


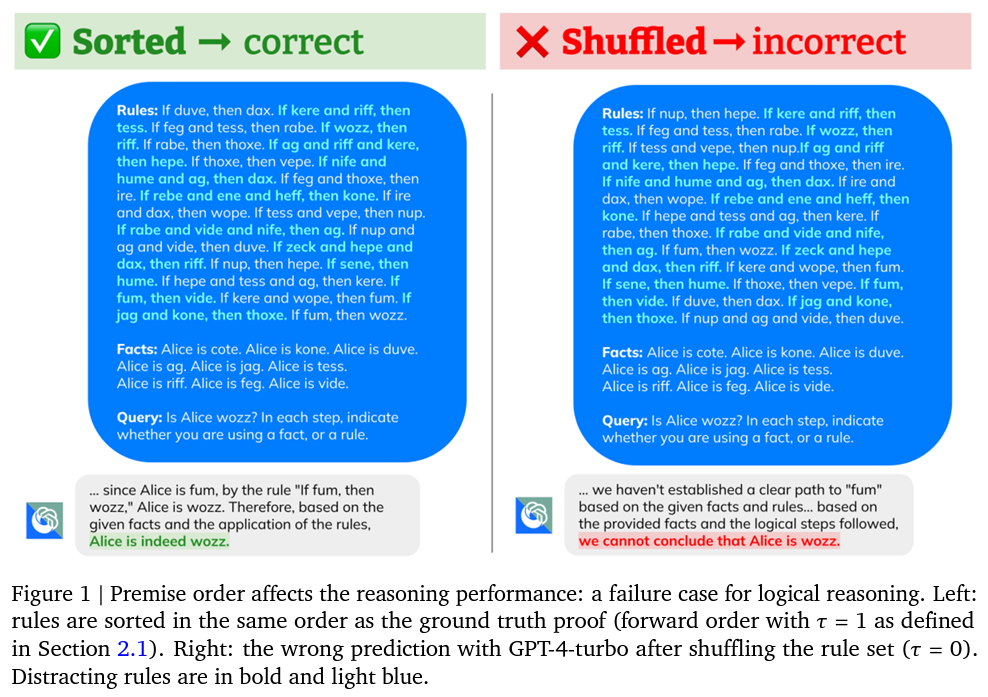
LLMs, which have been lauded for their exceptional performance across a spectrum of reasoning tasks, from STEM problem-solving to code generation, often surpassing human benchmarks, show a surprising frailty when confronted with reordered premises. The research by Google Deepmind and Stanford University unveils that a deviation from an optimal sequence, closely aligned with the logical progression of a ground truth proof, can lead to a significant dip in LLM performance, with accuracy drops of over 30% in some instances.
To systematically study this phenomenon, the research team crafted a novel benchmark named R-GSM, specifically designed to assess the impact of premise ordering on mathematical reasoning tasks. By altering the sequence of information presented to the models, the study illuminated how even subtle changes in premise arrangement could drastically affect LLMs’ ability to arrive at correct conclusions. This methodology underscores the intricacies of how LLMs process information and highlights the limitations of current model designs in handling variably ordered data inputs.
The findings from this comprehensive evaluation starkly highlight the magnitude of the premise ordering effect on LLM reasoning capabilities. Across various state-of-the-art models, including GPT-4-turbo, GPT-3.5-turbo, PaLM 2-L, and Gemini Pro, the study observed that the performance degradation was not a mere anomaly but a consistent issue that intensified with the complexity of the reasoning task. For instance, in the R-GSM benchmark, all LLMs tested showed a marked decrease in accuracy on reordered problems, with performance degradation of more than 35% for some models compared to their original problem-solving accuracy.
This sensitivity to premise sequence poses a significant challenge for the future of LLM development and deployment in reasoning-based applications. The study’s insights into the LLMs’ preference for certain premise orders over others, while mirroring human reasoning patterns to some extent, also reveal a critical vulnerability in these models’ reasoning faculties. The research suggests that LLMs, by design, are predisposed to process information in a linear, forward-chaining manner, struggling significantly when required to engage in back-and-forth reading to piece together information out of its ‘preferred’ order.
In light of these findings, Google DeepMind and Stanford University researchers call for reevaluating LLM training and modeling techniques. The premise order effect, as uncovered in this study, necessitates the development of more robust models capable of maintaining high reasoning accuracy across various premise arrangements. This direction aims to enhance LLMs’ reasoning capabilities and make them more adaptable and reliable across a broader range of real-world applications.
The implications of this research extend beyond the immediate concerns of model accuracy in controlled tasks. By shedding light on a previously underexplored aspect of LLM behavior, this study paves the way for future advancements in AI, where models are proficient in handling complex reasoning tasks and resilient against the nuances of data presentation. Addressing the premise order effect as the AI community moves forward could mark a significant leap toward developing intelligent, versatile, and dependable reasoning models, ushering in a new era of AI capabilities.
Check out the Paper. All credit for this research goes to the researchers of this project. Also, don’t forget to follow us on Twitter and Google News. Join our 37k+ ML SubReddit, 41k+ Facebook Community, Discord Channel, and LinkedIn Group.
If you like our work, you will love our newsletter..
Don’t Forget to join our Telegram Channel
The post Shattering AI Illusions: Google DeepMind’s Research Exposes Critical Reasoning Shortfalls in LLMs! appeared first on MarkTechPost.
#AIShorts #Applications #ArtificialIntelligence #EditorsPick #MachineLearning #Staff #TechNews #Technology [Source: AI Techpark]