


Transformers have found widespread application in diverse tasks spanning text classification, map construction, object detection, point cloud analysis, and audio spectrogram recognition. Their versatility extends to multimodal tasks, exemplified by CLIP’s use of image-text pairs for superior image recognition. This underscores transformers’ efficacy in establishing universal sequence-to-sequence modeling, creating embeddings that unify data representation across multiple modalities.
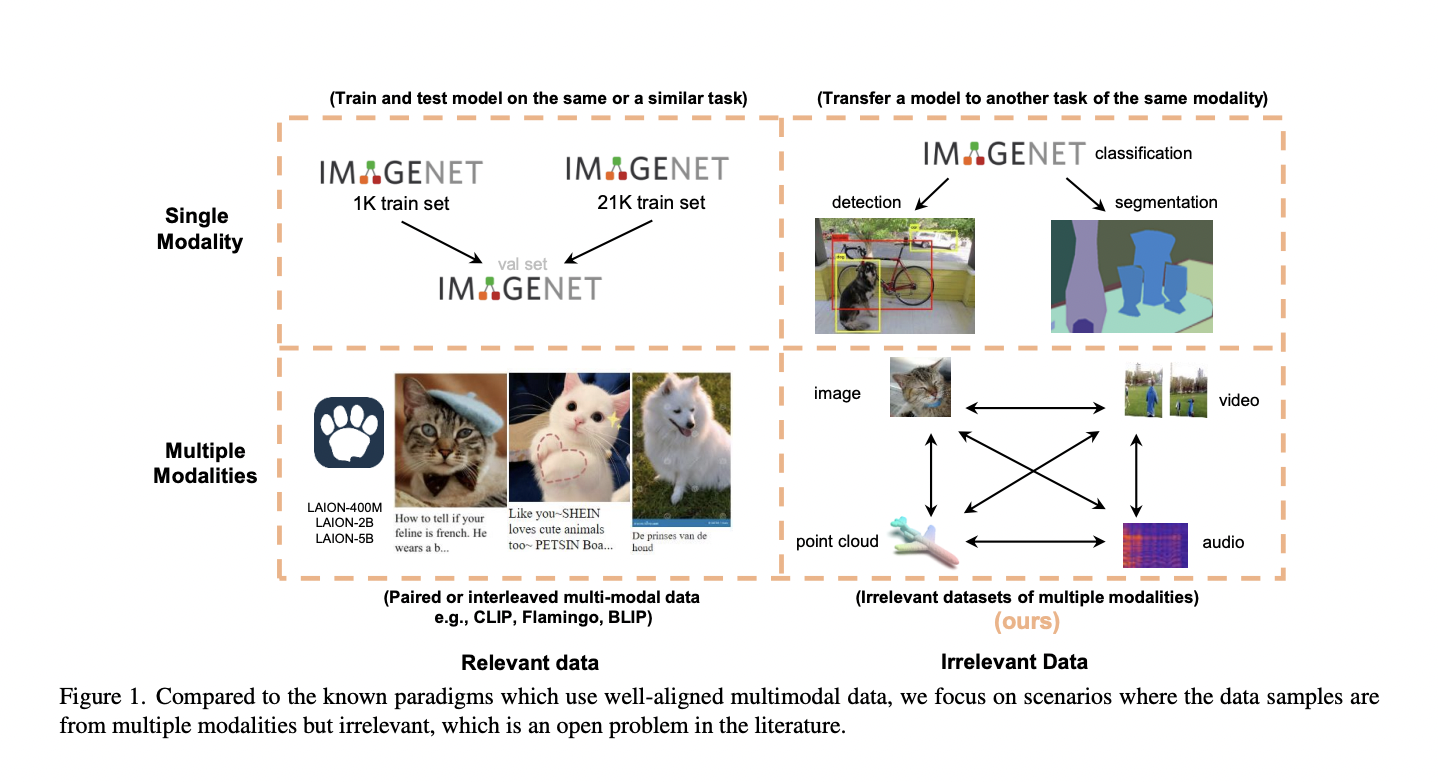
CLIP illustrates a notable methodology, leveraging data from one modality (text) to enhance a model’s performance in another (images). However, the requirement for relevant paired data samples is a significant limitation often overlooked in research. For instance, while training with image-audio pairs could improve image recognition, the efficacy of a pure audio dataset in enhancing ImageNet classification without meaningful connections between audio and image samples remains to be determined.
Researchers from The Chinese University of Hong Kong and Tencent AI Lab have proposed the Multimodal Pathway Transformer (M2PT). The researchers seek to enhance transformers designed for specific modalities, such as ImageNet, by incorporating irrelevant data from unrelated modalities like audio or point cloud datasets. This approach distinguishes itself from others that rely on paired or interleaved data from different modalities. The goal is to demonstrate improvement in model performance by connecting transformers of disparate modalities, where the data samples from the target modality are intentionally irrelevant to those of the auxiliary modalities.
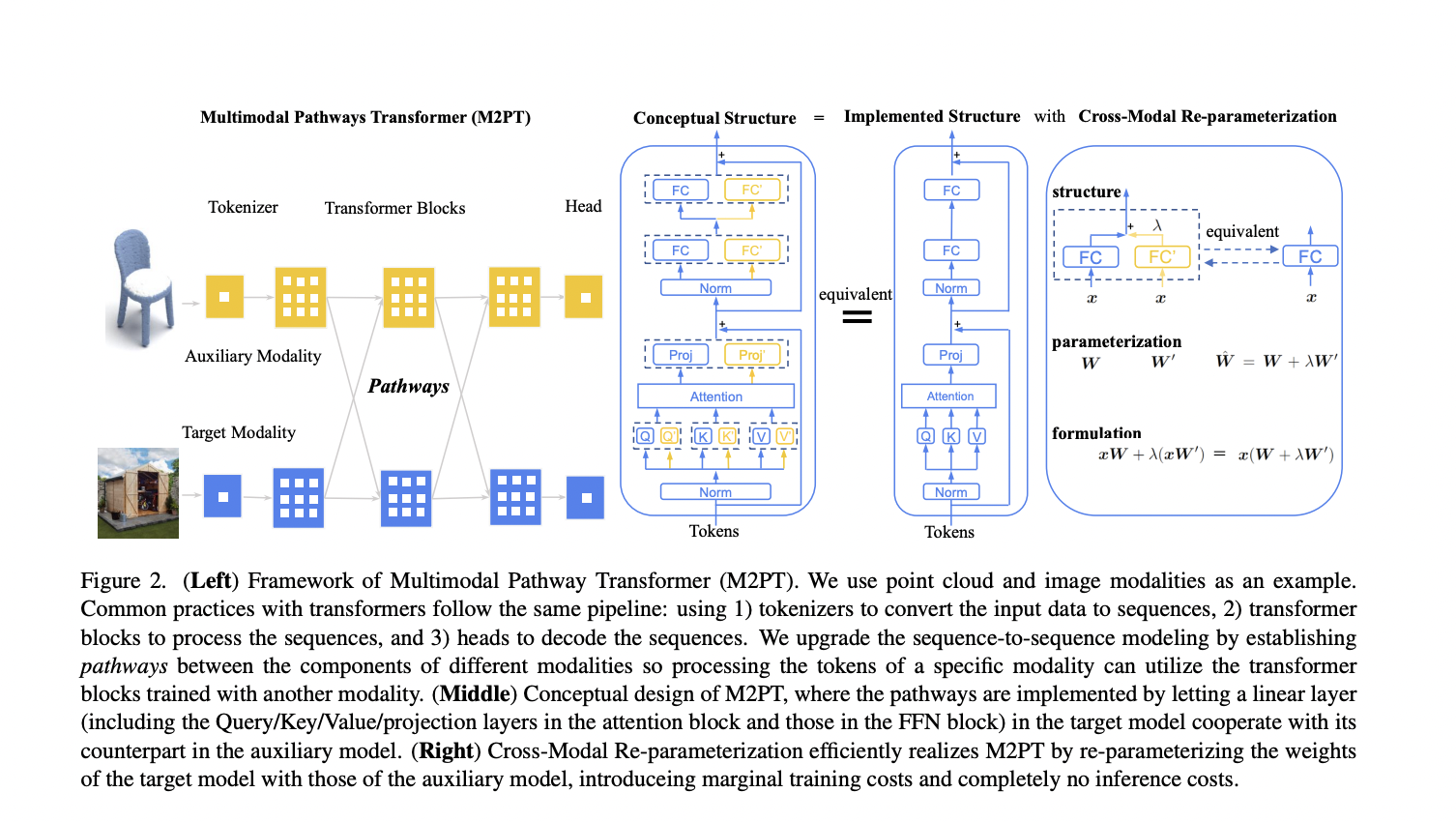
M2PT connects components of a target modality model with an auxiliary model through pathways. This enables the processing of target modality data by both models, utilizing the transformer’s universal sequence-to-sequence modeling capabilities from two modalities. The approach involves a modality-specific tokenizer and task-specific head, and it incorporates auxiliary model transformer blocks using cross-module re-parameterization, allowing the exploitation of additional weights without inference costs. By incorporating irrelevant data from other modalities, their method demonstrates substantial and consistent performance improvements across image, point cloud, video, and audio recognition tasks.
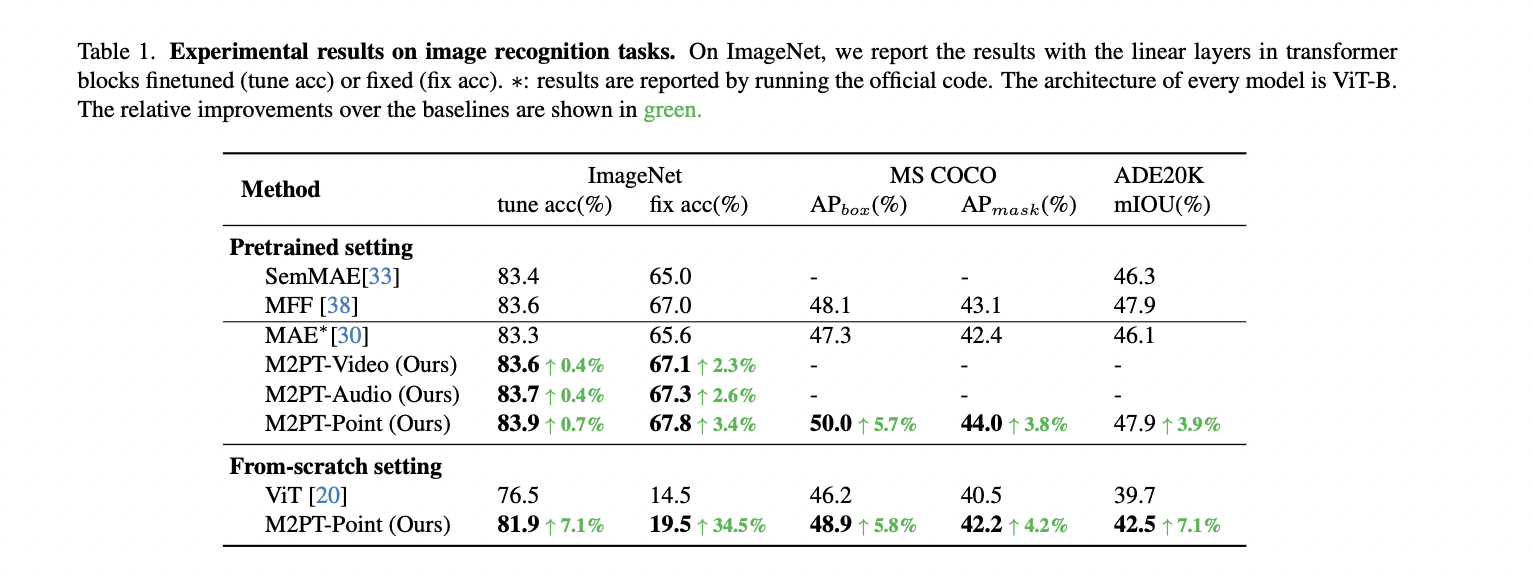
The researchers present experimental findings in image recognition, employing the ViT-B architecture across models. M2PT-Video, M2PT-Audio, and M2PT-Point are compared with SemMAE, MFF, and MAE. Results on ImageNet, MS COCO, and ADE20K demonstrate accuracy and task performance improvements. M2PT-Point notably excels, showcasing substantial enhancements in APbox, APmask, and mIOU metrics compared to baseline models.
In conclusion, the paper introduces the Multimodal Pathway to enhance transformer performance on a specific modality by incorporating irrelevant data from other modalities. The researchers present Cross-Modal Re-parameterization as a tangible implementation, enabling the utilization of auxiliary weights without incurring inference costs. Experimental results consistently show substantial performance improvements across image, point cloud, video, and audio recognition tasks, emphasizing the efficacy of leveraging irrelevant data from diverse modalities in transformer-based models.
Check out the Paper and Github. All credit for this research goes to the researchers of this project. Also, don’t forget to follow us on Twitter. Join our 36k+ ML SubReddit, 41k+ Facebook Community, Discord Channel, and LinkedIn Group.
If you like our work, you will love our newsletter..
Don’t Forget to join our Telegram Channel
The post Researchers from the Chinese University of Hong Kong and Tencent AI Lab Propose a Multimodal Pathway to Improve Transformers with Irrelevant Data from Other Modalities appeared first on MarkTechPost.
#AIShorts #Applications #ArtificialIntelligence #ComputerVision #EditorsPick #Staff #TechNews #Technology #Uncategorized [Source: AI Techpark]