


Representational similarity measures are essential tools in machine learning, used to compare internal representations of neural networks. These measures help researchers understand learning dynamics, model behaviors, and performance by providing insights into how different neural network layers and architectures process information. Quantifying the similarity between representations is fundamental to many areas of artificial intelligence research, including model evaluation, transfer learning, and understanding the impacts of various training methodologies.
A significant challenge in this field is the need for comprehensive benchmarks to evaluate representational similarity measures. Existing measures are often developed in isolation, without systematic comparison to other methods. This ad-hoc approach leads to consistency in how these measures are validated and applied, making it difficult for researchers to assess their relative effectiveness. The problem is compounded by the diversity of neural network architectures and their various tasks. This means a similarity measure effective in one context might be less useful in another.
Existing methods for evaluating representational similarity include various ad-hoc measures, which have been proposed over time with different quality criteria. Some of the most popular measures, such as Canonical Correlation Analysis (CCA) and Representational Similarity Analysis (RSA), have been compared in specific studies. However, these comparisons are often limited to particular types of neural networks or specific datasets, needing a broad, systematic evaluation. There is a clear need for a comprehensive benchmark to provide a consistent framework for evaluating a wide range of similarity measures across various neural network architectures and datasets.
Researchers from University of Passau, German Cancer Research Center (DKFZ), DKFZ, University of Heidelberg, University of Mannheim, RWTH Aachen University, Heidelberg University Hospital, National Center for Tumor Diseases (NCT) Heidelberg 9GESIS – Leibniz Institute for the Social Sciences and Complexity Science Hub, introduced the Representational Similarity (ReSi) benchmark to address this gap. This benchmark is the first comprehensive framework designed to evaluate representational similarity measures. It includes six well-defined tests, 23 similarity measures, 11 neural network architectures, and six datasets spanning graph, language, and vision domains. The ReSi benchmark aims to provide a robust and extensible platform for systematically comparing the performance of different similarity measures.
The ReSi benchmark’s tests are meticulously designed to cover a range of scenarios. These tests include
- Correlation to accuracy difference, which evaluates how well a similarity measure can capture variations in model accuracy;
- Correlation to output difference, focusing on the differences in individual predictions;
- Label randomization, assessing the measure’s ability to distinguish models trained on randomized labels;
- Shortcut affinity, which tests the measure’s sensitivity to models using different features;
- Augmentation, evaluating robustness to input changes, and
- Layer monotonicity, checking if the measure can identify layer-wise transformations.
These tests are implemented across diverse neural network architectures, such as BERT, ResNet, and VGG, as well as datasets like Cora, Flickr, and ImageNet100.

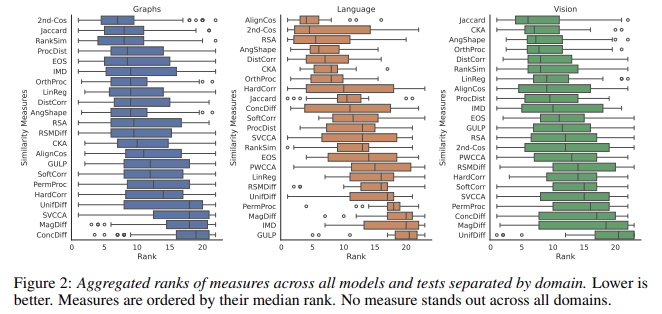
Evaluation of the ReSi benchmark revealed that no single similarity measure consistently outperformed others across all domains. For instance, second-order cosine and Jaccard similarities were particularly effective in the graph domain, while angle-based measures performed better for language models. Centered Kernel Alignment (CKA) excelled in vision models. These highlight the strengths and weaknesses of different measures, providing valuable guidance for researchers in selecting the most appropriate measure for specific needs.
Detailed results from the ReSi benchmark demonstrate the complexity and variability in evaluating representational similarity. For example, the Eigenspace Overlap Score (EOS) was excellent in distinguishing layers of a GraphSAGE model but could have been more effective in identifying shortcut features. Conversely, measures like Singular Value Canonical Correlation Analysis (SVCCA) correlated well with predictions from BERT models but less with other domains. This variability underscores the importance of using a comprehensive benchmark like ReSi to gain a nuanced understanding of each measure’s performance.
The ReSi benchmark significantly advances machine learning by providing a systematic and robust platform for evaluating representational similarity measures. Including a wide range of tests, architectures, and datasets enables a thorough assessment of each measure’s capabilities and limitations. Researchers can now make informed decisions when selecting similarity measures, ensuring they choose the most suitable ones for their specific applications. The benchmark’s extensibility also opens avenues for future research, allowing for the inclusion of new measures, models, and tests.

In conclusion, the ReSi benchmark fills a critical gap in evaluating representational similarity measures. It offers a comprehensive, systematic framework that enhances the understanding of how different measures perform across various neural network architectures and tasks. This benchmark facilitates more rigorous and consistent evaluations and catalyzes future research by providing a solid foundation for developing and testing new similarity measures.
Check out the Paper. All credit for this research goes to the researchers of this project. Also, don’t forget to follow us on Twitter and join our Telegram Channel and LinkedIn Group. If you like our work, you will love our newsletter..
Don’t Forget to join our 47k+ ML SubReddit
Find Upcoming AI Webinars here
The post ReSi Benchmark: A Comprehensive Evaluation Framework for Neural Network Representational Similarity Across Diverse Domains and Architectures appeared first on MarkTechPost.
#AIPaperSummary #AIShorts #Applications #ArtificialIntelligence #EditorsPick #MachineLearning #Staff #TechNews #Technology [Source: AI Techpark]