


Large Language Models (LLMs) have revolutionized natural language processing, demonstrating exceptional performance across various tasks. The Scaling Law suggests that as model size increases, LLMs develop emergent abilities, enhancing their context understanding and long sequence handling capabilities. This growth enables LLMs to generate coherent responses and power applications like document summarization, code generation, and conversational AI. However, LLMs face significant challenges in terms of cost and efficiency. The expenses associated with LLM generation escalate with increasing model size and sequence length, affecting both the training and inference stages. Additionally, managing long sequences presents computational burdens due to the quadratic complexity of the transformer attention mechanism, which scales poorly with sequence length. These challenges necessitate the development of efficient LLM architectures and strategies to reduce memory consumption, particularly in long-context scenarios.
Existing researchers have pursued various approaches to address the computational challenges posed by LLMs, particularly in long-context scenarios. KV cache eviction methods like StreamingLLM, H2O, SnapKV, and FastGen aim to reduce memory usage by selectively retaining or discarding tokens based on their importance. PyramidKV and PyramidInfer propose adjusting KV cache sizes across different layers. KV cache quantization techniques, such as SmoothQuant and Q-Hitter, compress the cache while minimizing performance loss. Some studies suggest different quantization strategies for key and value caches. Structured pruning of LLMs has also been explored, focusing on removing unimportant layers, heads, and hidden dimensions. However, these methods often result in significant performance degradation or fail to exploit potential optimizations fully.
Researchers from Salesforce AI Research and The Chinese University of Hong Kong propose ThinK, a unique KV cache pruning method that approaches the task as an optimization problem to minimize attention weight loss from pruning. It introduces a query-dependent criterion for assessing channel importance and selects critical channels greedily. The method is founded on key observations from LLaMA3-8B model visualizations: key cache channels show varying magnitudes of significance, while value cache lacks clear patterns. The singular value decomposition of attention matrices reveals that few singular values carry high energy, indicating the attention mechanism’s low-rank nature. These insights suggest that key cache can be effectively approximated using low-dimensional vectors. ThinK utilizes these findings to develop an efficient pruning strategy targeting the key cache’s channel dimension, potentially reducing memory consumption while preserving model performance.
ThinK is an innovative method for optimizing the KV cache in LLMs by pruning the channel dimension of the key cache. The approach formulates the pruning task as an optimization problem, aiming to minimize the difference between original and pruned attention weights. ThinK introduces a query-driven pruning criterion that evaluates channel importance based on the interaction between the query and key vectors. This method uses a greedy algorithm to select the most important channels, preserving the primary information flow in the attention computation.
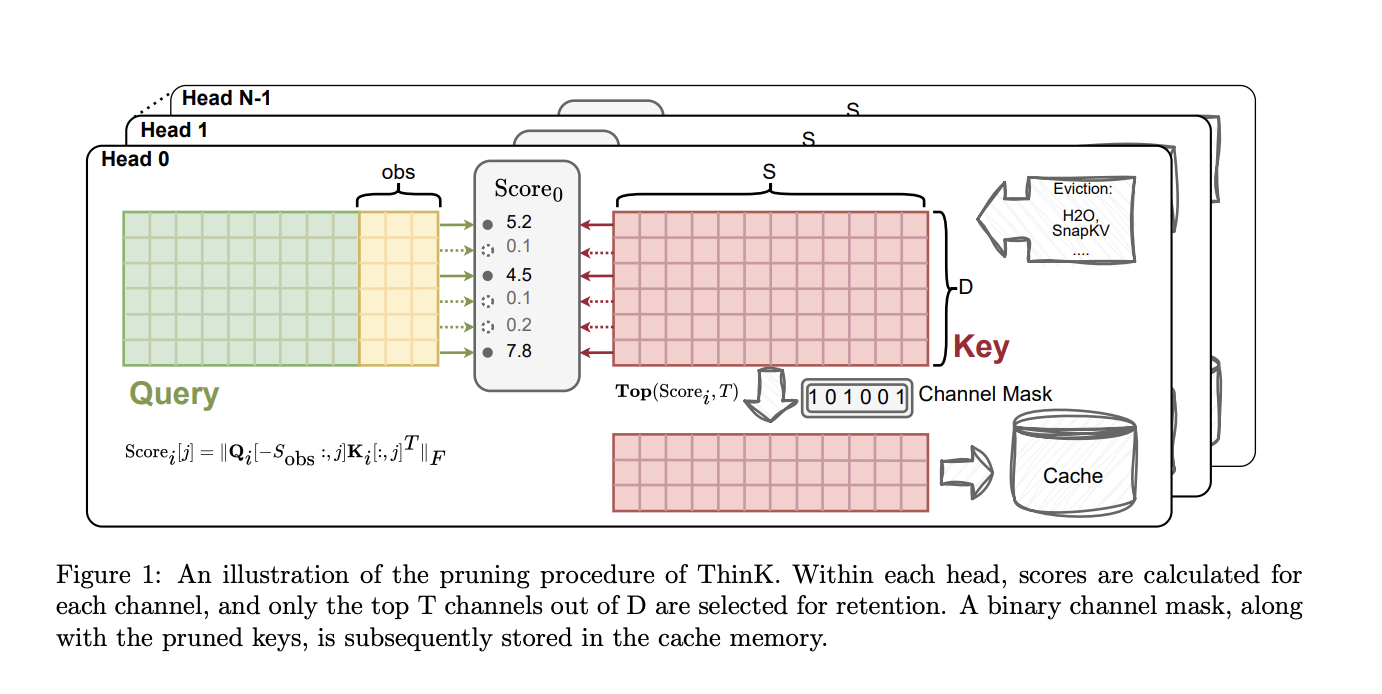
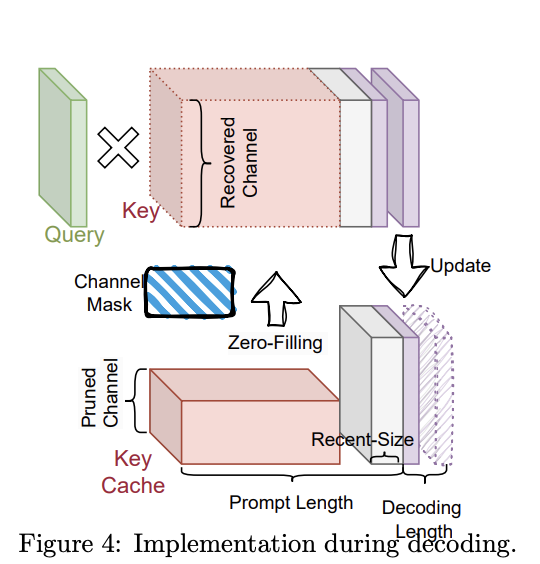
The implementation focuses on long-context scenarios and employs an observation window to reduce computational costs. ThinK maintains two categories of keys in the KV cache: pruned keys with reduced channel size and unpruned keys at original size. A binary mask tracks pruned channels. During decoding, pruned keys are zero-filled and concatenated with unpruned keys, or the query is pruned before multiplication with the corresponding keys. This approach can be integrated with optimization techniques like FlashAttention, potentially offering improved computational efficiency while maintaining model performance.
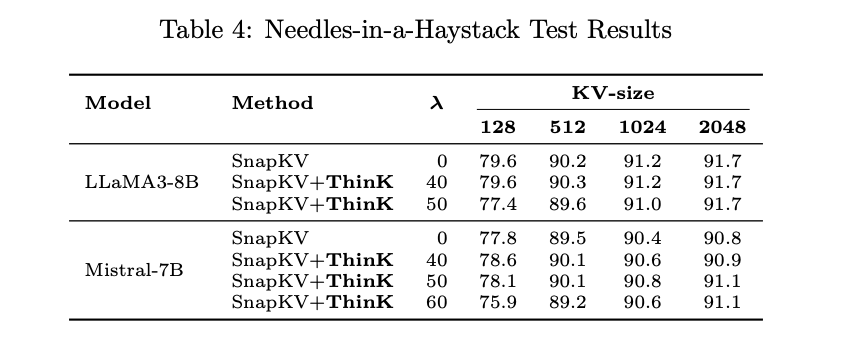
The experimental results demonstrate the effectiveness of ThinK, a unique key cache pruning method, across two major benchmarks: LongBench and Needle-in-a-Haystack. Key findings include:
- ThinK successfully prunes key cache channels after applying existing compression methods (H2O and SnapKV), reducing memory usage while maintaining or slightly improving performance on LLaMA3-8B. For Mistral-7B, it reduces memory with minimal performance impact.
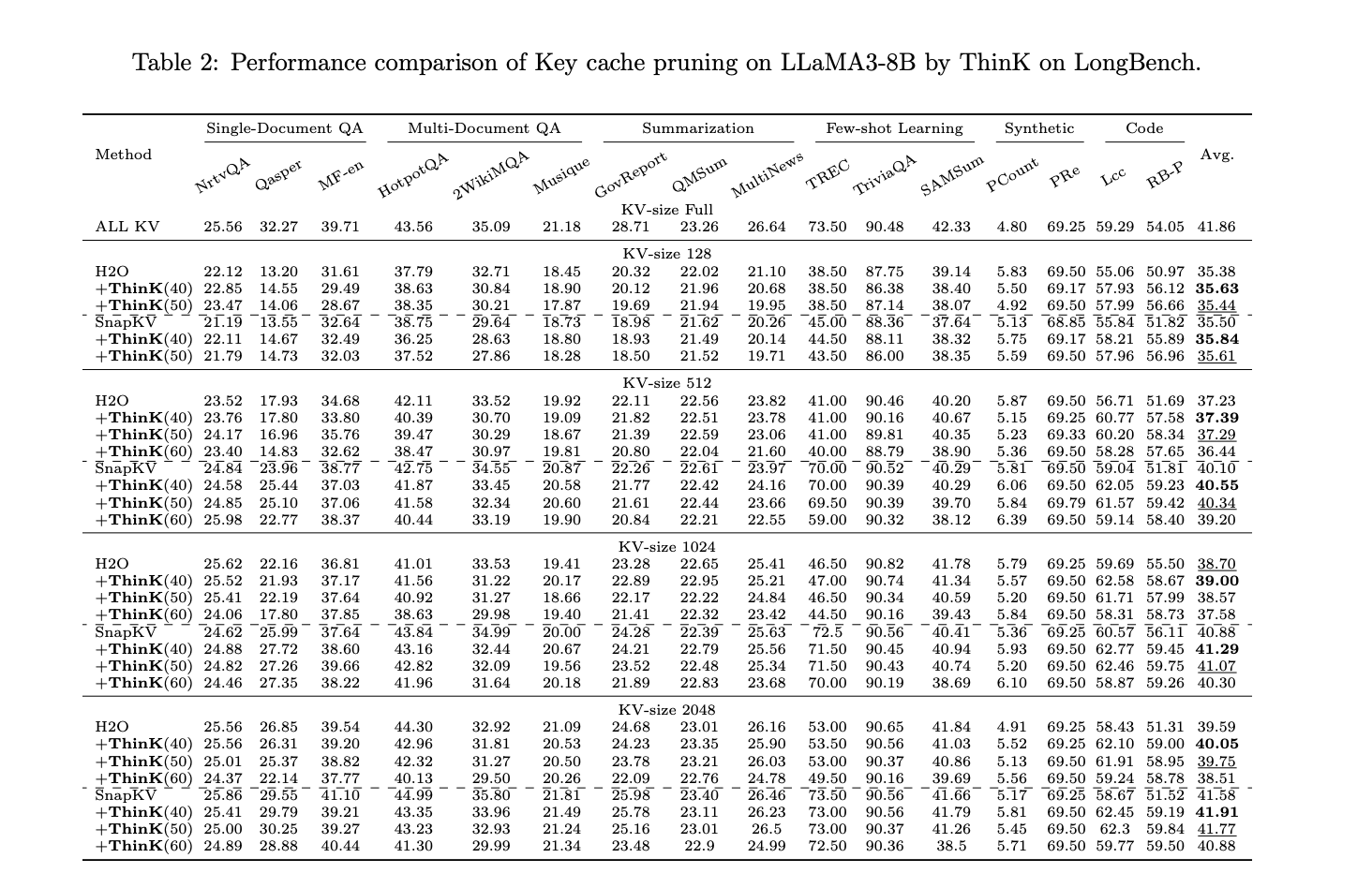
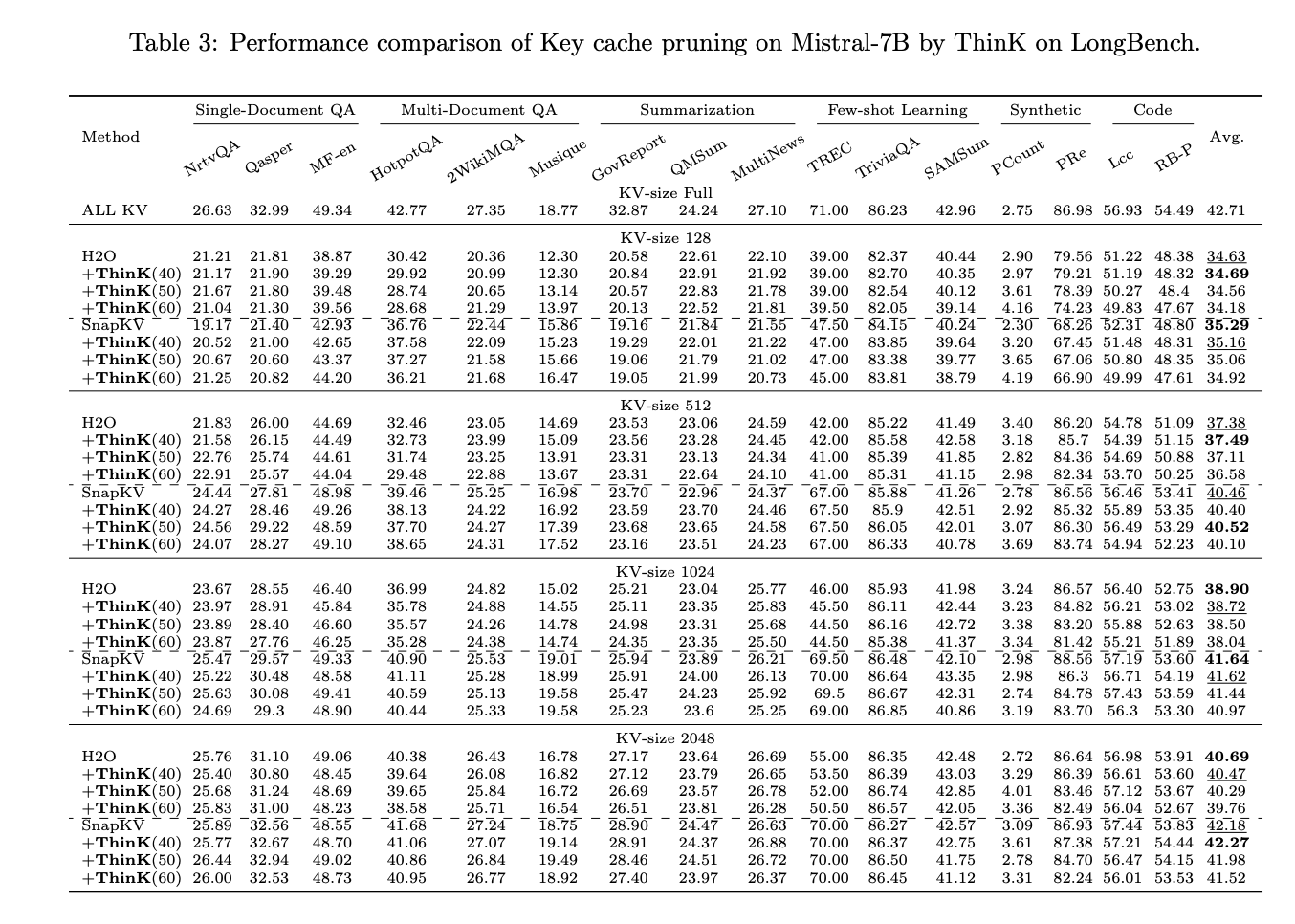
- Query-based channel pruning (ThinK) outperforms l1 and l2 norm-based pruning methods, especially at a 40% pruning ratio.
- Performance tends to be better with smaller pruning ratios and larger KV cache sizes. With a KV cache size of 2048 and 40% pruning, ThinK can even outperform full KV cache models in some cases.
- On the Needle-in-a-Haystack test, ThinK maintains or improves accuracy compared to SnapKV at a 40% pruning ratio across different KV cache sizes. Higher pruning ratios (≥50%) show some accuracy drops, particularly with smaller cache sizes.
- Visualizations of the Needle-in-a-Haystack results demonstrate ThinK’s robustness in maintaining retrieval capabilities across various token lengths and depths.
These results suggest that ThinK is an effective, model-agnostic method for further optimizing KV cache compression, offering improved memory efficiency with minimal performance trade-offs.
ThinK emerges as a promising advancement in optimizing Large Language Models for long-context scenarios. By introducing query-dependent channel pruning for the key cache, this innovative method achieves a 40% reduction in cache size while maintaining or even improving performance. ThinK’s compatibility with existing optimization techniques and its robust performance across various benchmarks, including LongBench and Needle-in-a-Haystack tests, underscore its effectiveness and versatility. As the field of natural language processing continues to evolve, ThinK’s approach to balancing efficiency and performance addresses critical challenges in managing computational resources for LLMs. This method not only enhances the capabilities of current models but also paves the way for more efficient and powerful AI systems in the future, potentially revolutionizing how we approach long-context processing in language models.
Check out the Paper. All credit for this research goes to the researchers of this project. Also, don’t forget to follow us on Twitter and join our Telegram Channel and LinkedIn Group. If you like our work, you will love our newsletter..
Don’t Forget to join our 47k+ ML SubReddit
Find Upcoming AI Webinars here
The post Salesforce AI Introduces ‘ThinK’: A New AI Method that Exploits Substantial Redundancy Across the Channel Dimension of the KV Cache appeared first on MarkTechPost.
#AIPaperSummary #AIShorts #Applications #ArtificialIntelligence #EditorsPick #LanguageModel #LargeLanguageModel #Staff #TechNews #Technology [Source: AI Techpark]