


Large language models like GPT-4 are incredibly powerful, but they sometimes struggle with basic tasks involving visual perception – like counting objects in an image. It turns out part of the issue may stem from how these models process high-resolution images.
Most current multimodal AI systems can only perceive images at a fixed low resolution, like 224×224 pixels. But real-world images come in all shapes and sizes. Simply resizing or cropping them leads to distortion, blurriness, and loss of detail that prevents the models from understanding fine-grained visual information.
Researchers from Tsinghua University, National University of Singapore and University of Chinese Academy of Sciences tackled this challenge by developing LLaVA-UHD (shown in Figure 4), a new method for building encoder-decoder models that can flexibly handle high-resolution images at any aspect ratio. But how does it actually work?
The core idea is to intelligently split up large images into smaller, variable-sized “slices” that don’t stray too far from the original training data for the visual encoder. Each slice is resized to fit the encoder while preserving its native aspect ratio. A shared “compression layer” then condenses the visual tokens for each slice to reduce the computational load on the language model.
To give the language model spatial context for the slice layout, LLaVA-UHD uses a simple positional encoding scheme with comma separators for rows and newlines between rows. Clever, right? The overview effect is that LLaVA-UHD can flexibly parse high-res images up to 672×1088 pixels using just 94% of the compute needed for low-res 336×336 images with previous models.
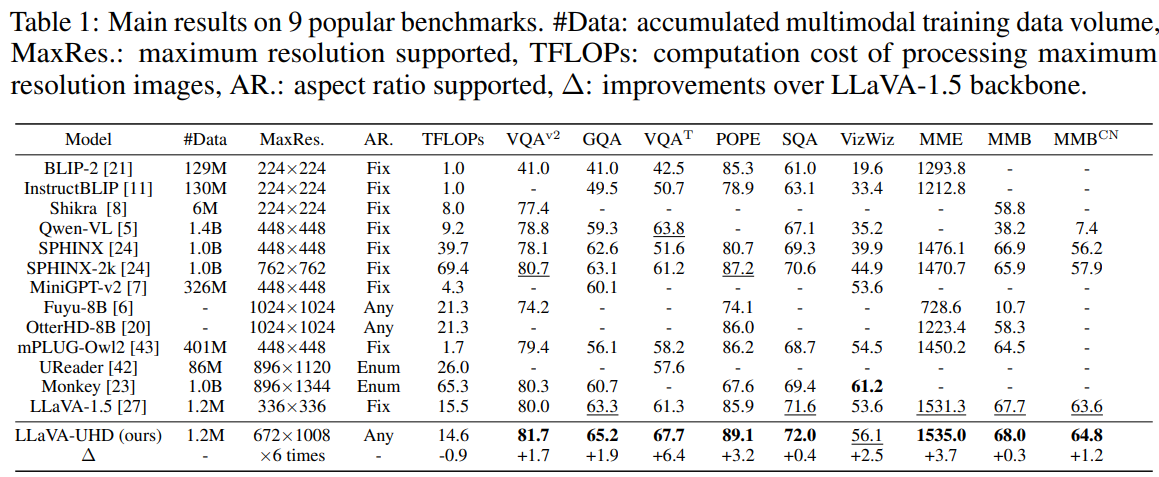
The researchers put their method through its paces on 9 challenging multimodal benchmarks spanning visual question answering, optical character recognition, and more. Across the board, LLaVA-UHD outperformed standard models as well as specialized high-res systems, all while using far less computing power during training. On the TextVQA benchmark testing OCR capabilities, it achieved a 6.4 point accuracy boost over the previous best as shown in Table 1.
Why such a performance leap? By preserving fine visual details in native high resolutions, LLaVA-UHD can simply understand images better than models squinting at low-res, blurry inputs. No more making best guesses – it gets the full picture.
Of course, the work isn’t over. Even higher resolutions and more advanced tasks like object detection await. But LLaVA-UHD takes a crucial step toward true visual intelligence for AI by letting language models perceive the world in vivid detail, just as we humans do.
Check out the Paper and Github. All credit for this research goes to the researchers of this project. Also, don’t forget to follow us on Twitter. Join our Telegram Channel, Discord Channel, and LinkedIn Group.
If you like our work, you will love our newsletter..
Don’t Forget to join our 39k+ ML SubReddit
The post Seeing it All: LLaVA-UHD Perceives High-Resolution Images at Any Aspect Ratio appeared first on MarkTechPost.
#AIPaperSummary #AIShorts #Applications #ArtificialIntelligence #ComputerVision #EditorsPick #Staff #TechNews #Technology [Source: AI Techpark]