


The significant computational demands of large language models (LLMs) have hindered their adoption across various sectors. This hindrance has shifted attention towards compression techniques designed to reduce the model size and computational needs without major performance trade-offs. This pivot is crucial in Natural Language Processing (NLP), facilitating applications from document classification to advanced conversational agents. A pressing concern in this transition is ensuring compressed models maintain robustness towards minority subgroups in datasets defined by specific labels and attributes.
Previous works have focused on Knowledge Distillation, Pruning, Quantization, and Vocabulary Transfer, which aim to retain the essence of the original models in much smaller footprints. Similar efforts have been made to explore the effects of model compression on classes or attributes in images, such as imbalanced classes and sensitive attributes. These approaches have shown promise in maintaining overall performance metrics; however, their impact on the nuanced metric of subgroup robustness still needs to be explored.
A research team from the University of Sussex, BCAM Severo Ochoa Strategic Lab on Trustworthy Machine Learning, Monash University, and expert.ai have proposed a comprehensive investigation into the effects of model compression on the subgroup robustness of BERT language models. The study uses MultiNLI, CivilComments, and SCOTUS datasets to explore 18 different compression methods, including knowledge distillation, pruning, quantization, and vocabulary transfer.
The methodology employed in this study involved training each compressed BERT model using Empirical Risk Minimization (ERM) with five distinct initializations. The aim was to gauge the models’ efficacy through metrics like average accuracy, worst-group accuracy (WGA), and overall model size. Different datasets required tailored approaches for fine-tuning, involving variable epochs, batch sizes, and learning rates specific to each. For methods involving vocabulary transfer, an initial phase of masked-language modeling was conducted before the fine-tuning process, ensuring the models were adequately prepared for the compression’s impact.
Findings highlight significant variances in model performance across different compression techniques. For instance, in the MultiNLI dataset, models like TinyBERT6 outperformed the baseline BERTBase model, showcasing an 85.26% average accuracy with a notable 72.74% worst-group accuracy (WGA). Conversely, when applied to the SCOTUS dataset, a stark performance drop was observed, with some models’ WGA collapsing to 0%, indicating a critical threshold of model capacity for effectively managing subgroup robustness.
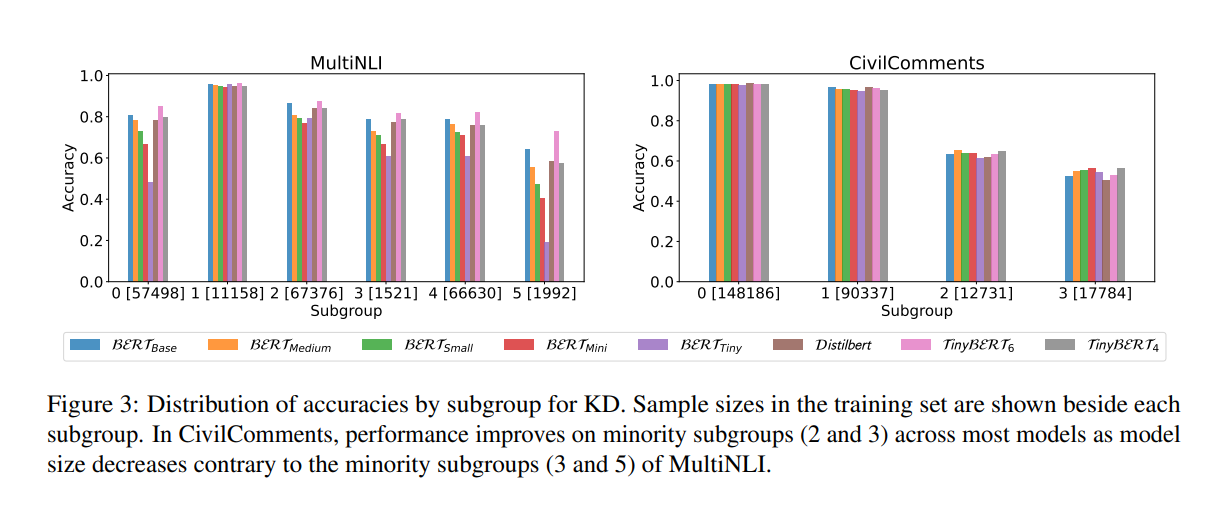
To conclude, this research sheds light on the nuanced impacts of model compression techniques on the robustness of BERT models towards minority subgroups across several datasets. The analysis highlighted that compression methods can improve the performance of language models on minority subgroups, but this effectiveness can vary depending on the dataset and weight initialization after compression. The study’s limitations include focusing on English language datasets and not considering combinations of compression methods.
Check out the Paper. All credit for this research goes to the researchers of this project. Also, don’t forget to follow us on Twitter. Join our Telegram Channel, Discord Channel, and LinkedIn Group.
If you like our work, you will love our newsletter..
Don’t Forget to join our 39k+ ML SubReddit
The post This AI Paper Explores the Impact of Model Compression on Subgroup Robustness in BERT Language Models appeared first on MarkTechPost.
#AIPaperSummary #AIShorts #Applications #ArtificialIntelligence #EditorsPick #LanguageModel #LargeLanguageModel #MachineLearning #Staff #TechNews #Technology [Source: AI Techpark]