


The digital age has been significantly marked by the advent and evolution of Large Language Models (LLMs), which have become cornerstones in developing applications that require nuanced understanding and generation of human-like text. The exponential growth of these models, with Hugging Face listing a staggering 469,848 models as of January 2024, has ushered in a new era of artificial intelligence. However, this proliferation brings to the forefront a daunting challenge for developers and researchers alike: selecting the most suitable LLM that optimizes both performance and cost-efficiency.
One important challenge within this field is optimizing the deployment of these models to balance cost and performance effectively. The challenge is further compounded by the economic implications of utilizing proprietary models like GPT-4, which, despite their superior performance, come with steep usage costs. This scenario necessitates a solution that can navigate the vast seas of LLMs, identifying the optimal model for a given task without necessitating deep dives into the specifics of each model.
Numerous strategies have been proposed in the existing ecosystem to enhance the performance of individual LLMs while managing costs. These techniques range from fine-tuning models for specific tasks to employing quantization and system optimization methods. Despite these efforts, LLMs’ sheer number and diversity present a complex puzzle for users aiming to navigate this space efficiently.
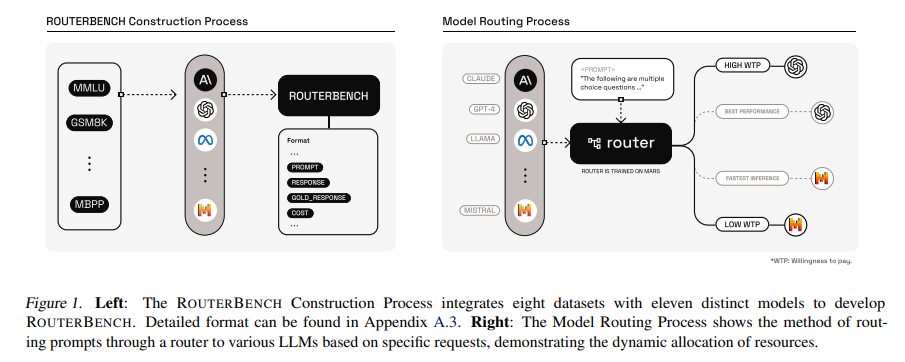
Researchers from Martian, UC Berkeley, and UC San Diego introduce ROUTERBENCH, a comprehensive benchmark for assessing the efficacy of LLM routing systems. This novel framework offers a systematic means to evaluate router performance, paving the way for more informed and strategic model deployment. It is based on routing, a method that dynamically selects the optimal LLM for each input. This approach simplifies the selection process and leverages the diversity of available LLMs, ensuring that the strengths of various models are utilized to their fullest potential.
The benchmark designed for evaluating LLM routing systems marks a significant leap forward. This benchmark encompasses over 405k inference outcomes from diverse LLMs and offers a standardized framework for assessing routing strategies, thereby setting the stage for informed decision-making in LLM deployment. This initiative reflects a concerted effort to address the twin objectives of maintaining high performance while mitigating economic costs.
The research findings underscore the importance of efficient model routing in maximizing the utility of LLMs. The study lays the groundwork for future advancements in this area by demonstrating the effectiveness of the ROUTERBENCH benchmark. It emphasizes the need for continuous innovation in routing strategies to keep up with the evolving LLM landscape, ensuring that these powerful models’ deployment remains cost-effective and performance-oriented.
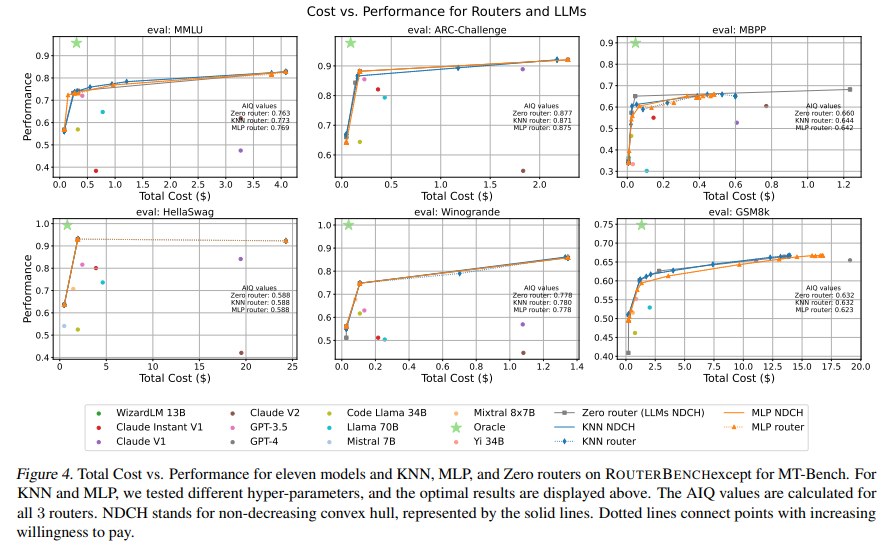
In conclusion, ROUTERBENCH represents a pivotal advancement in addressing the complex challenge of effectively deploying LLMs. Through its comprehensive dataset and innovative evaluation framework, ROUTERBENCH equips developers and researchers with the tools needed to navigate the vast landscape of LLMs. This initiative enhances the strategic deployment of these models and fosters a deeper understanding of the economic and performance considerations at play.
Check out the Paper, Github, and Blog. All credit for this research goes to the researchers of this project. Also, don’t forget to follow us on Twitter. Join our Telegram Channel, Discord Channel, and LinkedIn Group.
If you like our work, you will love our newsletter..
Don’t Forget to join our 39k+ ML SubReddit
Introducing RouterBench, the first comprehensive benchmark for evaluating LLM routers!
A collaboration between @withmartian and Prof. @KurtKeutzer at @UCBerkeley, we've created the first holistic framework to assess LLM routing systems.1/8
To read more:…
— Jason Hu (@onjas_buidl) March 29, 2024

The post RouterBench: A Novel Machine Learning Framework Designed to Systematically Assess the Efficacy of LLM Routing Systems appeared first on MarkTechPost.
#AIPaperSummary #AIShorts #Applications #ArtificialIntelligence #EditorsPick #LanguageModel #LargeLanguageModel #Staff #TechNews #Technology [Source: AI Techpark]