


Transformers have taken over from recurrent neural networks (RNNs) as the preferred architecture for natural language processing (NLP). Transformers stand out conceptually because they directly access each token in a sequence, unlike RNNs that rely on maintaining a recurring state of past inputs. Decoders have emerged as a prominent variant within the realm of transformers. These decoders commonly produce output in an auto-regressive manner, meaning the generation of each token is influenced by the key and value computations of preceding tokens.
Researchers from The Hebrew University of Jerusalem and FAIR, AI at Meta, have demonstrated that the auto-regressive nature of transformers aligns with the fundamental principle of RNNs, which involves preserving a state from one step to the next. They formally redefine decoder-only transformers as multi-state RNNs (MSRNN), presenting a generalized version of traditional RNNs. This redefinition highlights that as the number of previous tokens increases during decoding, transformers become MSRNNs with infinite states. The researchers further show that transformers can be compressed into finite MSRNNs by limiting the number of tokens processed at each step. They introduce TOVA, a compression policy for MSRNNs, which selects tokens to retain based solely on their attention scores. The evaluation of TOVA is conducted on four long-range tasks.
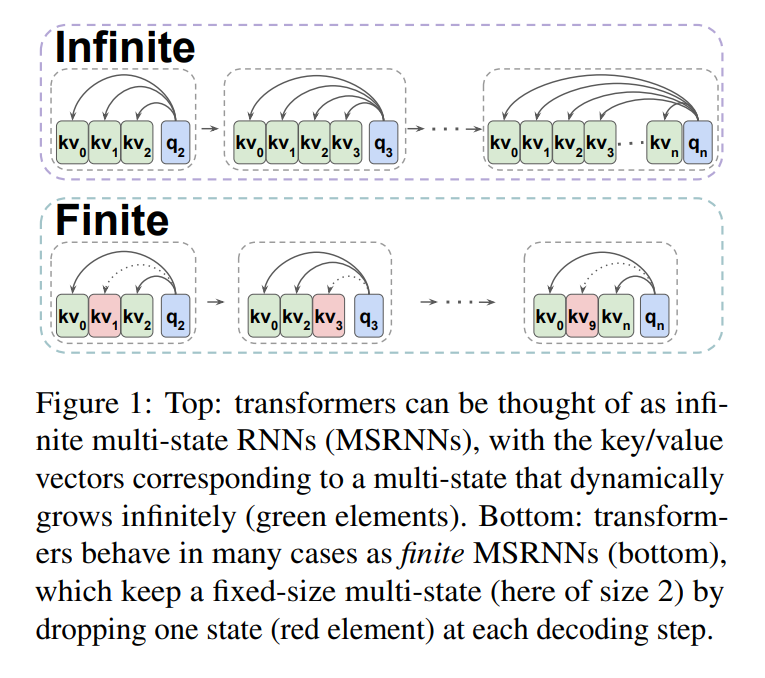
The study compares transformers and RNNs, demonstrating that decoder-only transformers can be conceptualized as infinite multi-state RNNs, and pretrained transformers can be converted into finite multi-state RNNs by fixing the size of their hidden state. It reports perplexity on the PG-19 test set for language modeling. It uses test sets from the ZeroSCROLLS benchmark for evaluating long-range understanding, including long-range summarization and long-range question-answering tasks. The study mentions using the QASPER dataset for long text question answering and evaluating generated stories using GPT-4 as an evaluator.
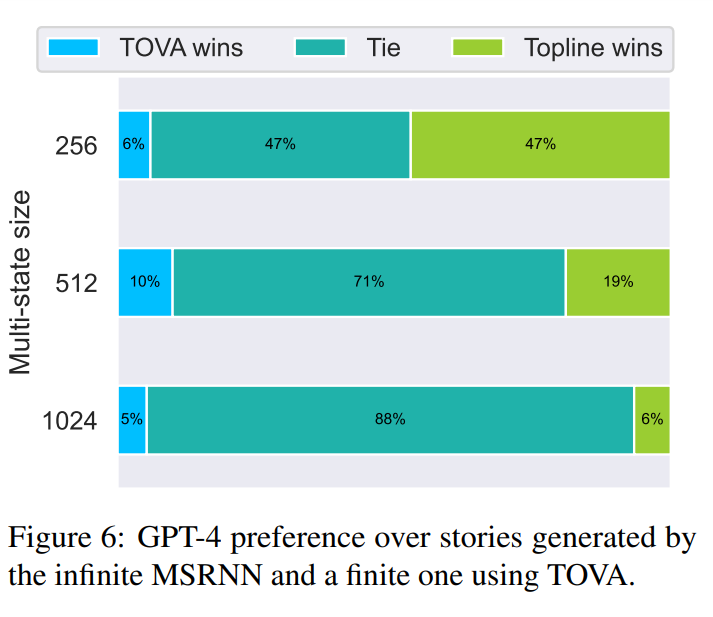
The study demonstrates that decoder-only transformers can be conceptualized as infinite multi-state RNNs, and pretrained transformers can be converted into finite multi-state RNNs by fixing the size of their hidden state. The study also mentions modifying the attention mask to incorporate different MSRNN policies, such as the First In First Out (FIFO) strategy, to effectively parallel the language modeling task. The researchers use the GPT-4 model to evaluate the generated texts and compare the output of the TOVA policy with the topline model.
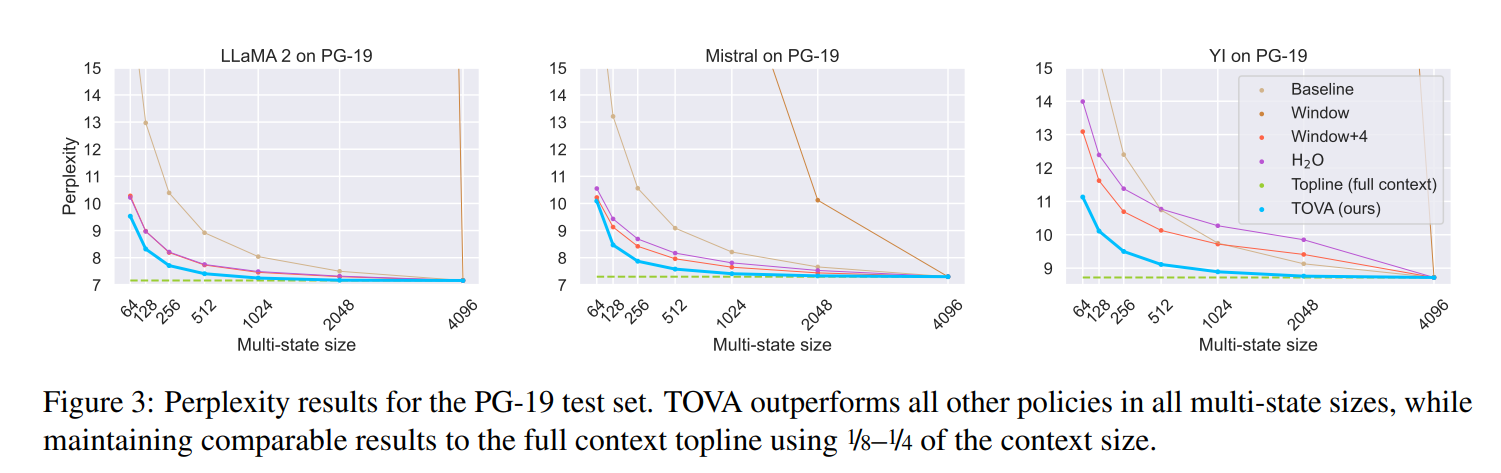
The study demonstrates that transformer decoder LLMs behave as finite MSRNNs even though they are trained as infinite MSRNNs. The proposed TOVA policy performs consistently better than other policies in long-range tasks with smaller cache sizes across all multi-state sizes and models. The experiments show that using TOVA with a quarter or even one-eighth of the full context yields results within one point of the topline model in language modeling tasks. The study also reports a significant reduction in LLM cache size, up to 88%, leading to reduced memory consumption during inference. The researchers acknowledge the computational constraints and approximate the infinite MSRNN with a sequence length of 4,096 tokens for extrapolation experiments.
To summarize, the researchers have redefined decoder transformers as multi-state RNNs with an infinite multi-state size. When the number of token representations that transformers can handle at each step is limited, it is the same as compressing it from infinite to finite MSRNNs. The TOVA policy, which is a simple compression method that selects which tokens to keep using their attention scores, has been found to outperform existing compression policies and performs comparably to the infinite MSRNN model with a reduced multi-state size. Although not trained, transformers often function as finite MSRNNs in practice. These findings provide insights into the inter-working of transformers and their connections to RNNs. Also, they have practical value in reducing the LLM cache size by up to 88%.
Check out the Paper. All credit for this research goes to the researchers of this project. Also, don’t forget to follow us on Twitter. Join our 36k+ ML SubReddit, 41k+ Facebook Community, Discord Channel, and LinkedIn Group.
If you like our work, you will love our newsletter..
Don’t Forget to join our Telegram Channel
The post This AI Paper Demonstrates How Decoder-Only Transformers Mimic Infinite Multi-State Recurrent Neural Networks RNNs and Introduces TOVA for Enhanced Efficiency appeared first on MarkTechPost.
#AIShorts #Applications #ArtificialIntelligence #EditorsPick #LanguageModel #LargeLanguageModel #MachineLearning #Staff #TechNews #Technology #Uncategorized [Source: AI Techpark]