


Zero-shot learning is an advanced machine learning technique that enables models to make predictions on tasks without having been explicitly trained on them. This revolutionary paradigm bypasses extensive data collection and training, relying instead on pre-trained models that can generalize across different tasks. Zero-shot models leverage knowledge acquired during pre-training, allowing them to infer information about new, unseen tasks by drawing parallels with their existing knowledge base. This capability is particularly valuable in rapidly evolving fields where new tasks emerge frequently, and collecting and annotating data for each new task would be impractical.
A major issue in zero-shot models is their inherent vulnerability to biases and unintended correlations from their training on large-scale datasets. These biases can significantly affect the model’s performance, especially when the processed data deviates from the training data distribution. For instance, a zero-shot model trained predominantly on images of waterbirds might erroneously associate any image with a water background as a waterbird. This decreases accuracy and reliability, particularly for data slices that break these in-distribution correlations, leading to poor generalization on rare or atypical instances. The challenge, therefore, lies in developing methods to mitigate these biases without compromising the core advantage of zero-shot models: their ability to perform out of the box.
Current approaches to address biases in zero-shot models often involve fine-tuning with labeled data to enhance robustness. These methods, although effective, undermine the primary benefit of zero-shot learning by reintroducing the need for additional training. For example, some strategies detect spurious attributes and fine-tune models using these descriptions, while others employ specialized contrastive losses to train adapters on frozen embeddings. Another line of research focuses on debiasing word and multimodal embeddings by manually identifying and removing unwanted concepts. However, these methods are labor-intensive and require domain-specific expertise, limiting their scalability and applicability across diverse tasks.
Researchers from the University of Wisconsin-Madison have developed ROBOSHOT, a novel method designed to robustify zero-shot models without needing labeled data, training, or manual specification. This innovative approach harnesses insights from language models to identify and mitigate biases in model embeddings. ROBOSHOT leverages the ability of language models to generate useful insights from task descriptions. These insights are embedded and used to adjust the components of the model’s latent representations, effectively removing harmful elements and boosting beneficial ones. This process is entirely unsupervised, maintaining the zero-shot characteristic of the model while significantly enhancing its robustness.
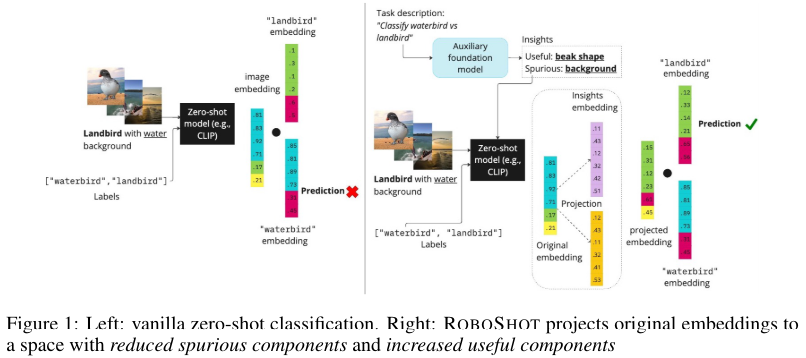
ROBOSHOT works by first obtaining insights from language models using task descriptions. These insights help identify both harmful and beneficial components within the embeddings. The system then modifies these embeddings to neutralize harmful components and emphasize beneficial ones. For instance, in a classification task, ROBOSHOT can adjust the model’s representations to reduce the impact of background correlations (like associating water with waterbirds) and enhance the focus on relevant features (such as the bird’s characteristics). This adjustment is achieved through simple vector operations that project original embeddings to spaces with reduced spurious components and increased useful components. This method provides a theoretical model that captures and quantifies failures in zero-shot models and characterizes the conditions under which ROBOSHOT can enhance performance.
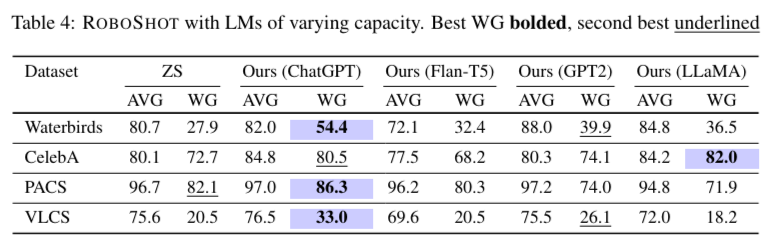
Empirical evaluations of ROBOSHOT on nine image and NLP classification tasks demonstrate its effectiveness. The method achieves an average improvement of 15.98% in worst-group accuracy, a critical metric for evaluating robustness, while maintaining or slightly improving overall accuracy. For example, the system significantly improves performance on the Waterbirds dataset by reducing the harmful correlation between water backgrounds and waterbird labels. Similar improvements are observed across other datasets, including CelebA, PACS, VLCS, and CXR14, indicating the method’s versatility and robustness. These results underscore the potential of ROBOSHOT to enhance the robustness of zero-shot models without the need for additional data or training.

In conclusion, the research addresses the critical issue of bias in zero-shot learning by introducing ROBOSHOT, a method that leverages language model insights to adjust embeddings and enhance robustness. This approach effectively mitigates biases without needing labeled data or training, preserving the core advantage of zero-shot models. By improving worst-group accuracy and overall performance across multiple tasks, ROBOSHOT offers a practical and efficient solution for enhancing the reliability and applicability of zero-shot models.
Check out the Paper. All credit for this research goes to the researchers of this project. Also, don’t forget to follow us on Twitter. Join our Telegram Channel, Discord Channel, and LinkedIn Group.
If you like our work, you will love our newsletter..
Don’t Forget to join our 43k+ ML SubReddit | Also, check out our AI Events Platform
The post ROBOSHOT by University of Wisconsin-Madison Enhancing Zero-Shot Learning Robustness: A Novel Machine Learning Approach to Bias Mitigation appeared first on MarkTechPost.
#AIPaperSummary #AIShorts #Applications #ArtificialIntelligence #EditorsPick #LargeLanguageModel #MachineLearning #Staff #TechNews #Technology [Source: AI Techpark]