


SciPhi has recently announced the release of Triplex, a state-of-the-art language model (LLM) designed specifically for knowledge graph construction. This open-source innovation is poised to revolutionize how large quantities of unstructured data are converted into structured formats, significantly reducing the cost and complexity traditionally associated with this process. Available on platforms like HuggingFace and Ollama, Triplex is set to become a key tool for data scientists and analysts seeking efficient, cost-effective solutions.
Triplex is engineered to construct knowledge graphs efficiently, surpassing advanced models like GPT-4o. Knowledge graphs are vital for answering complex relational queries, such as identifying company employees who attended specific educational institutions. However, the traditional methods of constructing these graphs have been prohibitively expensive and resource-intensive, limiting their widespread adoption. For instance, while innovative, the recent GraphRAG procedure by Microsoft remains cost-intensive, requiring at least one output token for every input token, making it impractical for many applications.
Triplex aims to disrupt this paradigm by offering a tenfold reduction in the cost of generating knowledge graphs. This cost efficiency is achieved by converting unstructured text into “semantic triples,” the foundational elements of knowledge graphs.
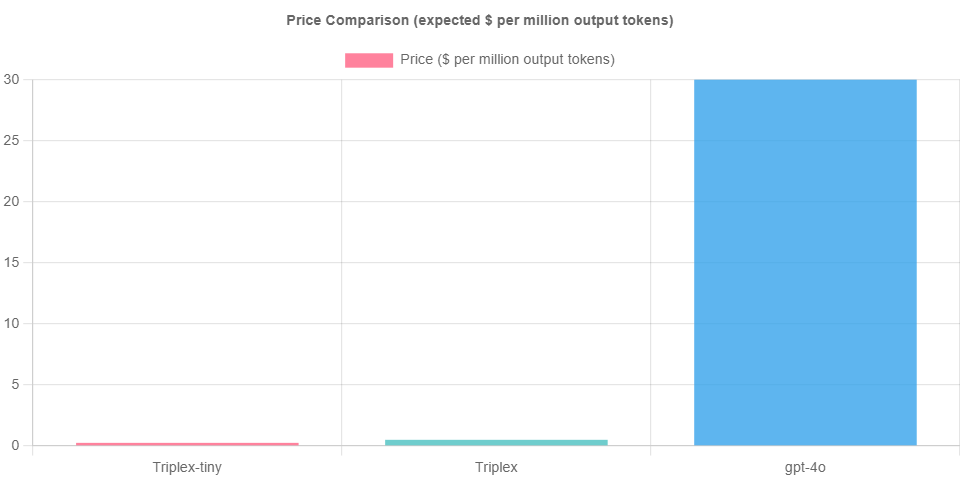
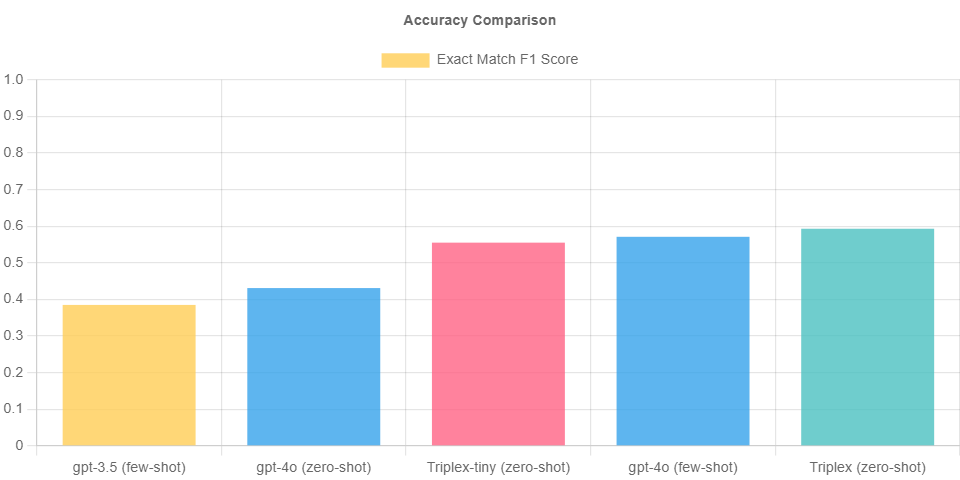
Triplex has been rigorously evaluated against GPT-4o, demonstrating superior performance in both cost and accuracy. Its triple extraction model achieves results comparable to GPT-4o but at a fraction of the cost. This remarkable cost reduction is attributed to Triplex’s smaller model size and capability to function without extensive few-shot context.
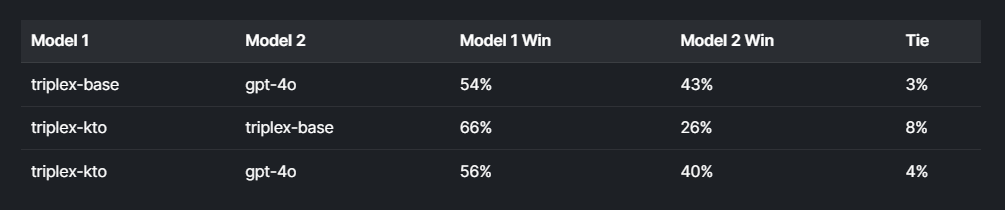
To further enhance its performance, Triplex has undergone additional training using DPO (Dynamic Programming Optimization) and KTO (Knowledge Triplet Optimization). These steps involved generating preference-based datasets through majority voting and topological sorting. The improved model was then assessed using the Claude-3.5 Sonnet evaluation, comparing Triplex with other models like triplex-base and triplex-kto. The results indicated a notable edge for Triplex, with win rates surpassing 50% in head-to-head comparisons with GPT-4o.
Triplex’s exceptional performance is underpinned by its extensive training on a diverse and comprehensive dataset, including authoritative sources like DBPedia and Wikidata, web-based texts, and synthetically generated datasets. This eclectic training ensures that Triplex is versatile and robust across various applications.
One immediate application of Triplex is local knowledge graph construction using the R2R RAG engine in conjunction with Neo4J. This application, which was previously less viable due to cost and complexity, is now more accessible thanks to the efficiencies introduced by Triplex.
In conclusion, SciPhi’s release of Triplex dramatically reduces the cost and complexity of converting unstructured data into structured formats; Triplex opens up new possibilities for data analysis and insight generation. This innovation promises to enhance the efficiency of existing processes and make advanced data representation techniques accessible to various applications and industries.
Check out the Model on HF and Ollama. You can find more details here. All credit for this research goes to the researchers of this project. Also, don’t forget to follow us on Twitter and join our Telegram Channel and LinkedIn Group. If you like our work, you will love our newsletter..
Don’t Forget to join our 46k+ ML SubReddit
Find Upcoming AI Webinars here
The post SciPhi Open Sourced Triplex: A SOTA LLM for Knowledge Graph Construction Provides Data Structuring with Cost-Effective and Efficient Solutions appeared first on MarkTechPost.
#AIShorts #Applications #ArtificialIntelligence #EditorsPick #LanguageModel #LargeLanguageModel #Staff #TechNews #Technology [Source: AI Techpark]