


Recent advancements in text-to-speech (TTS) synthesis have struggled to achieve high-quality results due to the complexity of speech, which involves various attributes like content, prosody, timbre, and acoustic details. While scaling up dataset size and model complexity has shown promise for zero-shot TTS, issues with voice quality, similarity, and prosody persist. Attempts to address these challenges involve decomposing speech into distinct subspaces representing different attributes for individual generations. However, effectively disentangling these attributes remains difficult despite approaches such as neural audio codecs based on residual vector quantization.
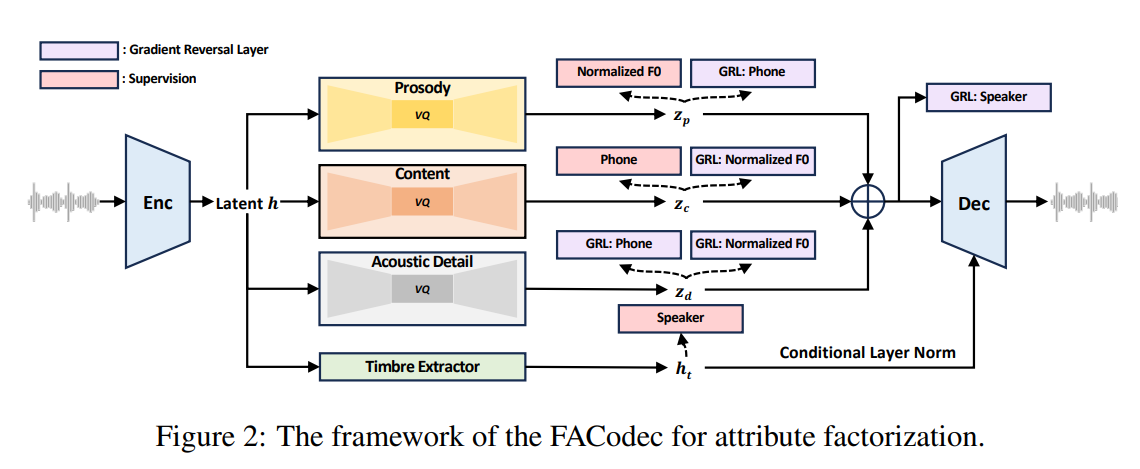
Researchers from Microsoft Research Asia & Microsoft Azure Speech, the University of Science and Technology of China, The Chinese University of Hong Kong, Zhejiang University, The University of Tokyo, and Peking University have developed a TTS system called NaturalSpeech 3. This system employs factorized diffusion models to generate high-quality speech in a zero-shot manner. The approach involves a neural codec with factorized vector quantization (FVQ) to disentangle speech waveform into distinct subspaces of content, prosody, timbre, and acoustic details. A factorized diffusion model generates attributes in each subspace based on corresponding prompts. This factorization simplifies speech representation, enabling efficient learning and improved attribute control.
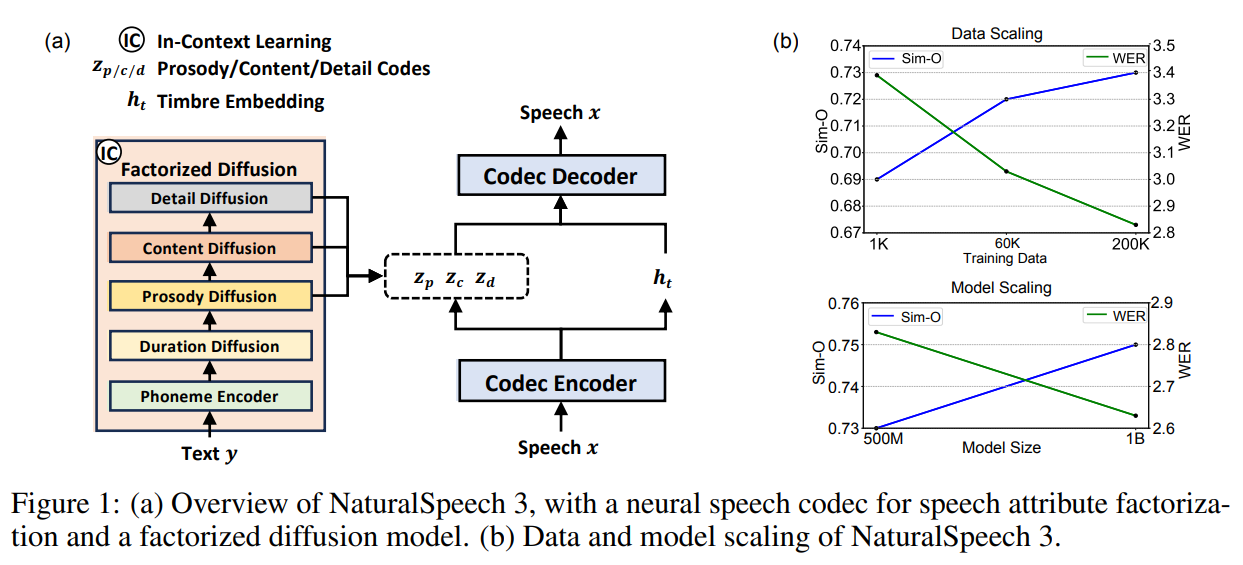
Recent advancements in TTS research have focused on four key areas: zero-shot synthesis, speech representations, generation methods, and attribute disentanglement. Zero-shot TTS aims to generate speech for unseen speakers using various data representations and modeling techniques. Speech representations have evolved from traditional waveform and mel-spectrogram-based approaches to more data-driven methods like discrete tokens and continuous vectors. Generation methods vary between autoregressive (AR) and non-autoregressive (NAR) models, with NAR models showing advantages in robustness and speed, while AR models offer better diversity and expressiveness. Attribute disentanglement techniques, such as those utilizing neural speech codecs, aim to separate speech attributes like content, prosody, and timbre for improved synthesis quality.
NaturalSpeech 3 is an advanced text-to-speech system prioritizing high quality, similarity, and control. It utilizes a neural speech codec (FACodec) and a factorized diffusion model to individually handle speech attributes like duration, prosody, content, acoustic details, and timbre. This approach ensures superior synthesis quality and controllability. Building on previous versions, it emphasizes diverse synthesis across various scenarios, leveraging large datasets for zero-shot synthesis. The FACodec employs factorized vector quantizers for efficient attribute representation, simplifying speech complexity. NaturalSpeech 3 offers efficient and effective synthesis with enhanced speech quality and controllability.
NaturalSpeech showcases better performance in speech quality, similarity, and robustness. Through extensive evaluation of LibriSpeech and RAVDESS datasets, NaturalSpeech 3 demonstrates significant advancements, particularly in generation quality, speaker similarity, and prosody similarity. Ablation studies validate the effectiveness of factorization, classifier-free guidance, and prosody representation. Moreover, the scalability analysis illustrates the system’s capability to improve with larger datasets and model sizes, emphasizing its potential for further enhancement.
In conclusion, NaturalSpeech 3 is a groundbreaking TTS system incorporating a neural speech codec, FACodec, and factorized diffusion models. NaturalSpeech 3 achieves remarkable advancements in speech quality, similarity, prosody, and intelligibility by disentangling speech attributes into distinct subspaces and synthesizing them with discrete diffusion. Moreover, it enables the manipulation of fine-grained speech attributes. Scaling the model to 1B parameters and 200K hours of data further enhances its performance. However, the system’s reliance on English data from LibriVox poses limitations in voice diversity and multilingual capabilities, which researchers aim to address through expanded data collection.
Check out the Paper. All credit for this research goes to the researchers of this project. Also, don’t forget to follow us on Twitter and Google News. Join our 38k+ ML SubReddit, 41k+ Facebook Community, Discord Channel, and LinkedIn Group.
If you like our work, you will love our newsletter..
Don’t Forget to join our Telegram Channel
You may also like our FREE AI Courses….
The post Revolutionizing Text-to-Speech Synthesis: Introducing NaturalSpeech-3 with Factorized Diffusion Models appeared first on MarkTechPost.
#AIPaperSummary #AIShorts #Applications #ArtificialIntelligence #EditorsPick #Staff #TechNews #Technology [Source: AI Techpark]