


Integrating natural language understanding with image perception has led to the development of large vision language models (LVLMs), which showcase remarkable reasoning capabilities. Despite their progress, LVLMs often encounter challenges in accurately anchoring generated text to visual inputs, manifesting as inaccuracies like hallucinations of non-existent scene elements or misinterpretations of object attributes and relationships.
Researchers from The University of Texas at Austin and AWS AI propose the innovative framework ViGoR (Visual Grounding Through Fine-Grained Reward Modeling) as a solution. ViGoR advances the visual grounding of LVLMs beyond traditional baselines through fine-grained reward modeling, engaging both human evaluations and automated methods for enhancement. This approach is notably efficient, clarifying the extensive costs of comprehensive supervision typically required in such advancements.
ViGoR’s methodology is particularly notable for its strategic fine-tuning of pre-trained LVLMs, such as LLaVA. By introducing a series of images accompanied by prompts to the LVLM, it generates multiple textual outputs for each. Human annotators then assess these image-text pairs, assigning detailed, sentence-level scores based on the textual quality. This process cultivates a dataset encompassing image-text-evaluation triads. Subsequently, a reward model trained on this dataset refines the LVLM, significantly bolstering its visual grounding capabilities with a relatively modest dataset of 16,000 samples.
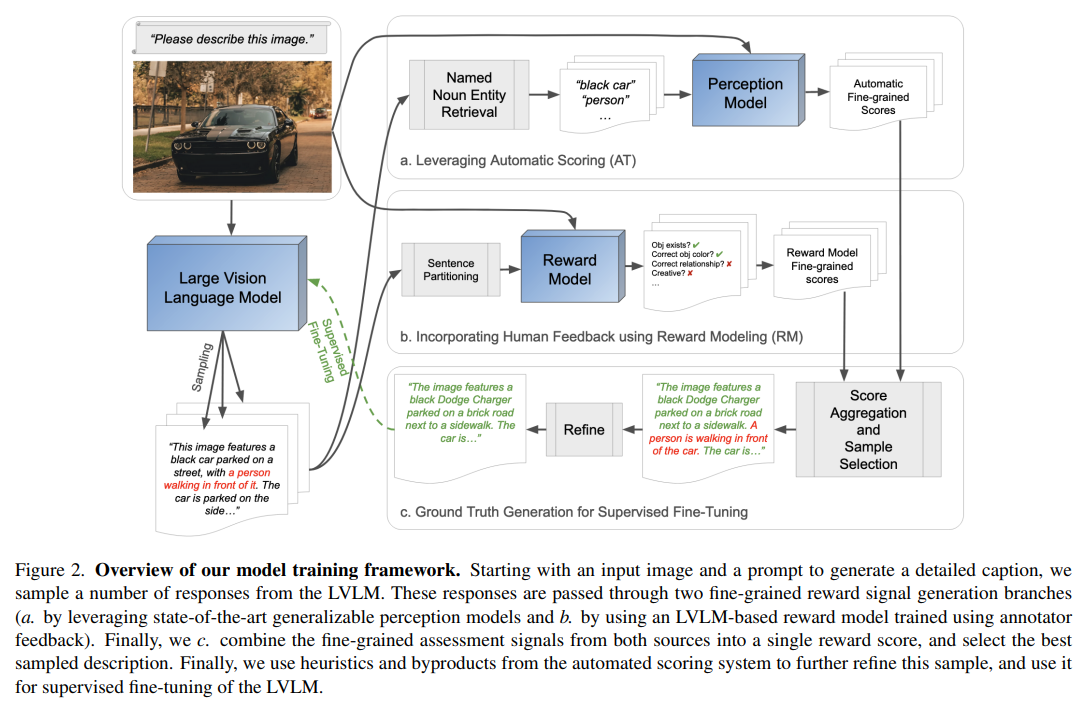
ViGoR integrates an ingenious automated method to construct the reward model without additional human labor, further enhancing the visual grounding efficacy of LVLMs. The synergy between human-evaluated and automated reward models underpins ViGoR’s comprehensive solution, markedly improving LVLM performance in accurately grounding text in visual stimuli.
ViGoR’s efficacy is underscored by its superior performance over existing baseline models across several benchmarks. A specially curated, challenging dataset designed to test LVLMs’ visual grounding capabilities further validated the framework’s success. To support continued research, the team plans to release their human annotation dataset, comprising around 16,000 images and generated text pairs with nuanced evaluations.
ViGoR stands out for several reasons:
- It introduces a broadly applicable framework utilizing fine-grained reward modeling to substantially enhance the visual grounding of LVLMs.
- Developing reward models requiring minimal human effort showcases significant improvements in visual grounding efficiency.
- A comprehensive and challenging dataset, MMViG, is constructed specifically to assess the visual grounding capabilities of LVLMs.
- A human evaluation dataset featuring 16K images and generated text pairs with detailed evaluations will be released, enriching resources for related research endeavors.
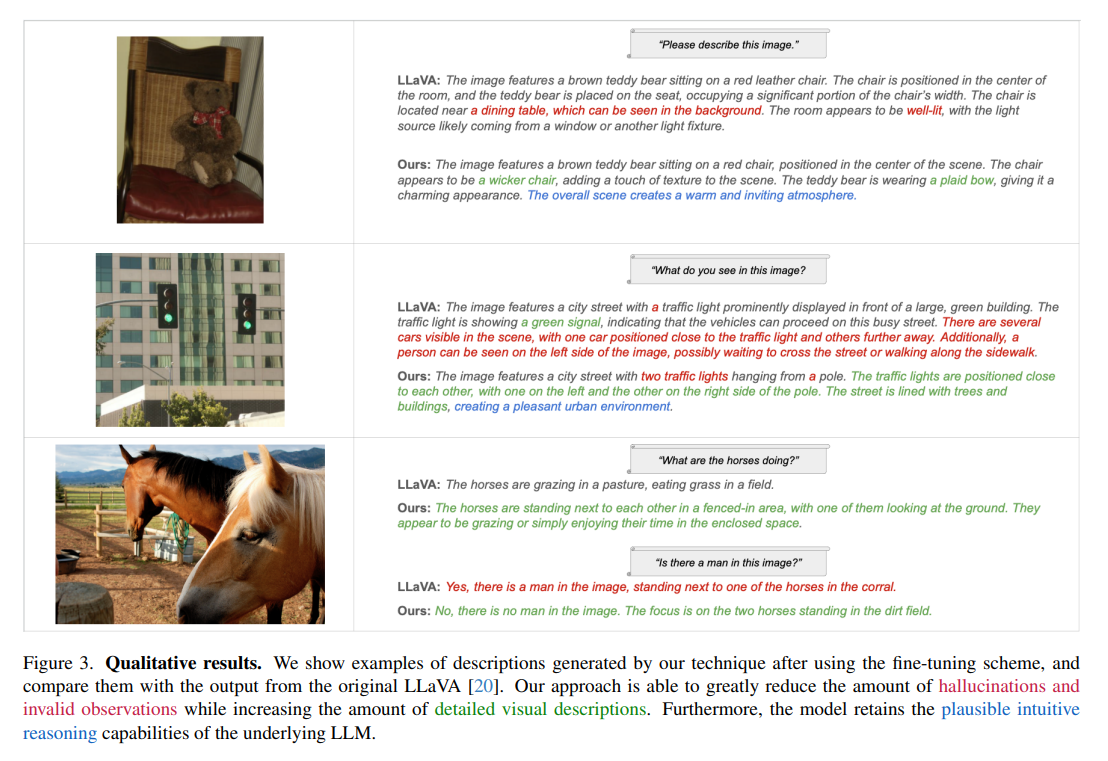
In conclusion, ViGoR presents a significant advancement in improving LVLMs’ visual grounding accuracy and retains the inherent creative and intuitive reasoning capabilities of pre-trained models. This development heralds a more reliable interpretation and generation of text about images, moving closer to models that understand and describe visual content with high fidelity and detail.
Check out the Paper. All credit for this research goes to the researchers of this project. Also, don’t forget to follow us on Twitter and Google News. Join our 37k+ ML SubReddit, 41k+ Facebook Community, Discord Channel, and LinkedIn Group.
If you like our work, you will love our newsletter..
Don’t Forget to join our Telegram Channel
The post Researchers from UT Austin and AWS AI Introduce a Novel AI Framework ‘ViGoR’ that Utilizes Fine-Grained Reward Modeling to Significantly Enhance the Visual Grounding of LVLMs over Pre-Trained Baselines appeared first on MarkTechPost.
#AIShorts #Applications #ArtificialIntelligence #ComputerVision #EditorsPick #Staff #TechNews #Technology #Uncategorized [Source: AI Techpark]