


Robotic manipulation has always presented a significant challenge in the automation and AI fields, particularly when it comes to tasks that require a high degree of dexterity. Traditional imitation learning methods, which rely on human demonstrations to teach robots complex tasks, have been limited by the necessity for extensive, high-quality demonstration data. Due to the intricacies involved, this requirement often translates into considerable human effort, especially for multi-finger dexterous manipulation tasks.

Against this backdrop, this paper introduces a novel framework, CyberDemo (Figure 2), which utilizes simulated human demonstrations for real-world robot manipulation tasks. This approach not only mitigates the need for physical hardware, thus allowing for remote and parallel data collection but also significantly enhances task performance through simulator-exclusive data augmentation techniques (shown in Figure 3). By leveraging these techniques, CyberDemo can generate a dataset that is orders of magnitude larger than what could feasibly be collected in real-world settings. This capability addresses one of the fundamental challenges in the field: the sim2real transfer, where policies trained in simulation are adapted for real-world application.
CyberDemo’s methodology begins with the collection of human demonstrations via teleoperation in a simulated environment using low-cost devices. This data is then enriched through extensive augmentation to include a wide array of visual and physical conditions not present during the initial data collection. This process is designed to improve the robustness of the trained policy against variations in the real world. The framework employs a curriculum learning strategy for policy training, starting with the augmented dataset and gradually introducing real-world demonstrations to fine-tune the policy. This approach ensures a smooth sim2real transition, addressing variations in lighting, object geometry, and initial pose without necessitating additional demonstrations.
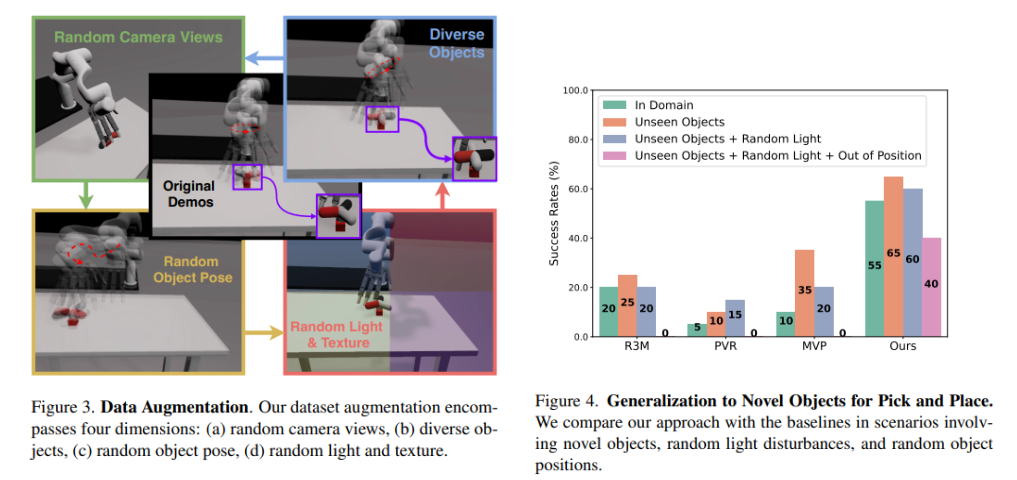
The effectiveness of CyberDemo is underscored by its performance (Figure 4) in various manipulation tasks. Compared to traditional methods, CyberDemo demonstrates a remarkable improvement in task success rates. Specifically, CyberDemo achieves a success rate that is 35% higher for quasi-static tasks such as pick and place and 20% higher for non-quasi-static tasks like rotating a valve when compared against pre-trained policies fine-tuned on real-world demonstrations. Furthermore, in tests involving unseen objects, CyberDemo’s ability to generalize is particularly noteworthy, with a success rate of 42.5% in rotating novel objects, a significant leap from the performance of conventional methods.
This method is evaluated against several baselines, including state-of-the-art vision pre-training models like PVR, MVP, and R3M, which have been previously employed for robotic manipulation tasks. PVR builds on MoCo-v2 with a ResNet50 backbone, MVP uses self-supervised learning from a Masked Autoencoder with a Vision Transformer backbone, and R3M combines time-contrastive learning, video-language alignment, and L1 regularization with a ResNet50 backbone. The success of CyberDemo against these well-established models highlights its efficiency and robustness and its ability to outperform models that have been fine-tuned on real-world demonstration datasets.
In conclusion, CyberDemo’s innovative approach, leveraging augmented simulation data, challenges the prevailing belief that real-world demonstrations are paramount for solving real-world problems. The empirical evidence presented through CyberDemo’s performance demonstrates the untapped potential of simulation data, enhanced through data augmentation, to surpass real-world data in terms of value for robotic manipulation tasks. While the need to design simulated environments for each task presents an additional layer of effort, reducing required human intervention for data collection and avoiding complex reward design processes offer substantial advantages. CyberDemo represents a significant step forward in the field of robotic manipulation, offering a scalable and efficient solution to the perennial challenges of sim2real transfer and policy generalization.
Check out the Paper and Project. All credit for this research goes to the researchers of this project. Also, don’t forget to follow us on Twitter and Google News. Join our 38k+ ML SubReddit, 41k+ Facebook Community, Discord Channel, and LinkedIn Group.
If you like our work, you will love our newsletter..
Don’t Forget to join our Telegram Channel
You may also like our FREE AI Courses….
The post Researchers from UCSD and USC Introduce CyberDemo: A Novel Artificial Intelligence Framework Designed for Robotic Imitation Learning from Visual Observations appeared first on MarkTechPost.
#AIPaperSummary #AIShorts #Applications #ArtificialIntelligence #EditorsPick #Staff #TechNews #Technology #Uncategorized [Source: AI Techpark]