


In AI, synthesizing linguistic and visual inputs marks a burgeoning area of exploration. With the advent of multimodal models, the ambition to engage the textual with the visual opens up unprecedented avenues for machine comprehension. These advanced models go beyond the traditional scope of large language models (LLMs), aiming to grasp and utilize both forms of data to tackle many tasks. Potential applications are generating detailed image captions and providing accurate responses to visual queries.
Despite remarkable strides in the field, accurately interpreting images paired with text remains a considerable challenge. Existing models often need help with the complexity of real-world visuals, especially those containing text. This is a significant hurdle, as understanding images with embedded textual information is crucial for models to mirror human-like perception and interaction with their environment truly.
The landscape of current methodologies includes Vision Language Models (VLMs) and Multimodal Large Language Models (MLLMs). These systems have been designed to bridge the gap between visual and textual data, integrating them into a cohesive understanding. However, they frequently need to fully capture the intricacies and nuanced details present in visual content, particularly when it involves interpreting and contextualizing embedded text.
SuperAGI researchers have developed Veagle, a unique model for addressing limitations in current VLMs and MLLMs. This innovative model has the potential to dynamically integrate visual information into language models. Veagle emerges from a synthesis of insights from prior research, applying a sophisticated mechanism to project encoded visual data directly into the linguistic analysis framework. This allows for a deeper, more nuanced comprehension of visual contexts, significantly enhancing the model’s ability to interpret and relate textual and visual information.
Veagle’s methodology is unique for its structured training regimen, which encompasses the utilization of a pre-trained vision encoder alongside a language model. This strategic approach involves two training phases, meticulously designed to refine and enhance the model’s capabilities. At first, Veagle focuses on assimilating the fundamental connections between visual and textual data, establishing a solid foundation. The model undergoes further refinement, honing its ability to interpret complex visual scenes and the embedded text, thereby facilitating a comprehensive understanding of the interplay between the two modalities.

The evaluation of Veagle’s performance reveals its superior capabilities in a series of benchmark tests, particularly in visual question answering and image comprehension tasks. The model demonstrates a significant improvement, achieving a 5-6% enhancement in performance over existing models, and establishes new standards for accuracy and efficiency in multimodal AI research. These outcomes not only underscore the effectiveness of Veagle in navigating the challenges of integrating visual and textual information but also highlight its versatility and potential applicability across a range of scenarios beyond the confines of established benchmarks.
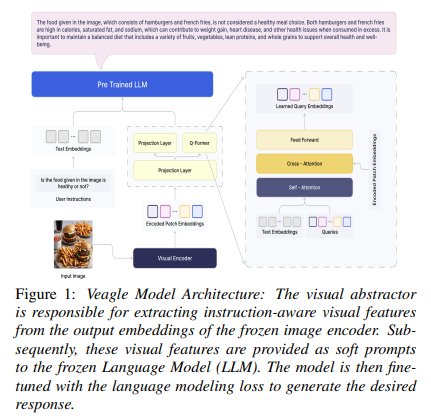
In conclusion, Veagle represents a paradigm shift in multimodal representation learning, offering a more sophisticated and effective means of integrating language and vision. Veagle paves the way for interesting research in VLMs and MLLMs by overcoming the prevalent limitations of current models. This advancement signals a move towards models that can more accurately mirror human cognitive processes, interpreting and interacting with the environment in a manner that was previously unattainable.
Check out the Paper. All credit for this research goes to the researchers of this project. Also, don’t forget to follow us on Twitter. Join our Telegram Channel, Discord Channel, and LinkedIn Group.
If you like our work, you will love our newsletter..
Don’t Forget to join our 38k+ ML SubReddit
Want to get in front of 1.5 Million AI enthusiasts? Work with us here
The post SuperAGI Proposes Veagle: Pioneering the Future of Multimodal Artificial Intelligence with Enhanced Vision-Language Integration appeared first on MarkTechPost.
#AIPaperSummary #AIShorts #Applications #ArtificialIntelligence #ComputerVision #EditorsPick #Staff #TechNews #Technology #Uncategorized [Source: AI Techpark]