


Large Language Models (LLMs) have revolutionized the field of natural language processing, allowing machines to understand and generate human language. These models, such as GPT-4 and Gemini-1.5, are crucial for extensive text processing applications, including summarization and question answering. However, managing long contexts remains challenging due to computational limitations and increased costs. Researchers are, therefore, exploring innovative approaches to balance performance and efficiency.
A notable challenge in processing lengthy texts is the computational burden and associated costs. Traditional methods often need to improve when dealing with long contexts, necessitating new strategies to handle this issue effectively. This problem requires methodologies that balance high performance with cost efficiency. One promising approach is Retrieval Augmented Generation (RAG), which retrieves relevant information based on a query and prompts LLMs to generate responses within that context. RAG significantly expands a model’s capacity to access information economically. However, a comparative analysis becomes essential with advancements in LLMs like GPT-4 and Gemini-1.5, which show improved capabilities in directly processing long contexts.
Researchers from Google DeepMind and the University of Michigan introduced a new method called SELF-ROUTE. This method combines the strengths of RAG and long-context LLMs (LC) to route queries efficiently using model self-reflection to decide whether to use RAG or LC based on the nature of the query. The SELF-ROUTE method operates in two steps. Initially, the query and retrieved chunks are provided to the LLM to determine if the query is answerable. If deemed answerable, the RAG-generated answer is used. Otherwise, the LC will be given the full context for a more comprehensive response. This approach significantly reduces computational costs while maintaining high performance, effectively leveraging the strengths of both RAG and LC models.
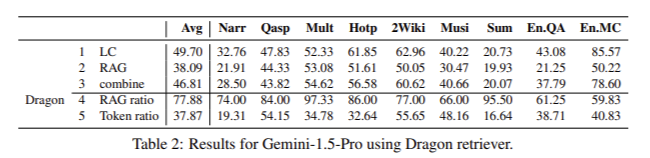
The SELF-ROUTE evaluation involved three recent LLMs: Gemini-1.5-Pro, GPT-4, and GPT-3.5-Turbo. The study benchmarked these models using LongBench and u221eBench datasets, focusing on query-based tasks in English. The results demonstrated that LC models consistently outperformed RAG in understanding long contexts. For example, LC surpassed RAG by 7.6% for Gemini-1.5-Pro, 13.1% for GPT-4, and 3.6% for GPT-3.5-Turbo. However, RAG’s cost-effectiveness remains a significant advantage, particularly when the input text considerably exceeds the model’s context window size.
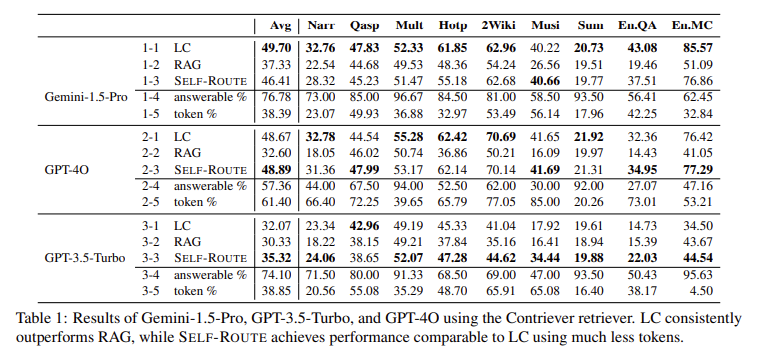
SELF-ROUTE achieved notable cost reductions while maintaining comparable performance to LC models. For instance, the cost was reduced by 65% for Gemini-1.5-Pro and 39% for GPT-4. The method also showed a high degree of prediction overlap between RAG and LC, with 63% of queries having identical predictions and 70% showing a score difference of less than 10. This overlap suggests that RAG and LC often make similar predictions, both correct and incorrect, allowing SELF-ROUTE to leverage RAG for most queries and reserve LC for more complex cases.
The detailed performance analysis revealed that, on average, LC models surpassed RAG by significant margins: 7.6% for Gemini-1.5-Pro, 13.1% for GPT-4, and 3.6% for GPT-3.5-Turbo. Interestingly, for datasets with extremely long contexts, such as those in u221eBench, RAG sometimes performed better than LC, particularly for GPT-3.5-Turbo. This finding highlights RAG’s effectiveness in specific use cases where the input text exceeds the model’s context window size.
The study also examined various datasets to understand the limitations of RAG. Common failure reasons included multi-step reasoning requirements, general or implicit queries, and long, complex queries that challenge the retriever. By analyzing these failure patterns, the research team identified potential areas for improvement in RAG, such as incorporating chain-of-thought processes and enhancing query understanding techniques.

In conclusion, the comprehensive comparison of RAG and LC models highlights the trade-offs between performance and computational cost in long-context LLMs. While LC models demonstrate superior performance, RAG remains viable due to its lower cost and specific advantages in handling extensive input texts. The SELF-ROUTE method effectively combines the strengths of both RAG and LC, achieving performance comparable to LC at a significantly reduced cost.
Check out the Paper. All credit for this research goes to the researchers of this project. Also, don’t forget to follow us on Twitter and join our Telegram Channel and LinkedIn Group. If you like our work, you will love our newsletter..
Don’t Forget to join our 47k+ ML SubReddit
Find Upcoming AI Webinars here
The post Self-Route: A Simple Yet Effective AI Method that Routes Queries to RAG or Long Context LC based on Model Self-Reflection appeared first on MarkTechPost.
#AIPaperSummary #AIShorts #Applications #ArtificialIntelligence #EditorsPick #LanguageModel #LargeLanguageModel #Staff #TechNews #Technology [Source: AI Techpark]