


Large Language Models (LLMs) have recently extended their reach beyond traditional natural language processing, demonstrating significant potential in tasks requiring multimodal information. Their integration with video perception abilities is particularly noteworthy, a pivotal move in artificial intelligence. This research takes a giant leap in exploring LLMs’ capabilities in video grounding (VG), a critical task in video analysis that involves pinpointing specific video segments based on textual descriptions.
The core challenge in VG lies in the precision of temporal boundary localization. The task demands accurately identifying the start and end times of video segments based on given textual queries. While LLMs have shown promise in various domains, their effectiveness in accurately performing VG tasks still needs to be explored. This gap in research is what the study seeks to address, delving into the capabilities of LLMs in this nuanced task.
Traditional methods in VG have varied, from reinforcement learning techniques that adjust temporal windows to dense regression networks that estimate distances from video frames to the target segment. These methods, however, rely heavily on specialized training datasets tailored for VG, limiting their applicability in more generalized contexts. The novelty of this research lies in its departure from these conventional approaches, proposing a more versatile and comprehensive evaluation method.
The researcher from Tsinghua University introduced ‘LLM4VG’, a benchmark specifically designed to evaluate the performance of LLMs in VG tasks. This benchmark considers two primary strategies: the first involves video LLMs trained directly on text-video datasets (VidLLMs), and the second combines conventional LLMs with pretrained visual models. These graphical models convert video content into textual descriptions, bridging the visual-textual information gap. This dual approach allows for a thorough assessment of LLMs’ capabilities in understanding and processing video content.
A deeper dive into the methodology reveals the intricacies of the approach. In the first strategy, VidLLMs directly process video content and VG task instructions, outputting predictions based on their training on text-video pairs. The second strategy is more complex, involving LLMs and visual description models. These models generate textual descriptions of video content integrated with VG task instructions through carefully designed prompts. These prompts are tailored to effectively combine the instruction of VG with the given visual description, thus enabling the LLMs to process and understand the video content about the task.

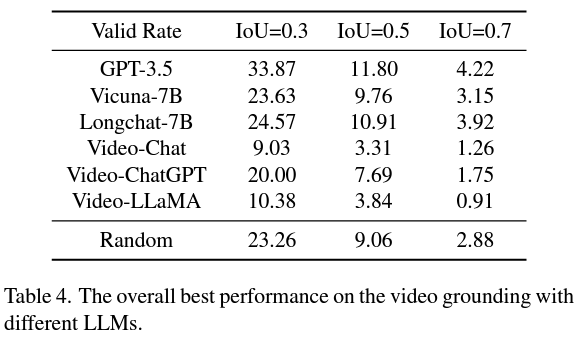
The performance evaluation of these strategies brought forth some notable results. It was observed that VidLLMs, despite their direct training on video content, still lag significantly in achieving satisfactory VG performance. This finding underscores the necessity of incorporating more time-related video tasks in their training for a performance boost. Conversely, combining LLMs with visual models showed preliminary abilities in VG tasks. This strategy outperformed VidLLMs, suggesting a promising direction for future research. However, the performance was primarily constrained by the limitations in the visual models and the design of the prompts. The study indicates that more refined graphical models, capable of generating detailed and accurate video descriptions, could substantially enhance LLMs’ VG performance.
In conclusion, the research presents a groundbreaking evaluation of LLMs in the context of VG tasks, emphasizing the need for more sophisticated approaches in model training and prompt design. While current VidLLMs need more temporal understanding, integrating LLMs with visual models opens up new possibilities, marking an important step forward in the field. The findings of this study not only shed light on the current state of LLMs in VG tasks but also pave the way for future advancements, potentially revolutionizing how video content is analyzed and understood.
Check out the Paper. All credit for this research goes to the researchers of this project. Also, don’t forget to join our 35k+ ML SubReddit, 41k+ Facebook Community, Discord Channel, LinkedIn Group, and Email Newsletter, where we share the latest AI research news, cool AI projects, and more.
If you like our work, you will love our newsletter..
The post Researchers from Tsinghua University Introduce LLM4VG: A Novel AI Benchmark for Evaluating LLMs on Video Grounding Tasks appeared first on MarkTechPost.
#AIShorts #Applications #ArtificialIntelligence #ComputerVision #EditorsPick #LanguageModel #LargeLanguageModel #MachineLearning #Staff #TechNews #Technology #Uncategorized [Source: AI Techpark]