


The emergence of diffusion models has recently facilitated the generation of high-quality images. Diffusion models are refined with temporal modules, enabling these models to excel in creating compelling videos. Additionally, the capability to generate realistic and dynamic portrait animations from both audio inputs and static images holds immense potential across various domains. This innovative approach finds applications in virtual reality, gaming, and digital media. Its impact extends to content creation, storytelling, and personalized user experiences.
However, there are significant challenges in producing high-quality, visually captivating animations that maintain temporal consistency. These complications arise from the need for intricate coordination of lip movements, facial expressions, and head positions to craft visually compelling effects. Existing methods have often failed to overcome this challenge due to their dependency on limited-capacity generators for visual content creation, such as GANs, NeRF, or motion-based decoders. These networks show limited generalization capabilities and often lack stability in generating high-quality content.
Tencent researchers introduced AniPortrait, a novel framework designed to generate high-quality animated portraits driven by audio and a reference image. AniPortrait is divided into two distinct stages. In the first stage, transformer-based models extract a sequence of 3D facial mesh and head pose from the audio input. This stage can capture subtle expressions and lip movements from the audio. In the second stage, a robust diffusion model is utilized through a motion module integration that transforms the facial landmark sequence into a temporally consistent and photorealistic animated portrait.
Experimental results demonstrate the superior performance of AniPortrait in creating animations with impressive facial naturalness, varied poses, and excellent visual quality. Leveraging 3D facial representations as intermediate features helps gain flexibility and modify these features, enhancing the applicability of the proposed framework in domains like facial motion. This framework comprises two modules: Audio2Lmk and Lmk2Video. Audio2Lmk is designed to extract a sequence of landmarks that captures intricate facial expressions and lip movements from the audio input. At the same time, Lmk2Video utilizes this landmark sequence to generate high-quality portrait videos with temporal stability.
In Audio2Lmk, pre-trained wav2vec is utilized to extract audio features. This model exhibits strong generalizability, accurately identifying both pronunciation and intonation from the audio. Moreover, Lmk2Video’s network structure is designed to draw inspiration from AnimateAnyone, utilizing SD1.5 as the backbone and incorporating a temporal motion module. Similarly, a ReferenceNet, echoing the architecture of SD1.5, is used to extract appearance information from the reference image and integrate it into the backbone. Finally, 4 A100 GPUs are utilized for model training, dedicating two days to each step, and the AdamW optimizer is employed, with a consistent learning rate of 1e-5.
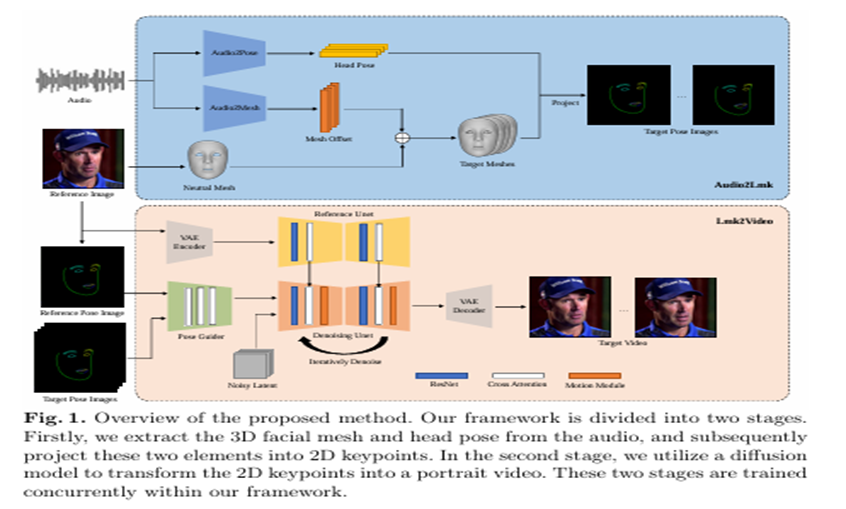
In conclusion, this research presents AniPortrait, a diffusion model-based framework for portrait animation. This framework can generate a portrait video featuring smooth lip motion and natural head movements. However, obtaining large-scale and high-quality 3D data is quite expensive. Hence, the facial expressions and head postures in generated portrait videos can’t escape the uncanny valley effect. So, the plan is to predict portrait videos directly from audio to achieve more stunning generation results.
Check out the Paper and Github. All credit for this research goes to the researchers of this project. Also, don’t forget to follow us on Twitter. Join our Telegram Channel, Discord Channel, and LinkedIn Group.
If you like our work, you will love our newsletter..
Don’t Forget to join our 39k+ ML SubReddit
The post Tencent Propose AniPortrait: An Audio-Driven Synthesis of Photorealistic Portrait Animation appeared first on MarkTechPost.
#AIPaperSummary #AIShorts #Applications #ArtificialIntelligence #ComputerVision #EditorsPick #Staff #TechNews #Technology [Source: AI Techpark]