


In June 2024, Databricks made three significant announcements that have garnered considerable attention in the data science and engineering communities. These announcements focus on enhancing user experience, optimizing data management, and streamlining data engineering workflows. Let’s delve into each of these groundbreaking announcements.
1. The Next Generation of Databricks Notebooks
Databricks introduced a major update to their platform with the next generation of Databricks Notebooks. This new version enhances the data-focused authoring experience for data scientists, engineers, and SQL analysts. The updated Notebook experience features a sleek, modern interface and powerful new functionalities to simplify coding and data analysis.
Key Enhancements:
- Modern UX: The new Notebook UI provides a streamlined coding experience with features that improve organization and user productivity. The interface is designed to be simple and approachable, making it easy for new users to get started while offering customization options for advanced users.
- Simple Interface: The Notebook is refined to emphasize the most impactful aspects, minimizing distractions.
- Approachable Design: The interface blurs the lines between a document-like environment and a code editing surface, incorporating no-code interactions and AI assistance to lower the barrier to entry.
- Adaptive Customization: Users can customize the Notebook to fit their workflow preferences, ensuring a tailored authoring experience.
- New Results Table: This redesigned table allows no-code data exploration with integrated search and filtering capabilities. It offers improved performance, increased data density, and features like endless scrolling, data type icons, multi-column sorting, and integrated search and filtering functionalities.
- Improved Performance: The new results table offers endless scrolling and increased data density for better navigation.
- Data Type Icons and Sorting: Data type icons and multi-column sorting help users quickly understand their data profile and organize it effectively.
- Table Search and Filtering: Integrated search and filtering functionalities allow users to find specific columns or values and filter data to spot trends and identify essential values.
- Enhanced Python Features: New Python coding capabilities include an interactive debugger, error highlighting, and enhanced code navigation features. These enhancements make Python development more efficient and error-free.
- Interactive Debugger: The new debugger allows users to step through their Python code to identify and resolve errors quickly. The Variable Explorer has also been improved for better DataFrame visualization.
- Python Error Highlighting: Databricks now highlight errors in Python code, such as incorrect syntax or missing imports, with red squiggles. This visual aid helps developers quickly identify and correct mistakes.
- Go to Definition: This feature lets users right-click on any Python variable or function to access its definition. This facilitates seamless navigation through the codebase, allowing users to locate and understand variable or function definitions quickly.
- AI-Powered Authoring: The integration of Databricks Assistant provides in-line code generation and AI-powered code completion. Features like side-panel chat, inline assistant, and assistant autocomplete help users write code more quickly and accurately.
- Side-Panel Chat: The side-panel chat feature provides a dedicated space for users to interact with the AI Assistant. This feature is useful for seeking help, generating code, and diagnosing execution errors.
- Inline Assistant: Integrated directly into individual notebook cells, the Inline Assistant allows users to refactor code, make quick refinements, fix syntax errors, rename variables, add comments, perform data transformations, and outline functions efficiently.
- Assistant Autocomplete: This feature offers real-time, personalized Python and SQL suggestions as users type, predicting the next steps and helping to write error-free code swiftly and seamlessly.
These enhancements are designed to streamline the workflow of data scientists, engineers, and analysts, making Databricks an even more powerful tool for data-driven insights and analysis.
2. Announcing the General Availability of Predictive Optimization
Databricks also announced the General Availability of its new Predictive Optimization feature. This feature automates data layout optimization to enhance query performance and reduce storage costs.
Key Features and Benefits:
- Automated Data Layout Optimization: Predictive Optimization leverages AI to analyze query patterns and determine the best optimizations for data layouts. This automation reduces the need for manual maintenance and improves performance and cost efficiency. The feature eliminates the need for data teams to manually manage maintenance operations, such as scheduling jobs, diagnosing failures, and managing infrastructure.
- Intelligent Analysis: The AI model behind Predictive Optimization evaluates various factors, including data layout, table properties, and performance characteristics, to decide the most impactful optimizations. This intelligent analysis ensures that optimizations are tailored to the organization’s needs, leading to immediate and substantial benefits.
- For example, the energy company Plenitude experienced a 26% reduction in storage costs shortly after enabling Predictive Optimization. This capability allowed them to retire manual maintenance procedures and achieve greater scalability.
- Adaptive Learning: Predictive Optimization continuously learns from the organization’s data usage patterns, adjusting optimizations based on these patterns to ensure efficient data storage and ongoing performance improvements. The intelligence engine learns from your organization’s usage over time, ensuring that your data is always stored in the most efficient layout, translating to cost savings and performance gains without continuous manual intervention.
- Toloka AI, an AI data annotation platform, replaced their DIY table maintenance solution with Predictive Optimization, which proved more efficient and cost-effective.
- Automatic Liquid Clustering: A new feature since the Preview, Predictive Optimization now automatically runs OPTIMIZE on tables with Liquid Clustering and performs vacuum and compaction operations. This automation ensures that clustering occurs at an optimal cadence for better query performance.
- Impact in Numbers: Since its Preview launch, Predictive Optimization has been implemented across hundreds of thousands of tables, optimizing exabytes of data. These optimizations have significantly improved query performance by optimizing file size and layout on disk, generating millions in annual storage savings for customers.
- Anker: The data engineering team at Anker reported a 2x improvement in query performance and 50% savings in storage costs after enabling Predictive Optimization. The AI model prioritized their largest and most-accessed tables, delivering these benefits automatically.
Customer testimonials highlight the practical benefits of Predictive Optimization. Users report significant improvements in query performance and storage cost savings.
Future Enhancements:
Databricks plans to continue enhancing Predictive Optimization. Upcoming features include:
- Built-in Observability Dashboard: This dashboard will provide insights into the optimizations performed and their impact on query performance and storage savings, making the benefits transparent and measurable.
- Automatic Statistics Collection: Predictive Optimization will soon collect statistics during supported write operations and intelligently update these statistics in the background, ensuring query plans are optimized efficiently. These background operations are run as necessary and determined by smart logic that tracks when statistics are stale, and the workload needs them.
Soon, Predictive Optimization will be enabled by default across all Unity Catalog-managed tables, providing optimized data layouts and efficient storage without any manual intervention.
Organizations can start using Predictive Optimization by enabling it in the account console. This feature represents a significant step in automating data optimization and maintenance, allowing data teams to focus more on driving business value rather than managing infrastructure.
3. Introducing Databricks LakeFlow: A Unified, Intelligent Solution for Data Engineering
The third major announcement is the introduction of Databricks LakeFlow, a comprehensive solution designed to streamline and enhance the process of building and operating production data pipelines. This solution addresses the complexities data engineering teams face by providing a unified platform for data ingestion, transformation, and orchestration.
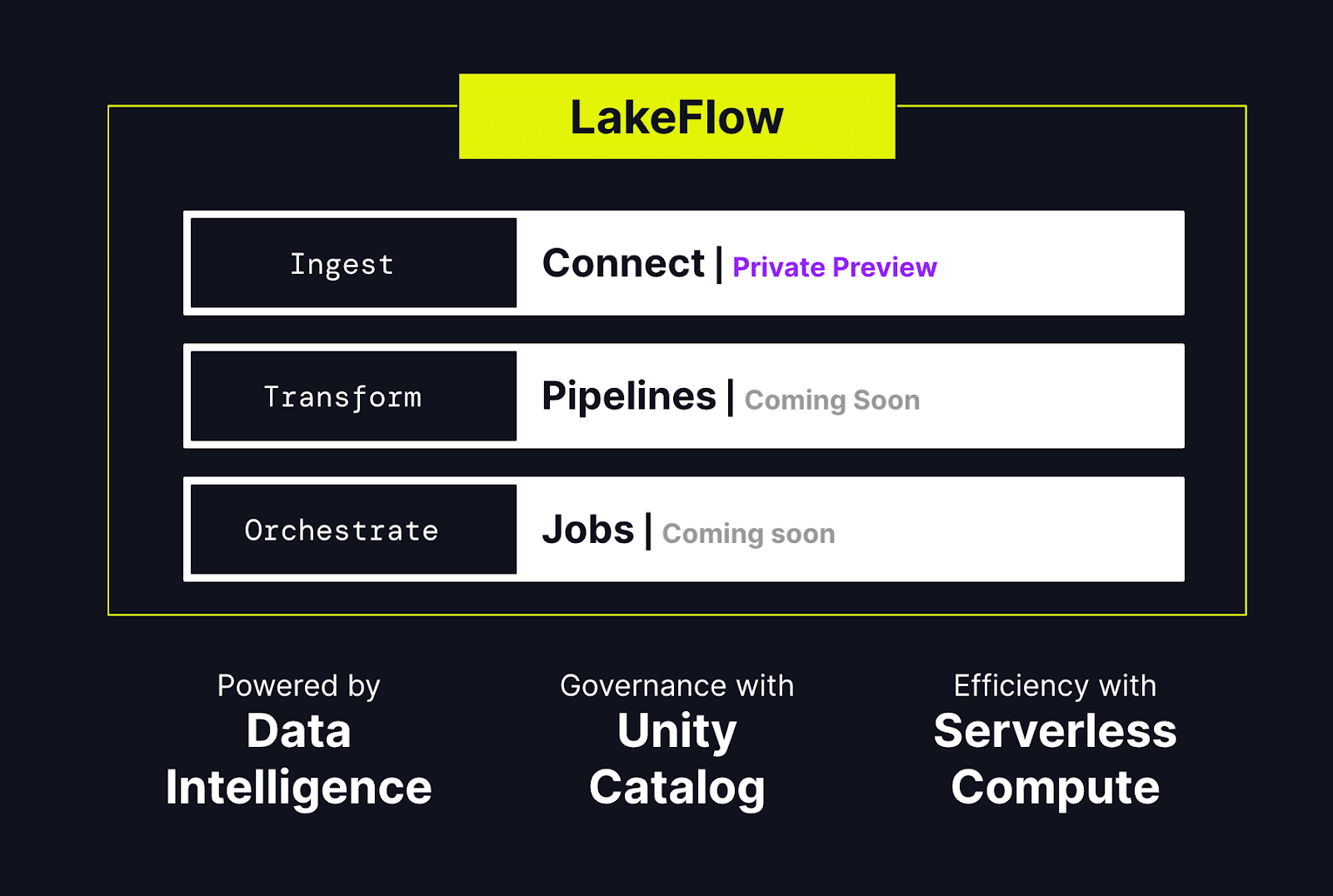
Key Components of LakeFlow:
- LakeFlow Connect: This component offers point-and-click data ingestion from numerous databases and enterprise applications. It supports unstructured data ingestion and extends native connectors for cloud storage and partner solutions. Change data capture (CDC) technology ensures reliable and efficient data transfer from operational databases to the lakehouse.
- Advanced Connectors: Powered by the acquisition of Arcion, LakeFlow Connect uses change data capture (CDC) technology to reliably and efficiently bring operational database data to the lakehouse. This feature increases productivity by eliminating the need for fragile middleware and reducing data latency from days to minutes.
- Customer Example: Insulet, a manufacturer of wearable insulin management systems, uses the Salesforce ingestion connector to analyze customer feedback data in near real-time, streamlining their data integration process and enhancing their ability to track quality issues.
- LakeFlow Pipelines: Built on the Delta Live Tables framework, LakeFlow Pipelines allow data teams to write business logic in SQL and Python, while Databricks automates data orchestration, incremental processing, and compute infrastructure autoscaling. This reduces the complexity of managing batch and streaming data pipelines.
- Declarative Framework: A declarative framework enables data teams to focus on business logic rather than the intricacies of pipeline management. This includes built-in data quality monitoring and a Real-Time Mode for consistently low-latency data delivery.
- Automation and Monitoring: LakeFlow Pipelines simplify the automation and monitoring of data pipelines, ensuring data freshness and reliability without extensive manual intervention.
- LakeFlow Jobs: This component builds on the capabilities of Databricks Workflows to orchestrate and monitor various production workloads, including data ingestion, pipelines, notebooks, SQL queries, machine learning training, model deployment, and inference.
- Advanced Orchestration: With features like triggers, branching, and looping, LakeFlow Jobs can handle complex data delivery use cases. It provides full lineage tracking, data freshness, and quality monitoring, making it easier for data teams to manage and understand the health of their data assets.
- Integrated Monitoring: The built-in monitoring capabilities allow data teams to track data health and performance comprehensively, adding monitors with just a few clicks.
Databricks LakeFlow is natively integrated with the Databricks Data Intelligence Platform, bringing several key benefits:
- Data Intelligence: AI-powered intelligence enhances every aspect of LakeFlow, from discovery and authoring to monitoring data pipelines. This integration allows users to spend more time building reliable data and less time managing infrastructure.
- Unified Governance: LakeFlow leverages Unity Catalog for data governance, ensuring robust lineage tracking and data quality management.
- Serverless Compute: The platform supports serverless computing, enabling data teams to build and orchestrate pipelines at scale without worrying about the underlying infrastructure.
Conclusion
These three announcements underscore Databricks’ ongoing commitment to innovation and enhancing the user experience. The next generation of Databricks Notebooks, Predictive Optimization, and Databricks LakeFlow collectively represent significant advancements in data science, engineering, and management. These improvements are set to substantially impact the productivity and effectiveness of data-focused professionals, reinforcing Databricks’ position as a leader in the field.
Sources
- https://www.databricks.com/blog/next-generation-databricks-notebooks-simple-and-powerful
- https://www.databricks.com/blog/announcing-general-availability-predictive-optimization
- https://www.databricks.com/blog/introducing-databricks-lakeflow
The post The Three Big Announcements by Databricks AI Team in June 2024 appeared first on MarkTechPost.
#AIShorts #Applications #ArtificialIntelligence #EditorsPick #LanguageModel #LargeLanguageModel #Staff #TechNews #Technology [Source: AI Techpark]