


In the ever-evolving landscape of artificial intelligence (AI), the challenge of creating systems that can effectively collaborate in dynamic environments is a significant one. Multi-agent reinforcement learning (MARL) has been a key focus, aiming to teach agents to interact and adapt in such settings. However, these methods often grapple with complexity and adaptability issues, particularly when faced with new situations or other agents. In response to these challenges, this paper from Stanford introduces a novel approach-the ‘Hypothetical Minds’ model. This innovative model leverages large language models (LLMs) to enhance performance in multi-agent environments by simulating how humans understand and predict others’ behaviors.
Traditional MARL techniques often find it hard to deal with ever-changing environments because the actions of one agent can unpredictably affect others. This instability makes learning and adaptation challenging. Existing solutions, like using LLMs to guide agents, have shown some promise in understanding goals and making plans but still need the nuanced ability to interact effectively with multiple agents.
The Hypothetical Minds model offers a promising solution to these issues. It integrates a Theory of Mind (ToM) module into an LLM-based framework. This ToM module empowers the agent to create and update hypotheses about other agents’ strategies, goals, and behaviors using natural language. By continually refining these hypotheses based on new observations, the model adapts its strategies in real time. This real-time adaptability is a key feature that leads to improved performance in cooperative, competitive, and mixed-motive scenarios, providing reassurance about the model’s practicality and effectiveness.
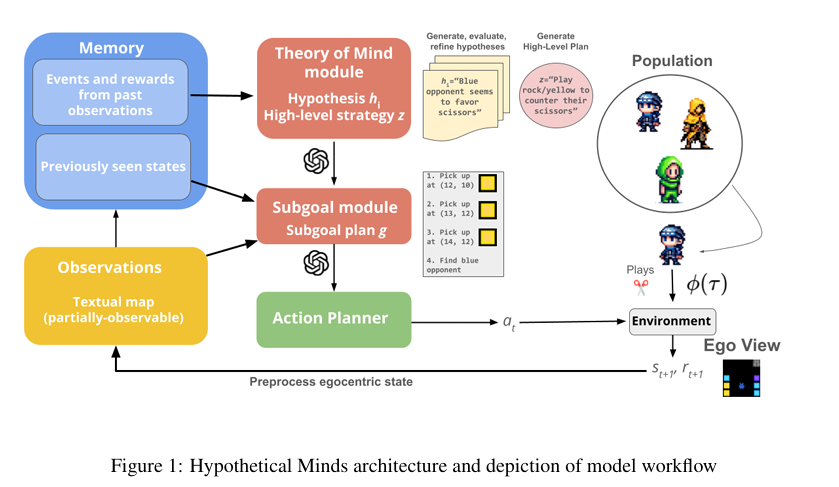
The Hypothetical Minds model is structured around several key components, including perception, memory, and hierarchical planning modules. Central to its function is the ToM module, which maintains a set of natural language hypotheses about other agents. The LLM generates these hypotheses based on the agent’s memory of past observations and the top-valued previously generated hypotheses. This process allows the model to refine its understanding of other agents’ strategies iteratively.
The process works as follows: the agent observes the actions of other agents and forms initial hypotheses about their strategies. These hypotheses are evaluated based on how well they predict future behaviors. A scoring system identifies the most accurate hypotheses, which are reinforced and refined over time. This ensures the model continuously adapts and improves its understanding of other agents.
High-level plans are then conditioned on these refined hypotheses. The model’s hierarchical planning approach breaks down these plans into smaller, actionable subgoals, guiding the agent’s overall strategy. This structure allows the Hypothetical Minds model to navigate complex environments more effectively than traditional MARL methods.
To evaluate the effectiveness of Hypothetical Minds, researchers used the Melting Pot MARL benchmark, a comprehensive suite of tests designed to assess agent performance in various interactive scenarios. These ranged from simple coordination tasks to complex strategic games requiring cooperation, competition, and adaptation. Hypothetical Minds outperformed traditional MARL methods and other LLM-based agents in adaptability, generalization, and strategic depth. In competitive scenarios, the model dynamically updated its hypotheses about opponents’ strategies, predicting their moves several steps ahead, allowing it to outmaneuver competitors with superior strategic foresight.
The model also excelled in generalizing to new agents and environments, a challenge for traditional MARL approaches. When encountering unfamiliar agents, Hypothetical Minds quickly formed accurate hypotheses and adjusted their behavior without extensive retraining. The robust Theory of Mind module enabled hierarchical planning, allowing the model to effectively anticipate partners’ needs and actions.
Hypothetical Minds represents a major step forward in multi-agent reinforcement learning. By integrating the strengths of large language models with a sophisticated Theory of Mind module, the researchers have developed a system that excels in diverse environments and dynamically adapts to new challenges. This approach opens up exciting possibilities for future AI applications in complex, interactive settings.
Check out the Paper. All credit for this research goes to the researchers of this project. Also, don’t forget to follow us on Twitter and join our Telegram Channel and LinkedIn Group. If you like our work, you will love our newsletter..
Don’t Forget to join our 47k+ ML SubReddit
Find Upcoming AI Webinars here
The post Theory of Mind Meets LLMs: Hypothetical Minds for Advanced Multi-Agent Tasks appeared first on MarkTechPost.
#AIPaperSummary #AIShorts #Applications #ArtificialIntelligence #EditorsPick #LargeLanguageModel #MachineLearning #Staff #TechNews #Technology [Source: AI Techpark]