


Kolmogorov-Arnold Networks (KANs) have emerged as a promising alternative to traditional Multi-Layer Perceptrons (MLPs). Inspired by the Kolmogorov-Arnold representation theorem, these networks utilize neurons that perform simple summation operations. However, the current implementation of KANs poses some challenges in practical applications. Currently, researchers are investigating the possibility of identifying alternative multivariate functions for KAN neurons that could offer enhanced practical utility across several benchmarks related to machine-learning tasks.
Research has highlighted the potential of KANs in various fields, like computer vision, time series analysis, and quantum architecture search. Some studies show that KANs can outperform MLPs in data fitting and PDE tasks while using fewer parameters. However, some research has raised concerns about the robustness of KANs to noise and their performance compared to MLPs. Variations and improvements to the standard KAN architecture are also explored, such as graph-based designs, convolutional KANs, and transformer-based KANs to solve the issues. Moreover, alternative activation functions like wavelets, radial basis functions, and sinusoidal functions are investigated to improve KAN efficiency. Despite these works, there is a need for further improvements to enhance KAN performance.
A Researcher from the Center for Applied Intelligent Systems Research at Halmstad University, Sweden, has proposed a novel approach to enhance the performance of Kolmogorov-Arnold Networks (KANs). This method aims to identify the optimal multivariate function for KAN neurons across various machine learning classification tasks. The traditional use of addition as the node-level function is often non-ideal, especially for high-dimensional datasets with multiple features. This can cause the inputs to exceed the effective range of subsequent activation functions, leading to training instability and reduced generalization performance. To solve this problem, the researcher suggests using the mean instead of the sum as the node function.
To evaluate the proposed KAN modifications, 10 popular datasets from the UCI Machine Learning Database Repository are utilized, covering multiple domains and varying sizes. These datasets are divided into training (60%), validation (20%), and testing (20%) partitions. A standardized preprocessing method is applied across all datasets, which includes categorical feature encoding, missing value imputation, and instance randomization. Models are trained for 2000 iterations using the Adam optimizer with a learning rate of 0.01 and a batch size of 32. Model accuracy on the testing set serves as the primary evaluation metric. The parameter count is managed by setting the grid to 3 and using default hyperparameters for the KAN models.
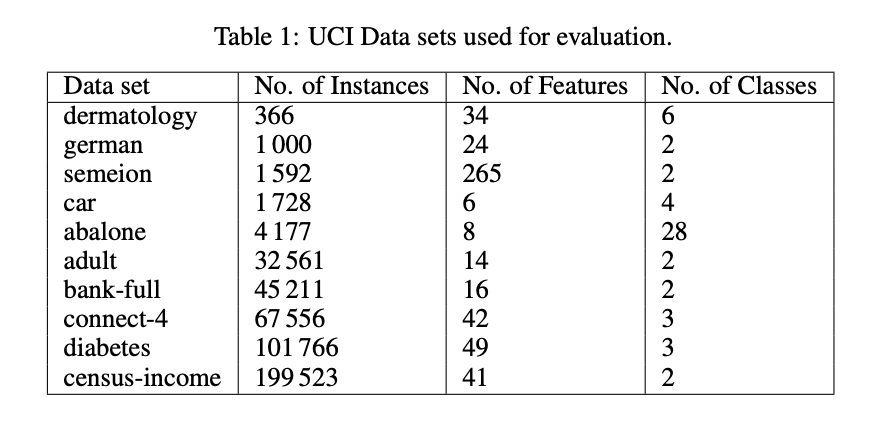
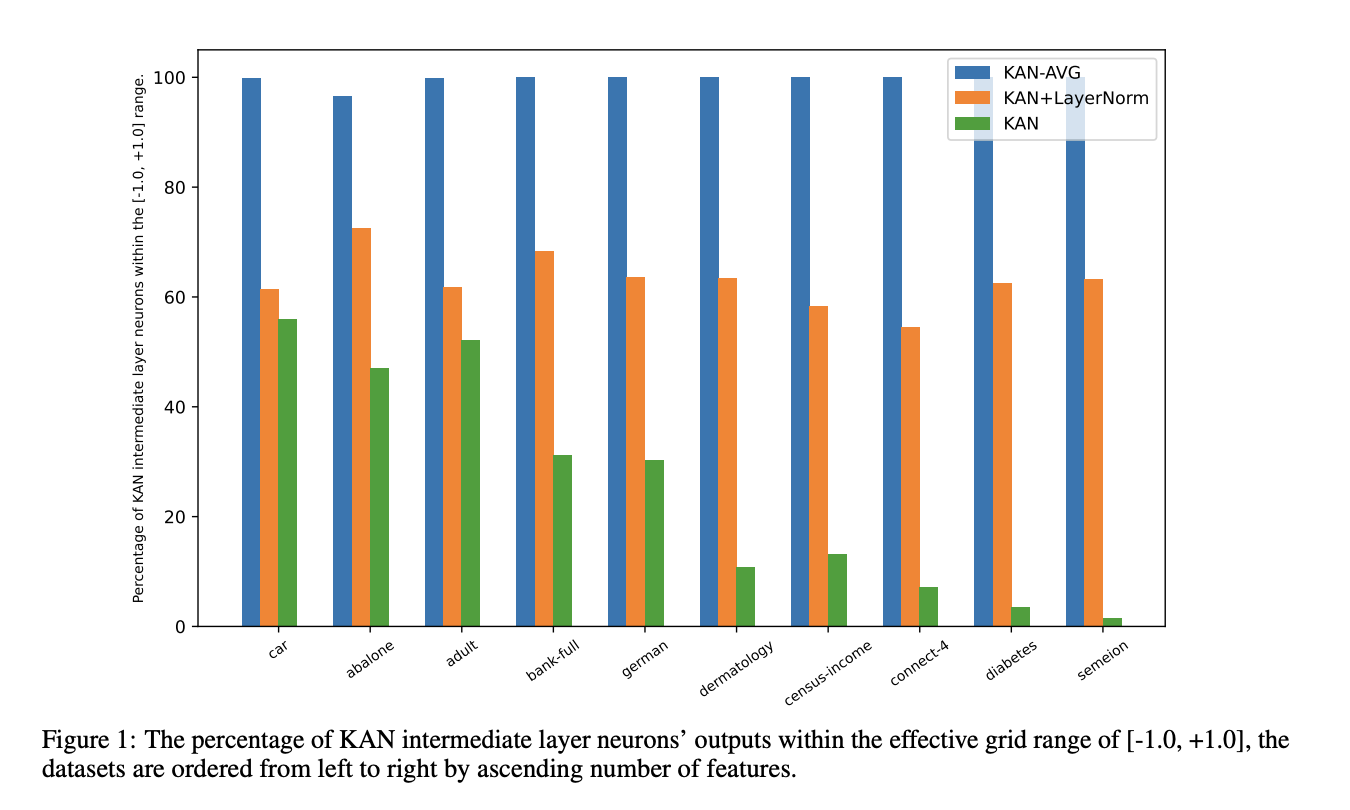
The results support the hypothesis that using the mean function in KAN neurons is more effective than the traditional sum function. This enhancement is due to the mean’s ability to keep input values within the optimal range of the spline activation function, which is [-1.0, +1.0]. Standard KANs struggled to keep values within this range in intermediate layers as the number of features increased. However, adopting the mean function in neurons leads to enhanced performance, keeping values within the desired range across datasets with 20 or more features. For datasets with fewer features, values stayed within the range more than 99.0% of the time, except for the ‘abalone’ dataset, which had a slightly lower adherence rate of 96.51%.
In this paper, a Researcher from the Center for Applied Intelligent Systems Research at Halmstad University, Sweden, has proposed a method to enhance the performance of KANs. An important modification to KANs is introduced in this paper by replacing the traditional summation in KAN neurons with an averaging function. Experimental results show that this change leads to more stable training processes and keeps inputs within the effective range of spline activations. This adjustment to KAN architecture solves previous challenges related to input range and training stability. In the future, this work offers a promising direction for future KAN implementations, potentially enhancing their performance and applicability in various machine-learning tasks.
Check out the Paper. All credit for this research goes to the researchers of this project. Also, don’t forget to follow us on Twitter and join our Telegram Channel and LinkedIn Group. If you like our work, you will love our newsletter..
Don’t Forget to join our 47k+ ML SubReddit
Find Upcoming AI Webinars here
The post The Kolmogorov-Arnold Theorem Revisited: Why Averaging Functions Work Better appeared first on MarkTechPost.
#AIPaperSummary #AIShorts #Applications #ArtificialIntelligence #EditorsPick #MachineLearning #Staff #TechNews #Technology [Source: AI Techpark]