


Natural language processing (NLP) in artificial intelligence focuses on enabling machines to understand and generate human language. This field encompasses a variety of tasks, including language translation, sentiment analysis, and text summarization. In recent years, significant advancements have been made, leading to the development of large language models (LLMs) that can process vast amounts of text. These advancements have opened up possibilities for complex tasks such as long-context summarization and retrieval-augmented generation (RAG).
One of the major challenges in NLP is effectively evaluating the performance of LLMs on tasks that require processing long contexts. Traditional tasks, such as Needle-in-a-Haystack, do not provide the complexity needed to differentiate the capabilities of the latest models. Furthermore, evaluating the quality of outputs for these tasks is challenging due to the need for high-quality reference summaries and reliable automatic metrics. This gap in evaluation methods hinders the accurate assessment of modern LLMs.
Existing methods for evaluating summarization performance often focus on short-input, single-document settings. These methods rely heavily on low-quality reference summaries, which correlate poorly with human judgments. Although there are some benchmarks for long-context models, such as Needle-in-a-Haystack and book summarization, they need to sufficiently test the full capabilities of state-of-the-art LLMs. This limitation underscores the need for more comprehensive and reliable evaluation methods.
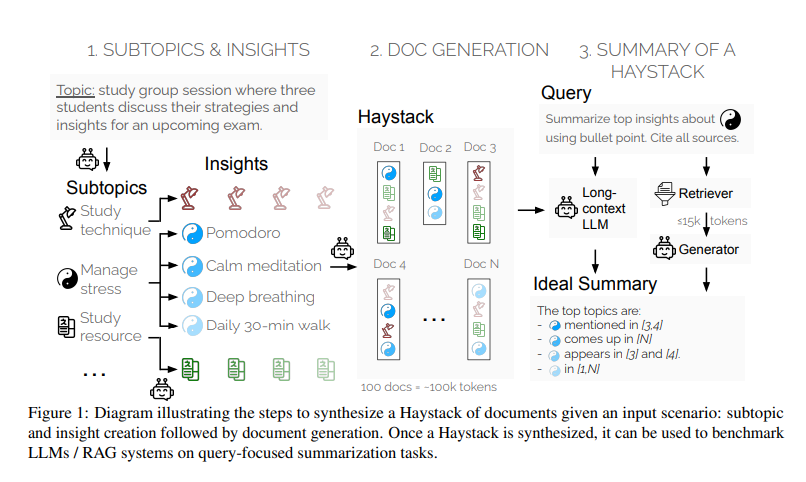
Researchers at Salesforce AI Research introduced a novel evaluation method called the “Summary of a Haystack” (SummHay) task. This method aims to evaluate long-context models and RAG systems more effectively. The researchers created synthetic Haystacks of documents, ensuring specific insights were repeated across these documents. The SummHay task requires systems to process these Haystacks, generate summaries that accurately cover the relevant insights, and cite the source documents. This approach provides a reproducible and comprehensive framework for evaluation.
The methodology involves several detailed steps. First, researchers generate Haystacks of documents on specific topics, ensuring certain insights are repeated across these documents. Each Haystack typically contains around 100 documents, totaling approximately 100,000 tokens. The documents are carefully designed to include specific insights categorized into various subtopics. For instance, subtopics might consist of study techniques and stress management in a topic about exam preparation, each expanded into distinct insights.
Once the Haystacks are generated, the SummHay task is framed as a query-focused summarization task. Systems are given queries related to the subtopics and must generate summaries in bullet-point format. Each summary must cover the relevant insights and cite the source documents precisely. The evaluation protocol then assesses the summaries on two main aspects: coverage of the expected insights and the quality of the citations. This rigorous process ensures high reproducibility and accuracy in the evaluation.
Regarding performance, the research team conducted a large-scale evaluation of 10 LLMs and 50 RAG systems. Their findings indicated that the SummHay task remains a significant challenge for current systems. For example, even when systems were provided with oracle signals of document relevance, they lagged behind human performance by over 10 points on a joint score. Specifically, long-context LLMs like GPT-4o and Claude 3 Opus scored below 20% on SummHay without a retriever. The study also highlighted the trade-offs between RAG systems and long-context models. RAG systems typically improve citation quality at the expense of insight coverage.
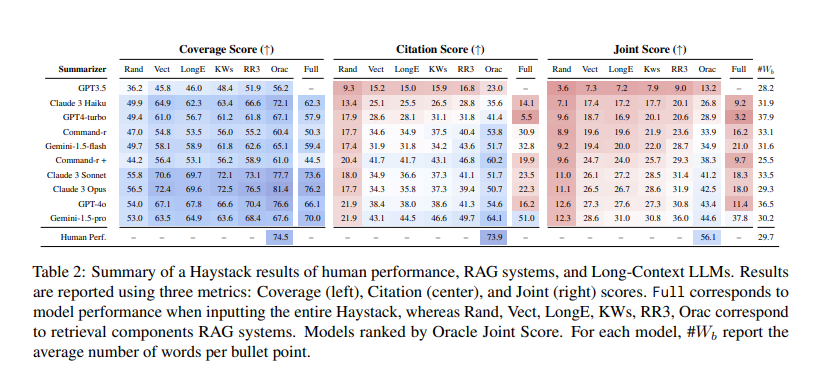
The performance evaluation revealed that current models struggle to meet human performance levels. For instance, when using an advanced RAG component like Cohere’s Rerank3, the end-to-end performance on the SummHay task showed substantial improvements. However, even with these enhancements, models like Claude 3 Opus and GPT-4o could only achieve a joint score of around 36%, significantly below the estimated human performance of 56%. This gap underscores the need for further advancements in the field.
In conclusion, the research conducted by Salesforce AI Research addresses a critical gap in evaluating long-context LLMs and RAG systems. The SummHay benchmark provides a robust framework for assessing the capabilities of these systems, highlighting significant challenges and areas for improvement. Despite current systems underperforming compared to human benchmarks, this research paves the way for future developments that could eventually match or surpass human performance in long-context summarization.
Check out the Paper and GitHub. All credit for this research goes to the researchers of this project. Also, don’t forget to follow us on Twitter.
Join our Telegram Channel and LinkedIn Group.
If you like our work, you will love our newsletter..
Don’t Forget to join our 46k+ ML SubReddit
The post Salesforce AI Research Introduces SummHay: A Robust AI Benchmark for Evaluating Long-Context Summarization in LLMs and RAG Systems appeared first on MarkTechPost.
#AIPaperSummary #AIShorts #Applications #ArtificialIntelligence #EditorsPick #LanguageModel #LargeLanguageModel #Staff #TechNews #Technology [Source: AI Techpark]