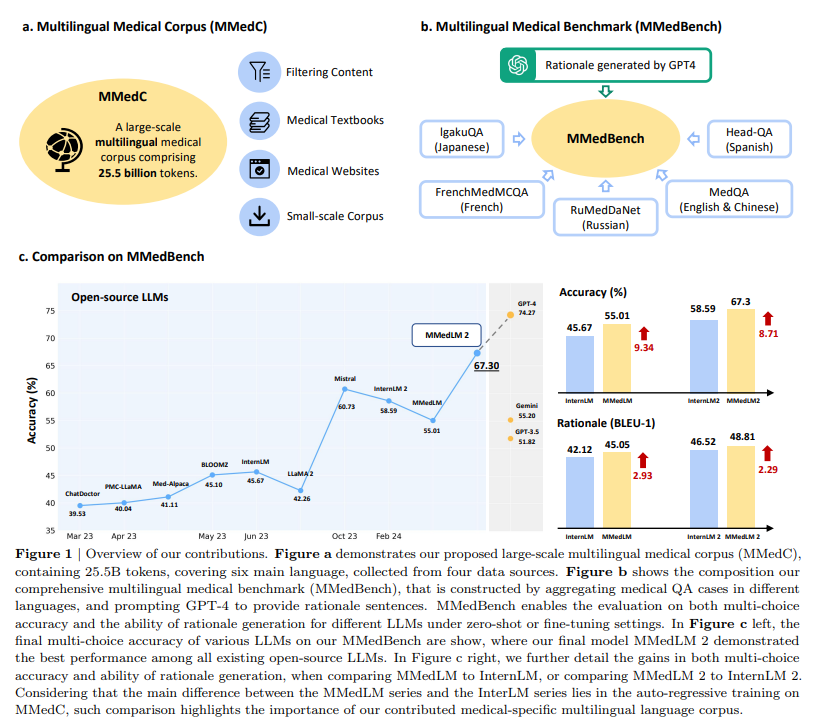
The study mentions a Multilingual Medical Corpus (MMedC) of over 25.5 billion tokens spanning six languages, enabling auto-regressive training. Additionally, they proposed a Multilingual Medical Benchmark (MMedBench) for evaluating models’ question-answering and reasoning abilities. They demonstrated improved performance through comprehensive evaluation across existing models and those further trained on MMedC. The researchers plan to release the dataset, codebase, and models to facilitate future research and underscore the importance of robust evaluation metrics for complex medical text generation.
The methodology consists of three main components: construction of the MMedC, auto-regressive training, and creation of the MMedBench. MMedC is assembled from diverse sources, including filtered medical content from general language corpora, medical textbooks, medical websites, and existing multilingual medical corpora. Auto-regressive training involves pre-training existing LLMs on MMedC. MMedBench is formed by aggregating multilingual medical question-answering datasets and augmenting them with explanations. Evaluation is conducted using three settings: zero-shot, parameter-efficient fine-tuning (PEFT), and full fine-tuning, with metrics including accuracy and rationale similarity, along with human rating.
The study highlights the importance of auto-regressive training on the MMedC for improving LLMs in medical contexts. Incorporating diverse data sources, including high-quality multilingual and general medical data, enhances LLM performance. Additionally, integrating rationale during fine-tuning improves task-specific performance, while stronger foundational LLMs yield better results. Multilingual medical LLMs have significant research and clinical implications, addressing language barriers, cultural sensitivities, and educational needs. However, limitations include the dataset’s language scope and computational constraints, suggesting future expansion and investigation into larger architectures and retrieval augmentation methods to mitigate hallucination flaws.
In conclusion, the study mentions an automated pipeline for constructing a new multilingual medical corpus and benchmark. MMedC comprises 25.5 billion tokens across six major languages, while the MMedBench serves as a comprehensive evaluation benchmark for multilingual medical LLMs. Through extensive experimentation with eleven existing LLMs, the study demonstrates the effectiveness of training on MMedC, bridging the gap between general multilingual LLMs and the intricate medical domain. MMedLM 2, the first and most robust multilingual language model tailored for medicine, is publicly available.
Check out the Paper and Github. All credit for this research goes to the researchers of this project. Also, don’t forget to follow us on Twitter and Google News. Join our 38k+ ML SubReddit, 41k+ Facebook Community, Discord Channel, and LinkedIn Group.
If you like our work, you will love our newsletter..
Don’t Forget to join our Telegram Channel
You may also like our FREE AI Courses….
The post This AI Paper from China Developed an Open-source and Multilingual Language Model for Medicine appeared first on MarkTechPost.
#AIShorts #Applications #ArtificialIntelligence #EditorsPick #LanguageModel #LargeLanguageModel #Staff #TechNews #Technology #Uncategorized [Source: AI Techpark]