


Evaluating Multimodal Large Language Models (MLLMs) in text-rich scenarios is crucial, given their increasing versatility. However, current benchmarks mainly assess general visual comprehension, overlooking the nuanced challenges of text-rich content. MLLMs like GPT-4V, Gemini-Pro-Vision, and Claude-3-Opus showcase impressive capabilities but lack comprehensive evaluation in text-rich contexts. Understanding text within images requires interpreting textual and visual cues, a challenge yet to be rigorously addressed.
SEED-Bench-2-Plus, developed by researchers from Tencent AI Lab, ARC Lab, Tencent PCG, and The Chinese University of Hong Kong, Shenzhen, is a specialized benchmark for evaluating MLLMs’ understanding of text-rich visual content. It consists of 2.3K meticulously crafted multiple-choice questions covering three broad categories: charts, Maps, and Webs, encompassing diverse real-world scenarios. Human annotators ensure accuracy, and evaluation involves 34 leading MLLMs like GPT-4V, Gemini-Pro-Vision, and Claude-3-Opus.
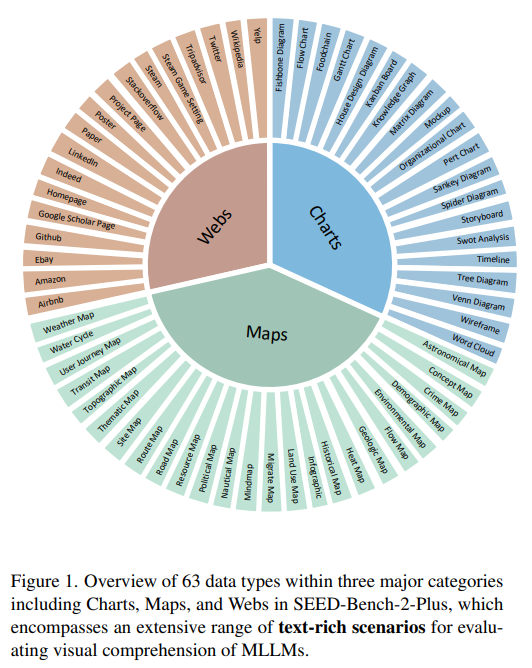
Recent research has seen a surge in MLLMs, aiming to enhance understanding across text and images. While some studies integrate video inputs, others focus on generating images from text. However, the proficiency of these models in text-rich contexts still needs to be explored. SEED-Bench-2-Plus addresses this gap by offering a comprehensive benchmark to evaluate MLLMs’ performance in understanding text-rich visual content. Unlike existing benchmarks, SEED-Bench-2-Plus encompasses a broad spectrum of real-world scenarios and avoids biases introduced by human annotators, providing a valuable tool for objective evaluation and advancement in this domain.
SEED-Bench-2-Plus presents a comprehensive benchmark comprising 2K multiple-choice questions across three main categories: Charts, Maps, and Webs. Each category encompasses a variety of data types, totaling 63 in all. The dataset is meticulously curated, including charts, maps, and website screenshots rich in textual information. Utilizing GPT-4V, questions are generated and further refined by human annotators. Evaluation employs an answer ranking strategy, assessing MLLMs’ performance based on the likelihood of developing the correct answer for each choice. Unlike previous methods, this approach avoids dependency on model instruction-following capabilities and mitigates the impact of multiple-choice option order on performance.
The evaluation encompassed 31 open-source MLLMs and three closed-source ones across various categories of SEED-Bench-2-Plus. GPT-4V outperformed many MLLMs, showing superior performance across most evaluation types. However, most MLLMs struggled with text-rich data, achieving an average accuracy rate of less than 40%, indicating the complexity of comprehending such data. Maps posed significant challenges due to their multidimensional nature, while performance varied across different data types within categories. These observations underscore the need for further research to enhance MLLMs’ proficiency in text-rich scenarios, ensuring adaptability across diverse data types.
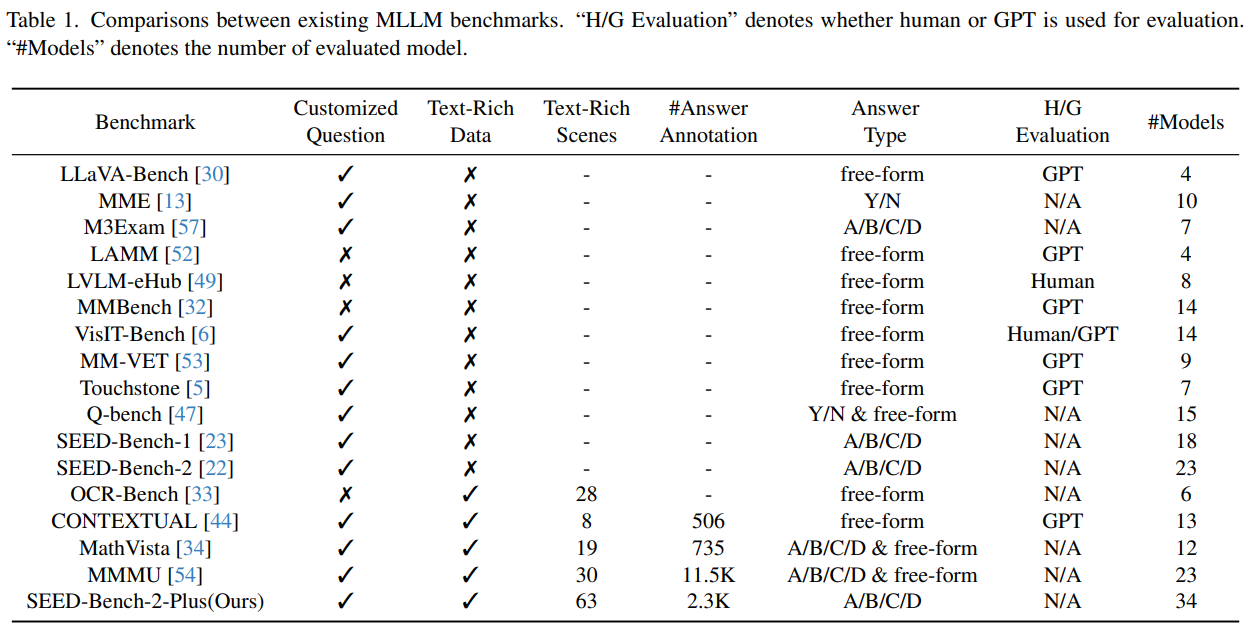
In conclusion, SEED-Bench-2-Plus is a comprehensive benchmark for assessing MLLMs in text-rich contexts. With 2K human-annotated multiple-choice questions covering 63 data types across three broad categories, it offers a thorough evaluation platform. By examining 31 open-source and three closed-source MLLMs, valuable insights have been gleaned to guide future research. Complementing SEED-Bench-2, both the dataset and evaluation code are publicly accessible, accompanied by a leaderboard to foster advancements in text-rich visual comprehension with MLLMs.
Check out the Paper and Project page. All credit for this research goes to the researchers of this project. Also, don’t forget to follow us on Twitter. Join our Telegram Channel, Discord Channel, and LinkedIn Group.
If you like our work, you will love our newsletter..
Don’t Forget to join our 40k+ ML SubReddit
The post SEED-Bench-2-Plus: An Extensive Benchmark Specifically Designed for Evaluating Multimodal Large Language Models (MLLMs) in Text-Rich Scenarios appeared first on MarkTechPost.
#AIPaperSummary #AIShorts #Applications #ArtificialIntelligence #ComputerVision #EditorsPick #Staff #TechNews #Technology [Source: AI Techpark]