
![]()

The deployment of large language models (LLMs) has become central to many applications, from synthetic data generation to fine-tuning models for specific tasks. With their vast capabilities, these models have opened new frontiers in research and application development. Yet, the adoption of LLMs has its challenges. The complexity of managing these models and the technical and financial barriers associated with their operation present significant challenges. This complexity often hampers the reproducibility of research findings and the sharing of methodologies, which are crucial for the progression of the field.
Researchers from the University of Pennsylvania, the University of Toronto, and the Vector Institute introduced DataDreamer. DataDreamer is a comprehensive solution designed to streamline the integration and utilization of LLMs across various tasks. Its development responds to the pressing need for a unified interface that simplifies complex LLM workflows, making them more accessible and manageable for researchers.
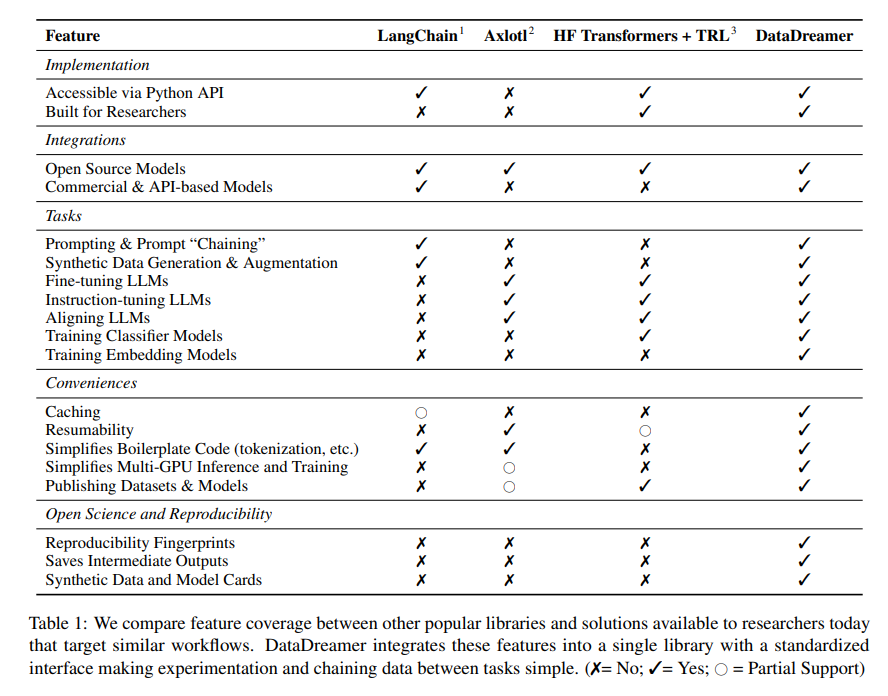
DataDreamer offers a suite of functionalities that significantly lower the barriers to effective LLM use. At its core, it provides a standardized interface that abstracts away the complexity of tasks such as synthetic data generation, model fine-tuning, and the application of optimization techniques. This simplification is not just about making the researcher’s job easier; it’s about enhancing the efficiency and reproducibility of their work. By offering a cohesive framework for managing LLM workflows, DataDreamer encourages the adoption of best practices in open science, ensuring that research outputs are innovative, verifiable, and extendable by the wider scientific community.
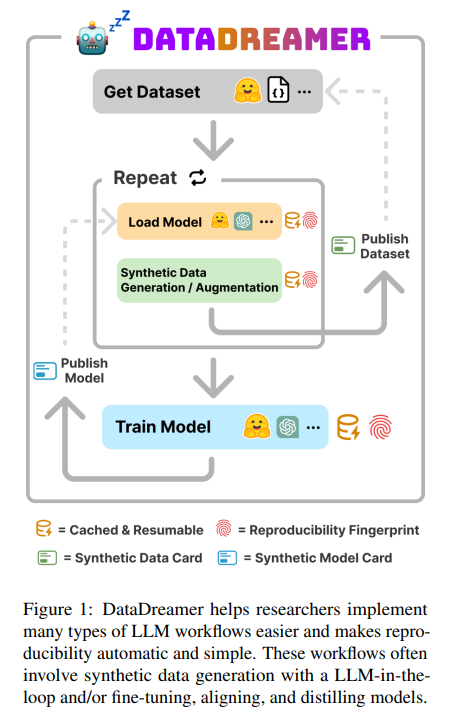
The methodology behind DataDreamer integrates features that address common challenges in LLM research, such as the need for synthetic data generation and the fine-tuning of models. For instance, DataDreamer facilitates the generation of synthetic datasets, which is increasingly vital as researchers seek to augment their data resources. It streamlines the fine-tuning process, allowing for customizing models to specific tasks without extensive coding or deep technical expertise. This approach saves time and opens up new possibilities for research and application development.
DataDreamer has demonstrated significant improvements in the speed and quality of research outputs. Researchers can now generate synthetic data fine-tune models, and apply optimization techniques with unprecedented ease, leading to more robust and reliable findings. The tool’s impact extends beyond individual projects, fostering a culture of openness and collaboration in the NLP research community.
In conclusion, DataDreamer addresses critical challenges that have hindered research and application development progress, offering a practical solution that enhances the accessibility, efficiency, and reproducibility of LLM workflows. Its features and user-friendly interface make it an indispensable tool for researchers, enabling them to push the boundaries of what is possible in NLP. DataDreamer will be crucial in shaping its future, driving the quest for knowledge, and developing innovative applications. With DataDreamer, researchers have a powerful ally, ready to tackle the complexities of large language models and unlock new possibilities.
Check out the Paper and Github. All credit for this research goes to the researchers of this project. Also, don’t forget to follow us on Twitter and Google News. Join our 38k+ ML SubReddit, 41k+ Facebook Community, Discord Channel, and LinkedIn Group.
If you like our work, you will love our newsletter..
Don’t Forget to join our Telegram Channel
You may also like our FREE AI Courses….
The post Researchers from the University of Pennsylvania and Vector Institute Introduce DataDreamer: An Open-Source Python Library that Allows Researchers to Write Simple Code to Implement Powerful LLM Workflow appeared first on MarkTechPost.
#AIShorts #Applications #ArtificialIntelligence #LanguageModel #LargeLanguageModel #TechNews #Technology #Uncategorized [Source: AI Techpark]