


Large language models (LLMs) have emerged as powerful tools in artificial intelligence, demonstrating remarkable capabilities in understanding and generating text. These models utilize advanced technologies such as web-scale unsupervised pretraining, instruction fine-tuning, and value alignment, showcasing strong performance across various tasks. However, the application of LLMs to real-world big data presents significant challenges, primarily due to the enormous costs involved. By 2025, the total cost of LLMs is projected to reach nearly $5,000 trillion, far exceeding the GDP of major economies. This financial burden is particularly pronounced in processing text and structured data, which account for a substantial portion of the expenses despite being smaller in volume compared to multimedia data. As a result, there has been a growing focus on Relational Table Learning (RTL) in recent years, given that relational databases host approximately 73% of the world’s data.
Researchers from Shanghai Jiao Tong University and Tsinghua University present rLLM (relationLLM) project, which addresses the challenges in RTL by providing a platform for rapid development of RTL-type methods using LLMs. This innovative approach focuses on two key functions: decomposing state-of-the-art Graph Neural Networks (GNNs), LLMs, and Table Neural Networks (TNNs) into standardized modules, and enabling the construction of robust models through a “combine, align, and co-train” methodology. To demonstrate the application of rLLM, a simple RTL method called BRIDGE is introduced. BRIDGE processes table data using TNNs and utilizes “foreign keys” in relational tables to establish relationships between table samples, which are then analyzed using GNNs. This method considers multiple tables and their interconnections, providing a comprehensive approach to relational data analysis. Also, to address the scarcity of datasets in the emerging field of RTL, the project introduces a robust data collection named SJTUTables, comprising three relational table datasets: TML1M, TLF2K, and TACM12K.
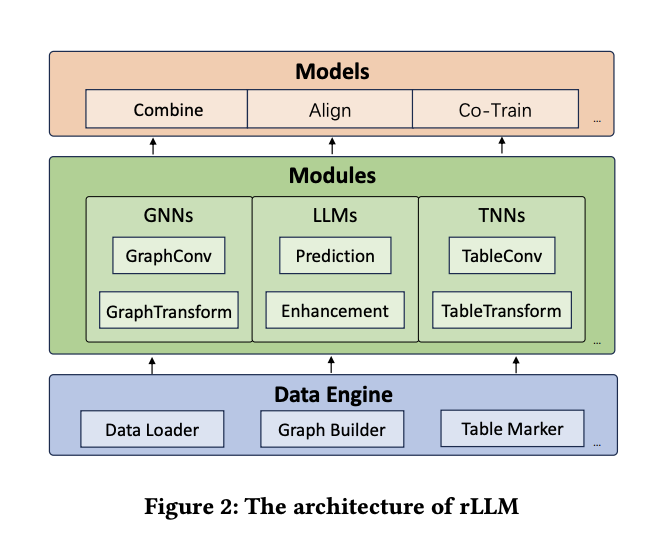
The rLLM project introduces a comprehensive architecture consisting of three main layers: the Data Engine Layer, the Module Layer, and the Model Layer. This structure is designed to facilitate efficient processing and analysis of relational table data.
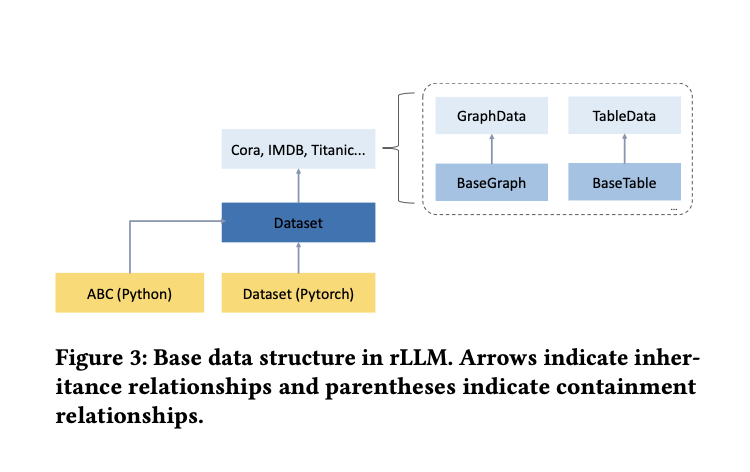
The Data Engine Layer forms the foundation, focusing on fundamental data structures for graph and table data. It decouples data loading and storage through Dataset subclasses and BaseGraph/BaseTable subclasses, respectively. This design allows for flexible handling of various graph and table data types, optimizing storage and processing for both homogeneous and heterogeneous graphs, as well as table data.
The Module Layer decomposes operations of GNNs, LLMs, and TNNs into standard submodules. For GNNs, it includes GraphTransform for preprocessing and GraphConv for implementing graph convolution layers. LLM modules comprise a Predictor for data annotation and an Enhancer for data augmentation. TNN modules feature TableTransform for mapping features to higher-dimensional spaces and TableConv for multi-layer interactive learning among feature columns.
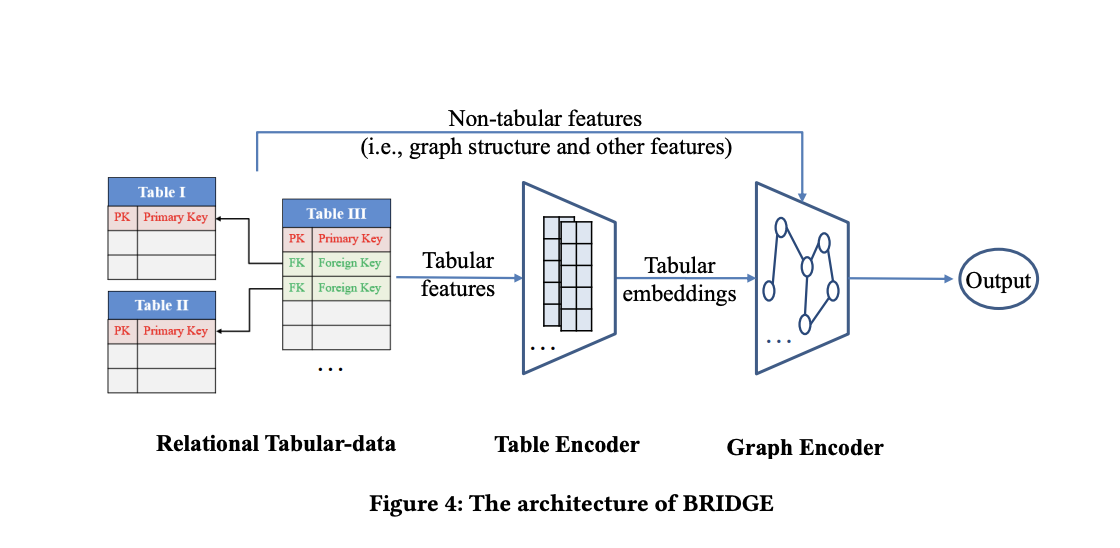
BRIDGE demonstrates rLLM’s application in RTL-type methods. It addresses relational database complexity by processing both table and non-table features. A Table Encoder, using TableTransform and TableConv modules, handles heterogeneous table data to produce table embeddings. A Graph Encoder, employing GraphTransform and GraphConv modules, models foreign key relationships and generates graph embeddings. BRIDGE integrates outputs from both encoders, enabling simultaneous modeling of multi-table data and their interconnections. The framework supports both supervised and unsupervised training approaches, adapting to various data scenarios and learning objectives.
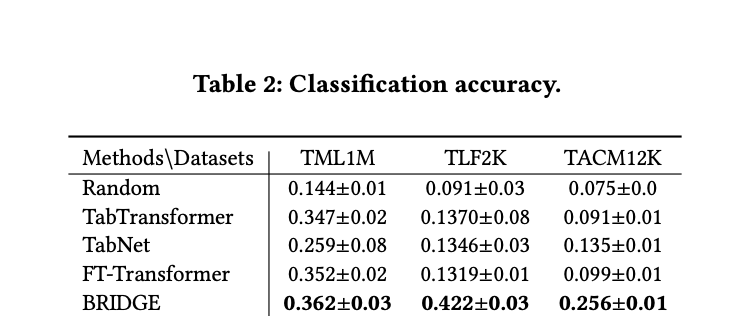
Experimental results reveal the limitations of traditional single-tabular TNNs in processing relational table data. These TNNs, confined to learning from a single target table, fail to utilize the rich information available in multiple tables and their interconnections, resulting in suboptimal performance. In contrast, the BRIDGE algorithm demonstrates superior capabilities by effectively combining a table encoder with a graph encoder. This integrated approach enables BRIDGE to extract valuable insights from both individual tables and their relationships. Consequently, BRIDGE achieves a significant performance improvement over conventional methods, highlighting the importance of considering the relational structure of data in table learning tasks.
The rLLM framework introduces a robust approach to relational table learning using Large Language Models. It integrates advanced methods and optimizes data structures for improved efficiency. The project invites collaboration from researchers and software engineers to expand its capabilities and applications in the field of relational data analysis.
Check out the Paper and GitHub. All credit for this research goes to the researchers of this project. Also, don’t forget to follow us on Twitter and join our Telegram Channel and LinkedIn Group. If you like our work, you will love our newsletter..
Don’t Forget to join our 47k+ ML SubReddit
Find Upcoming AI Webinars here
The post rLLM (relationLLM): A PyTorch Library Designed for Relational Table Learning (RTL) with Large Language Models (LLMs) appeared first on MarkTechPost.
#AIPaperSummary #AIShorts #Applications #ArtificialIntelligence #EditorsPick #MachineLearning #Staff #TechNews #Technology [Source: AI Techpark]